



点击下方卡片,关注“大模型之心Tech”公众号
本文只做学术分享,如有侵权,联系删文
在AI重塑各行各业的浪潮中,代码智能领域正经历从“辅助工具”到“自主开发者”的革命性转变。从GitHub Copilot帮我们补全代码,到Cursor编辑器支持对话式编程,再到字节Trae、Anthropic Claude Code等工具融入研发流程,大语言模型(LLMs)已彻底改变软件开发生态——曾经需要几小时编写的函数,如今通过自然语言描述就能生成,部分模型在HumanEval等基准测试上的成功率更是突破95%,远超早期规则系统的单位数水平。
但代码智能远不止“生成代码”这么简单:如何让模型理解百万行代码仓库的跨文件依赖?如何保证生成代码的安全性与效率?如何构建能自主完成“需求分析-开发-测试-部署”全流程的软件工程智能体?这些问题的答案,藏在近期由北航、阿里、字节跳动、华为云、腾讯、香港科技大学(广州)等28家机构联合发布的304页重磅综述中。这篇论文不仅系统梳理了代码大模型的技术演进,更构建了从基础模型到智能体应用的完整技术体系,堪称代码智能领域的“百科全书”。
论文链接:https://arxiv.org/abs/2511.18538
更多大模型前沿进展,欢迎加入『大模型之心tech知识星球』!
代码智能的60年演进
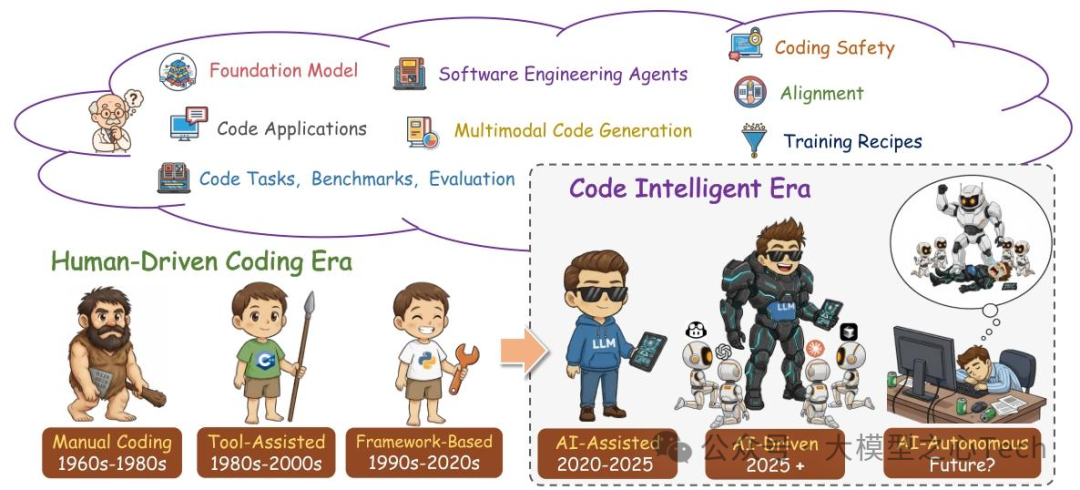
要理解代码智能的技术脉络,首先得回到它的进化史。论文通过一张时间轴,清晰划分了编程开发的六个阶段,每一次跨越都对应着技术范式的革新:
1960s-1980s(手动编码时代):程序员完全依赖手工编写代码,无工具辅助,效率极低;
1980s-2000s(工具辅助时代):编译器、IDE(如Visual Studio)出现,支持语法检查、简单补全,但核心逻辑仍需人工实现;
1990s-2020s(框架驱动时代):Java Spring、Python Django等开发框架普及,降低重复编码,但“自然语言到代码”的鸿沟依然存在;
2020-2025(AI辅助时代):代码大模型崛起,GitHub Copilot、Code LLaMA等工具成为开发者标配,实现“自然语言描述→代码生成”的跨越;
2025+(AI自主时代):软件工程智能体(SWE Agents)出现,能自主完成需求分析、多文件开发、测试部署,甚至修复生产环境漏洞;
未来?(代码智能时代):多模态、跨领域代码智能体将成为主流,融合视觉(UI设计图)、文本(需求文档)、执行反馈(测试结果),实现端到端软件开发。
