



作者 | 逆光飞翔2020 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1980048833590339263
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文

导读
破解“端到端模型长尾故障”痛点!现有端到端自动驾驶模型受限于训练数据中的罕见安全关键场景(长尾问题),手动收集此类数据成本高、风险大。西湖大学+理想汽车+天津大学联合提出CorrectAD自校正智能体系统,实现四重突破:
PM-Agent模拟产品经理,多轮推理分析故障原因并制定多模态数据需求;
DriveSora可控视频生成模型,生成与3D标注对齐的高保真多视图视频;
端到端模型无关,适配UniAD、VAD等主流规划器;
迭代自校正循环,持续缩小生成数据与故障分布的差距。
实验验证:在nuScenes和内部挑战性数据集上,分别修复62.5%和49.8%的故障案例,碰撞率降低39%和27%,为自动驾驶模型的持续优化提供自动化、低成本解决方案。
推荐理由
核心价值:首个实现E2E自动驾驶故障自校正的智能体系统,PM-Agent精准析因+DriveSora定向生成,故障修正率62.5%、碰撞率降39%,支持多E2E模型,无需手工收集标注;
落地意义:将故障修正周期从数周缩短至数天,大幅降低数据迭代成本,可直接集成到车企现有模型优化流程;
学术价值:提出“智能体析因→定向生成→迭代微调”的自校正范式,解决生成模型与故障修正的衔接问题,DriveSora生成质量超SOTA(FVD 94.51、NDS 36.58)。
1 核心概念:关键定义与术语解析
1.1 当前痛点
手工数据收集成本极高
长尾故障(Long-tail Failure,如低能见度碰撞、密集车流绕行失效)罕见且危险,手工收集标注需数周时间和数千美元成本,扩展性差。
现有方法数据多样性不足
检索式方法(如AIDE)仅从现有数据集筛选相似场景,无法覆盖未见过的长尾故障,难以从根源修正模型缺陷。
生成模型缺乏定向可控性
现有驾驶场景生成模型(如MagicDrive)可控性差,无法精准匹配故障修正所需的场景特征,生成数据与故障关联性弱。
故障与生成模型存在衔接鸿沟
缺乏有效机制将E2E模型的故障案例转化为生成模型可理解的需求,导致生成数据无法针对性解决故障。
1.2 核心术语
术语 | 细节描述 |
|---|---|
CorrectAD | 自校正智能体系,通过PM-Agent分析故障、DriveSora生成数据,实现端到端模型故障自修复 |
PM-Agent | 模拟产品经理的智能体,基于VLM多轮推理,分析故障原因并生成多模态数据需求(BEV布局+场景描述) |
