 世界模型赋能自动驾驶视觉定位
世界模型赋能自动驾驶视觉定位




点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Haicheng Liao等
编辑 | 自动驾驶之心
在自动驾驶的交互场景中,最尴尬的时刻莫过于此:
乘客指着前方复杂的路口说:“跟着那辆SUV”。自动驾驶系统看着眼前三辆长得差不多的车,内心OS:“哪辆?是左边那辆?还是正在变道那辆?”
现有的自动驾驶视觉定位(Visual Grounding)模型,大多像是一个“只会看图说话”的愣头青。它们盯着当前的这一帧画面,试图从像素里找答案。一旦指令模糊,或者目标被遮挡,它们就很容易“指鹿为马”,甚至引发错误推理。
论文题目: Think Before You Drive: World Model-Inspired Multimodal Grounding for Autonomous Vehicles
论文链接:https://arxiv.org/abs/2512.03454
人类司机为什么不会弄错?因为我们会“预判”。
当我们听到指令时,大脑里会瞬间推演未来的画面:左边那辆车马上要转弯了,不符合“跟着”的语境;只有中间那辆车在加速直行,才是最可能的意图。
“在行动之前,先思考未来”。
受此启发,来自[澳门大学]的研究团队提出了全新的框架 ThinkDeeper。这是首个将世界模型(World Model)引入自动驾驶视觉定位的研究。这项工作不仅刷新多项榜单的SOTA,还构建了一个大规模的视觉接地数据集DrivePilot。

01. 困局:自动驾驶视角的“盲区”
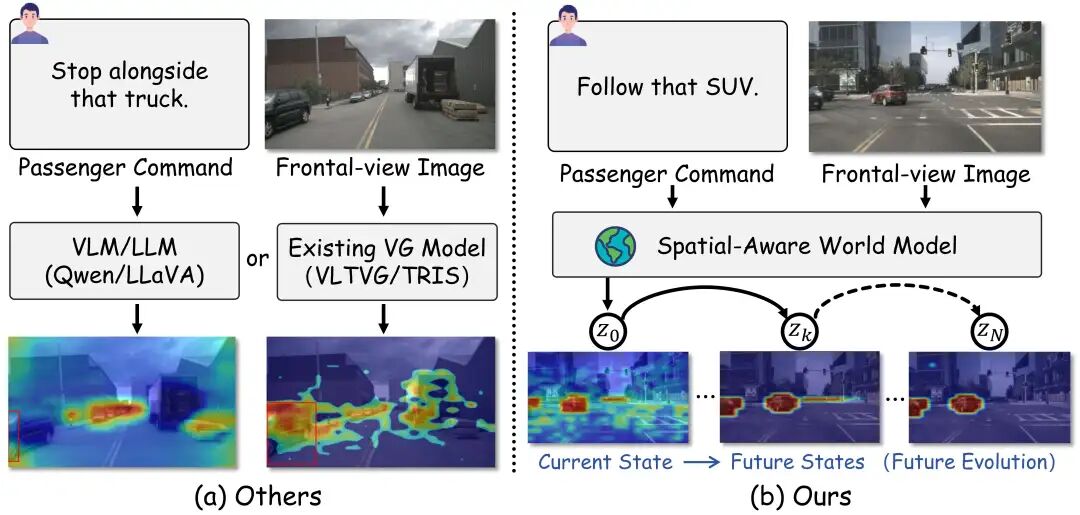
尽管视觉定位(VG)和多模态大模型(VLM)在学术界风生水起,但一旦把它们应用到现实复杂的自动驾驶场景中,往往会暴露出的三大致命软肋:
空间上的“近视眼”: 普通模型看世界是2D的,严重缺乏3D深度感知。在它们眼里,路边广告牌上的汽车和马路上的真车可能没啥区别。这种“近视眼”让它们根本分不清谁是无关紧要的“背景板”,谁是近在咫尺的“交互对象”。