这一演进的核心驱动力,正是从“规则系统”到“Transformer大模型”的技术跃迁。早期模型(如JavaBERT、C-BERT)仅能处理单一语言的简单理解任务,而如今的Code LLaMA、DeepSeek-Coder等模型,已能支持数十种编程语言,甚至理解百万级token的代码仓库上下文——这种能力的飞跃,背后是数据、模型、训练技术的全方位突破。
代码基础模型
论文的核心章节之一,是对代码基础模型的系统拆解。目前主流模型可分为两类:通用大语言模型(General LLMs) 和代码专用大语言模型(Code-Specialized LLMs),二者各有优势,又在技术上相互融合。
通用大语言模型
以GPT-4、Claude、LLaMA为代表的通用模型,并非专为代码设计,却因训练数据中包含大量代码(如GitHub开源仓库),意外具备了不错的编码能力。比如GPT-4能生成多语言代码、修复复杂bug,甚至理解代码的业务逻辑——但它的短板也很明显:
专业性不足:生成的代码可能满足语法正确,但不符合行业规范(如未处理异常、内存泄漏);
安全性风险:约45%的生成代码存在已知漏洞(如SQL注入、缓冲区溢出),且模型规模增大后这一问题未明显改善;
长上下文乏力:面对跨文件依赖(如调用其他模块的函数),即使扩展上下文窗口,性能也会因“中间信息遗忘”而下降。
这些局限性,催生了代码专用模型的爆发。
代码专用模型
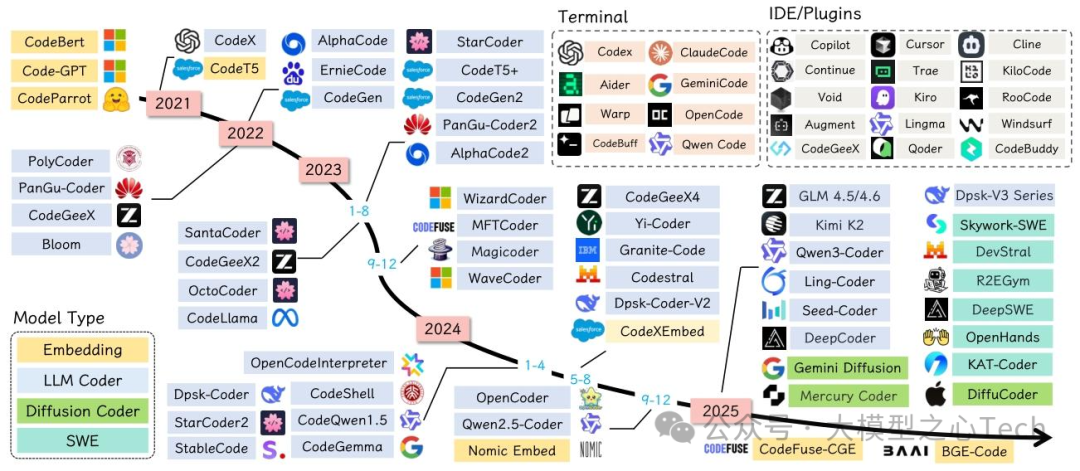
代码专用模型通过“数据聚焦+架构优化+任务微调”,在编码任务上实现对通用模型的超越。论文重点分析了StarCoder、Code LLaMA、DeepSeek-Coder、QwenCoder等主流模型,总结出它们的三大核心特征:
(1)数据:从“量”到“质”的转变
早期代码模型依赖GitHub raw数据,而现在的数据集更注重“质量、合规性、去污染”:
The Stack系列:BigCode联盟推出的The Stack v2,包含32.1TB数据、600+编程语言,还支持开发者“opt-out”(要求移除自己的代码),解决许可证合规问题;
StarCoderData:在The Stack基础上进一步去污染,过滤掉基准测试数据(如HumanEval),避免模型“作弊”,同时加入GitHub issues、commit信息,提升代码理解能力;
领域细分数据:如CodeParrot专注Python,CodeGeeX4支持100+语言,满足不同场景需求。
(2)架构:从“ dense ”到“稀疏高效”的进化
代码模型的架构创新,围绕“长上下文+高效推理”展开:
Dense模型:如Code LLaMA基于LLaMA2,通过扩展RoPE基础周期(从104到10⁶),支持16k训练上下文,甚至能处理100k token的长代码;