DriveSora | 可控多视图视频生成模型,基于STDiT架构,生成与3D标注对齐的高保真自动驾驶场景视频 |
自校正循环 | 故障分析→多模态需求→数据生成→模型微调→评估迭代的自动化流程,持续缩小生成数据与故障分布差距 |
故障案例 | 端到端模型规划轨迹在未来T步内与其他交通参与者或道路边界发生碰撞的场景 |
1.3 关键公式与指标
故障案例定义:
其中 为车辆位置, (安全阈值), (规划时域)。
多条件无分类器引导:
其中 (文本约束权重), (背景约束权重), (前景约束权重)。
生成数据质量指标:帧内一致性(FID)、帧间一致性(FVD)、检测适配性(NDS)、语义对齐度(CLIP分数);
模型性能指标:轨迹误差(L2)、碰撞率(Collision Rate)、故障修复率(Failure Correction Rate)。
2 核心方法:CorrectAD系统详解(深度展开)
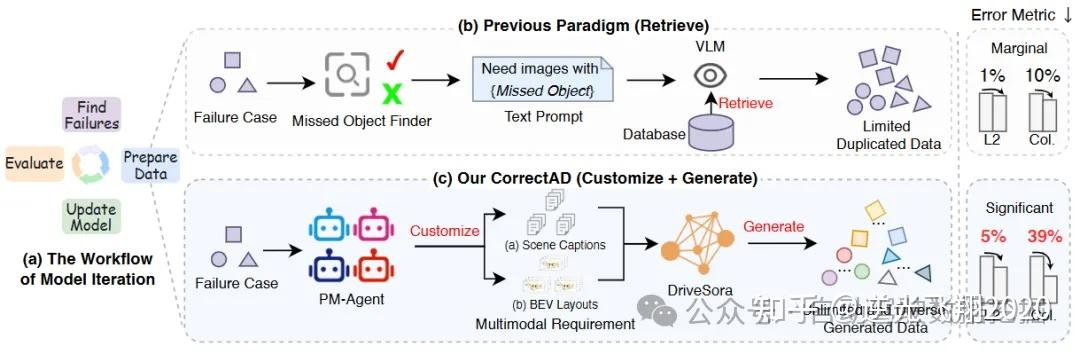
📷图1:(a):一个模型迭代的工作流程包括4个步骤:找出失败案例、准备训练数据、模型更新,然后进行评估并再次迭代。关键问题在于如何准备特定的训练数据来纠正这些失败案例。(b):以往的范式是基于检索的,即从现有数据中检索相似数据并自动标记,这严重限制了训练数据的多样性。(c):我们提出的智能体系统CorrectAD是定制生成的。我们首先提出PM-Agent,其作用类似于产品经理,通过分析失败案例来制定数据需求。然后,提出生成模型DriveSora,其作用类似于数据部门,用于生成符合PM-Agent所提出的数据需求的高保真训练数据。在端到端规划模型的L2和碰撞率(Col.)方面,本文的方法优于以往的方法。
2.1 整体框架
逻辑整体框架如图1所示,流程图如下:
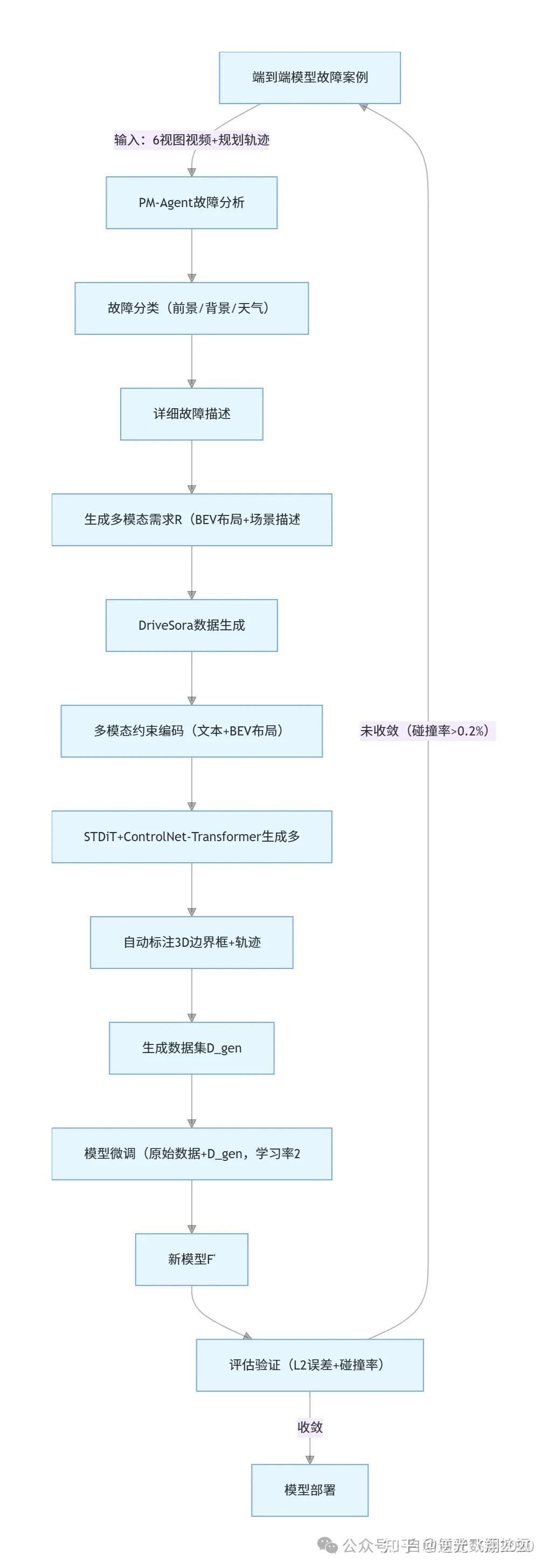
2.2 核心模块1:PM-Agent(故障分析与需求制定)
2.2.1 故障分类:从聚类到多轮推理
步骤1:故障原因标注与聚类。
抽取27个故障案例,由领域专家标注10条/案例的故障原因;
用GPT-4o提取关键词(如“雨天”“路面湿滑”“低能见度”),设置欧氏距离阈值0.8进行模糊聚类;
层次聚类+K-Means(K=3),最终得到“前景”“背景”“天气”三大故障类别。
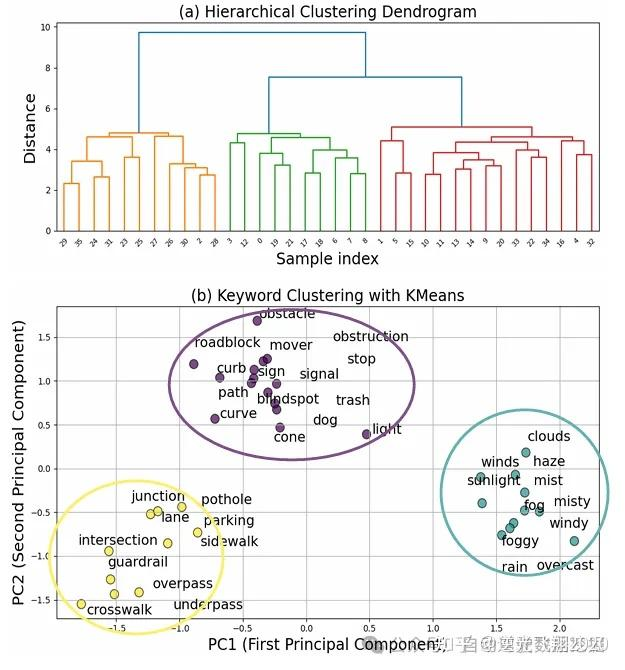
📷图2: 规划失败案例的聚类结果。
步骤2:多轮问询分类。
第一轮:输入6视图视频+规划轨迹,VLM输出“是否属于某类别+置信度”(阈值0.8);
第二轮:针对高置信度类别,进一步细化原因(如“天气类→雨天导致路面湿滑+低能见度”)。