时间上的“短视症”:驾驶是动态的博弈,指令往往指向未来(如“等前车转弯后,跟上去”)。但现有模型只能盯着当前的一帧画面“看图说话”,缺乏对未来状态的推演能力。这种“走一步看一步”的策略,根本无法从根源上消除指令的歧义。
落地上的“虚胖”: 这也是最现实的阻碍。像GPT或Qwen-VL这样的通用大模型虽然聪明,但参数量动辄百亿,推理延迟极高。把它们搬上算力受限的车载芯片,根本跑不动。而在毫秒必争的自动驾驶中,慢,就意味着危险。
如果自动驾驶汽车不能像人类司机一样拥有“时空前瞻性”,那么所谓的人机共驾就永远停留在“听口令做动作”的低级阶段。
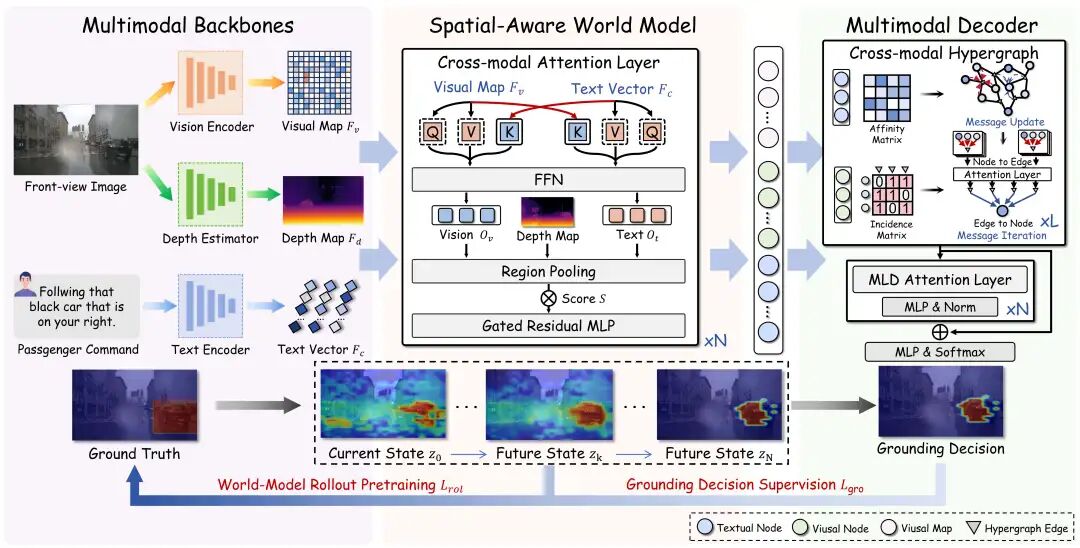
02. 破局:拒绝“走一步看一步”,让AV学会“脑补”未来
ThinkDeeper的核心思想非常直观:Think Before You Drive(三思而后行)。
它引入了一个空间感知世界模型(Spatial-Aware World Model, SA-WM)。这个模型不只是简单地处理当前的图像,它更像是给自动驾驶系统装上了一个会思考的“大脑”, 让它在做决策前,先完成两件极具“人类智慧”的事情:
第一步:去粗取精(Distill), 给视野“降噪”:ThinkDeeper会结合乘客的语音指令,从当前纷繁复杂的街景中提取出关键的“潜变量状态(Latent State)”。比如当你提到“公交车”时,它会自动过滤掉路边的树木、行人和小轿车,只保留与指令相关的核心要素。它提取的不再是死板的像素,而是与任务强相关的关键潜变量,就像人类司机在开车时,眼中只有路况,而自动忽略路边广告牌一样。
第二步:推演未来(Rollout),在脑中“放电影” 。基于提取出的关键信息,SA-WM会快速在潜意识里快速“播放”未来的画面:预测这些关键物体下一秒会在哪里、会怎么动。
通过这种“未来状态链”(Chain of Future States)的推演,ThinkDeeper获得了一个上帝视角般的前瞻性线索。
最后,再配合一个超图解码器(Hypergraph Decoder),将这些时空线索与视觉、深度信息融合,ThinkDeeper就能在极度模糊的指令下,精准锁定乘客的想去的地方。
03. 数据增强:用大模型“重塑”数据,打造DrivePilot