MoE(混合专家)模型:如Qwen3-Coder-480B-A35B,总参数480B,但仅激活35B(160个专家中选8个),兼顾能力与效率;DeepSeek-Coder-V2通过MoE架构,支持338种语言,236B总参数却仅需21B激活参数;
混合架构:如Jamba融合Transformer与Mamba层,Jamba-MoE在长上下文代码理解上实现更高吞吐量。
(3)训练任务:不止“下一个token预测”
代码的特殊性(可执行、有结构),让训练任务超越了传统的语言建模:
Fill-in-the-Middle(FIM):让模型预测代码中间缺失片段(如函数内的逻辑),而非仅从左到右生成,Code LLaMA、StarCoder均采用这一任务,适配IDE中的“光标补全”场景;
多token预测(MTP):一次预测多个连续token,提升生成效率,同时更好捕捉代码块间的依赖;
扩散式生成:如DiffuCoder通过迭代去噪生成代码,相比自回归模型,生成结果更具多样性,且支持并行计算。
代码任务与评估
代码智能的价值,最终要通过任务落地体现。论文将代码任务分为三个粒度,每个粒度都有对应的基准测试与评估方法,构成了完整的“能力评估体系”。
语句/函数/类级任务:代码智能的“基础功”
这是最基础的任务类型,对应日常编码中的“片段级”需求:
代码补全与FIM:如补全函数内的循环逻辑、填充类中的方法实现,基准测试有CodeXGLUE、HumanEval-Infill,评估指标关注“语法正确性”与“测试通过率”;
代码生成:从自然语言生成完整函数(如“写一个Python排序函数”),主流基准是HumanEval(164个Python任务)、MBPP(974个任务),进阶版HumanEval+通过更多测试用例(80倍于原版本),暴露模型的隐藏错误;
代码修复与编辑:修复bug(如语法错误、逻辑错误)、重构代码(如提取重复逻辑为函数),基准测试如DebugBench(4.2k调试任务)、Aider的重构基准(89个大型方法重构),评估时需同时关注“修复成功率”与“代码可读性”;
代码翻译:将代码从一种语言转译为另一种(如Java转Python),难点在于保持功能等价,而非仅语法转换,基准测试如MultiPL-E(18种语言)、BabelCode(跨语言功能验证)。
仓库级任务:代码智能的“进阶挑战”
真实软件开发中,代码不是孤立的片段,而是跨文件、有依赖的仓库级项目。论文指出,仓库级任务是当前代码智能的核心难点:
多文件生成与补全:如生成调用其他模块函数的代码,需理解项目结构与依赖关系,基准测试RepoBench涵盖Python/Java仓库,评估“跨文件引用正确率”;
提交信息生成:从代码变更(diff)生成简洁的commit信息(如“修复登录接口的SQL注入漏洞”),基准CommitBench包含1.6M commit-diff对,评估指标用ROUGE-L、BLEU;
软件工程任务:如修复GitHub issues、实现新功能,SWE-bench系列是核心基准——SWE-bench Verified包含500个人工筛选的issues,要求模型生成补丁并通过单元测试,目前最先进的模型(如Claude 4.5)通过率约60%,仍有较大提升空间。
智能体系统任务:代码智能的“终极形态”
当代码模型结合工具、具备自主决策能力,就进化为“代码智能体”,能处理更复杂的工程任务:
工具使用:调用API、数据库、版本控制工具(如Git),基准测试ToolBench、API-Bank评估“工具选择正确性”与“参数传递准确性”;
网页与GUI交互:如通过浏览器搜索API文档、操作桌面软件(如Excel),基准WebArena、Mind2Web模拟真实网页环境,评估“任务完成率”(如“在电商网站下单”);
终端操作:通过命令行完成系统级任务(如编译Linux内核、部署服务器),Terminal-Bench是首个此类基准,要求模型理解shell命令、处理依赖冲突,目前即使顶级模型成功率也不足30%,是未来的重要方向。
而评估这些任务,不能只看“是否生成代码”,更要关注“代码是否能用”:论文提出,基于执行的指标(如Pass@k,即k次尝试中至少一次通过测试)已成为主流,同时LLM-as-a-Judge(用更强模型评估代码质量)也被广泛采用,如ICE-Score通过结构化评分准则,从“正确性、效率、可读性”多维度打分。
对齐技术——让代码模型“懂需求、守规矩”
训练出强大的代码模型只是第一步,更重要的是让它“对齐人类需求”——生成的代码不仅正确,还要安全、高效、符合开发规范。论文将对齐技术分为两类:监督微调(SFT)与强化学习(RL)。
1. 监督微调(SFT):给模型“立规矩”
SFT通过“指令-代码”配对数据,让模型学习“按人类要求做事”,核心在于数据质量与任务设计:
单轮SFT:针对简单任务(如生成函数、修复小bug),数据来自GitHub issues、Stack Overflow问答,需过滤重复、低质量样本,如CodeAlpaca通过“自指令”(用大模型生成指令数据)提升数据多样性;
多轮SFT:针对复杂任务(如多文件开发),数据包含“需求→代码→反馈→修改”的多轮交互,如AIEV-Instruct设置“提问者-程序员”双智能体,通过错误反馈迭代优化代码;