除了模型创新,该团队还发布了DrivePilot数据集。在自动驾驶领域,数据就是燃料。但传统的公开数据集往往面临“营养不良”的窘境:场景单一、标注只有冷冰冰的物体框,缺乏深层的语意理解。为了给AI提供最优质的“教材”,团队利用Qwen2-VL大模型的强大场景理解能力,配合RAG(检索增强生成)和CoT(思维链)技术,构建了一套自动化的高质量数据生产流水线,发布了DrivePilot数据集。
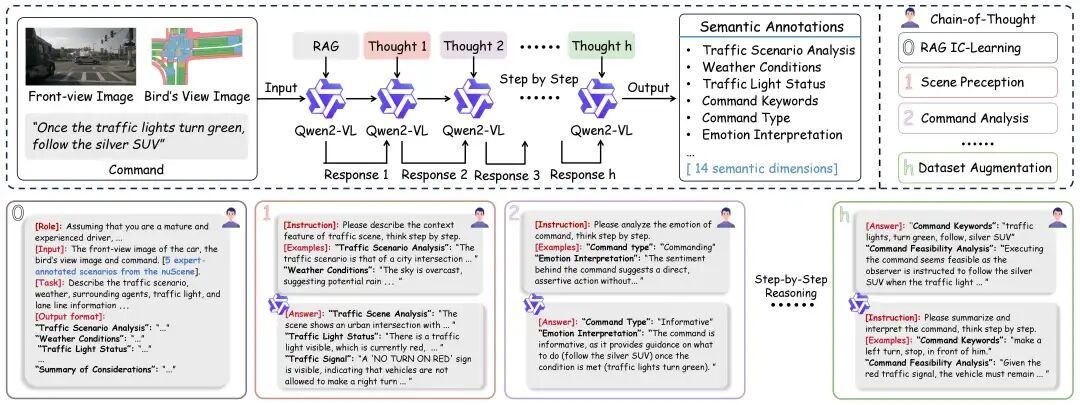
这不仅仅是数据量的堆砌,更是维度的升维。DrivePilot包含了数万个复杂场景,提供了多达14个维度的详尽语义标注,从天气变化到情绪上下文,从交通规则到驾驶意图。它让数据从枯燥的“看图画框”,进化为了一本本图文并茂、逻辑严密的“驾驶教科书”。
04. 实验结果
在Talk2Car等六大主流基准测试中,ThinkDeeper展现了令人印象深刻的表现:
登顶Talk2Car榜首:在这一最具挑战性的自动驾驶指令定位基准上,超越了所有现有方案。
专治“疑难杂症”:在DrivePilot的长文本(Long-text)、多智能体(Multi-agent)和模糊指令(Ambiguity)等Corner Case场景中,ThinkDeeper的优势尤为明显,大幅领先MiniGPT-v2/Qwen2.5-VL等通用大模型。
准确且高效:ThinkDeeper在保持高性能的同时,推理速度达到了39ms (A40 GPU),完全满足车载芯片的实时性要求:既跑得过SOTA,也跑得动实车。
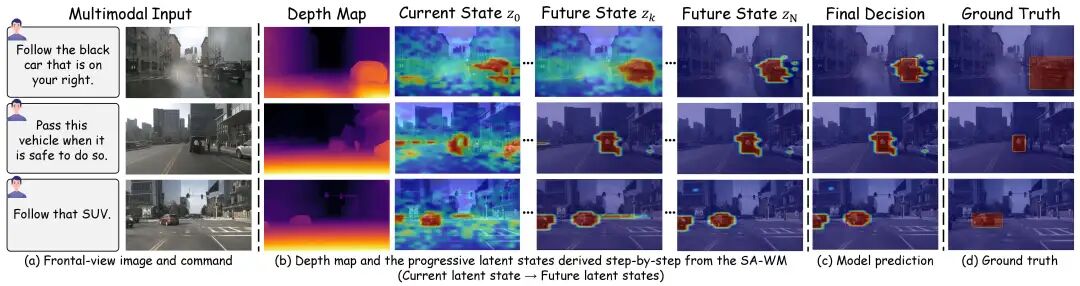
05.结语
ThinkDeeper的出现,证明了世界模型在自动驾驶感知和人机交互理解层面的巨大潜力。它让自动驾驶汽车不再是被动接收指令的机器,而变成了一个懂得观察环境、懂得推演未来、懂得理解意图的智能体。
当自动驾驶汽车学会了“Think Before Drive”,我们离真正放心地把方向盘交给它的那天,又近了一步。
自动驾驶之心
端到端与VLA自动驾驶小班课!

添加助理咨询课程!

知识星球交流社区


















 2865
2865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