仓库级SFT:专门处理跨文件任务,数据需包含完整仓库上下文(如依赖关系、项目结构),如SWE-Dev数据集包含14k训练样本,覆盖“需求分析→代码实现→测试编写”全流程。
2. 强化学习(RL):让模型“越用越好”
SFT依赖标注数据,而RL能通过反馈信号(如测试结果、人类评价)持续优化模型,是对齐的关键技术:
RLHF(基于人类反馈的RL):先训练奖励模型(RM)学习人类偏好(如“哪个代码更简洁”),再用PPO算法优化生成模型,CodeMentor通过RLHF提升代码审查建议的实用性;
RLAIF(基于AI反馈的RL):用AI替代人类生成反馈(如用GPT-4评估代码安全性),解决人类标注成本高的问题,Skywork-OR1通过RLAIF,在SWE-bench上实现63%的修复成功率;
RLVR(带可验证奖励的RL):利用代码的“可执行性”,以“测试是否通过”“编译器是否报错”作为确定性奖励,无需人工标注,DeepCoder通过RLVR,在LiveCodeBench上匹配了34B参数模型的性能,而自身仅14B参数。
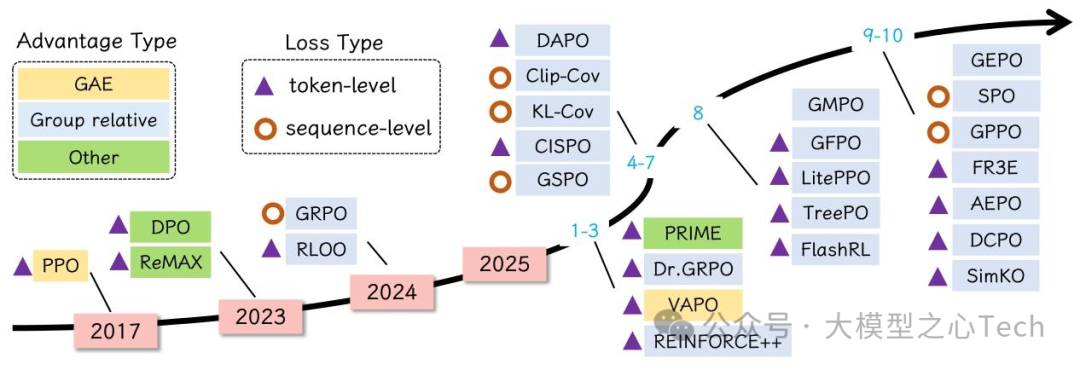
论文特别强调,RL并非孤立于SFT:通常先通过SFT给模型“打基础”,再用RL优化细节,二者结合才能实现最佳效果。
软件工程智能体(SWE Agents)
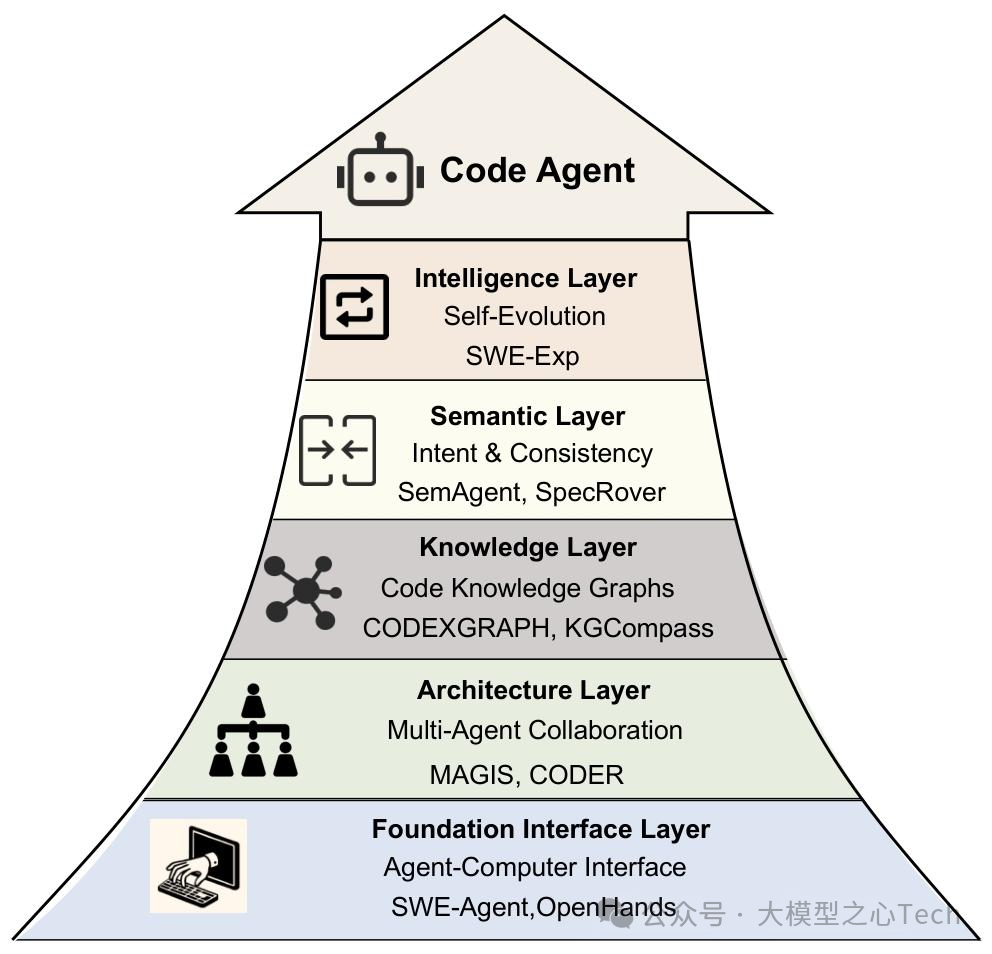
如果说代码模型是“智能螺丝刀”,那软件工程智能体就是“能自主完成装修的工人”——它整合代码模型、工具、记忆,能跨越软件开发生命周期,完成复杂工程任务。 论文将SWE Agents的应用场景分为四个阶段,每个阶段都有代表性框架:
1. 需求工程:理解“要做什么”
需求获取:如Elicitron通过模拟用户交互,挖掘潜在需求(如“用户在支付页面可能需要优惠券输入框”);
需求建模:如PrototypeFlow将文本需求转化为UI原型(如“生成电商商品详情页的HTML代码”),甚至能根据需求修改现有设计。
2. 软件开发:实现“怎么做”
代码生成与修复:如ChatDev模拟“CEO-产品经理-开发者-测试”团队,通过多智能体协作生成完整项目;MetaGPT通过“需求→PRD→架构设计→代码”的流程化分工,提升生成代码的完整性;
代码审查:如CodeAgent包含“审查者智能体”,自动检测代码中的漏洞、不符合规范的写法(如未注释的复杂逻辑),甚至能生成修改建议。
3. 软件测试:验证“做得对不对”
单元测试生成:如ChatUniTest通过“理解函数功能→生成测试用例→执行验证”的循环,生成高覆盖率测试代码;
模糊测试:如AutoSafeCoder通过多智能体协作,生成恶意输入(如超长字符串、特殊字符),检测软件的 robustness,已发现58个真实安全漏洞。
4. 软件维护:解决“运行中的问题”
日志分析:如LogRESP-Agent通过“日志解析→异常定位→根因分析”,自动识别生产环境的bug(如“数据库连接超时”);
反编译与修复:如LLM4Decompile将二进制文件(如.exe)反编译为可读代码,再修复其中的漏洞,适用于 legacy系统维护;
CI/CD集成:如AutoDev将智能体嵌入CI/CD pipeline,自动检测代码提交中的问题(如编译错误),甚至能自动回滚错误部署。
论文指出,SWE Agents的核心优势在于“协作”与“记忆”:多智能体分工解决复杂任务,而长期记忆能记住项目历史(如“之前修复过类似bug”),避免重复劳动。目前最先进的SWE Agents(如Qwen3-Coder-480B)已能处理1M token的代码仓库,在部分场景下效率达到人类初级开发者的2倍。
未来趋势:代码智能将走向何方?
在梳理完技术现状后,论文给出了三个核心趋势,指明了未来3-5年的研究方向:
1. 从“通用”到“专用”:垂直领域深度优化
通用代码模型的“广度”已足够,但“深度”仍不足。未来会出现更多垂直领域专用模型,如“嵌入式代码模型”(优化内存占用)、“金融代码模型”(符合金融合规)、“AI框架代码模型”(擅长PyTorch/TensorFlow代码生成)——这些模型通过领域数据微调,在特定场景下将远超通用模型。
2. 智能体自主化:从“辅助”到“自主决策”
当前SWE Agents仍需人类干预(如确认需求、审批代码),未来将走向更高自主性:能自主识别生产环境漏洞、制定修复方案、协调多团队资源(如联系运维调整服务器配置),甚至能“预测问题”(如根据代码变更预测可能引发的性能瓶颈)。
3. 多模态融合:不止“文本→代码”
代码开发涉及的不止文本(需求文档、代码),还有视觉(UI设计图、流程图)、音频(会议录音中的需求)。未来的代码智能体将融合多模态输入,如“根据UI截图生成前端代码”“根据会议录音提取需求并生成后端接口”,真正实现“所见即所得”的开发体验。
总结
代码智能的核心价值并非替代开发者,而是通过自动化重复编码工作,释放人类在需求分析、架构设计等高阶创造性任务上的潜力。
该领域已从零散技术探索走向体系化工程,未来将成为软件研发的核心基础设施,推动研发效率、代码质量与安全性的全面提升,重塑软件开发生态。


















 2456
2456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