📷图3:分析故障原因的prompt。
2.2.2 多模态需求构建:BEV布局+场景描述
场景描述生成:
基于故障原因,用LLM生成结构化场景描述(如“雨天、低能见度、城市道路跟车场景,路面湿滑,前车突然减速”);

📷图4:生成需求的prompt。
BEV布局提取:
从训练集中检索与场景描述语义相似的场景—— LLM 将数据需求与所有场景字幕进行初步筛选比较(caption)。接下来VLM 将数据需求与初步筛选后剩余场景中的图像进行比对,进一步筛选以识别匹配场景。(BLIP-2计算图像-文本相似度,阈值0.9)如图5
提取检索场景的BEV布局,包含两部分:
背景布局( ):道路边界、车道线的彩色线图( );
前景布局( ):3D边界框坐标( )、航向角( )、实例ID( )、密集描述( );


需求组合:将场景描述(文本 )与BEV布局( )组合为多模态需求 。
📷 图5:多模态需求制定的prompt。
2.2.3 关键优化:多轮推理提升准确性
单步推理缺陷:语义距离4.66,原因描述片面(如仅提及“路面湿滑”,忽略“低能见度”);
多轮推理优势:语义距离降至3.49,通过“分类→细化→补充”三步,覆盖故障全部关键因素。

📷图6:PM-Agent的框架。给定一个失败案例,PM-Agent首先将失败原因分类为,随后详细分析失败描述。基于,PM-Agent生成具体需求。之后,PM-Agent构建与该失败案例相似的多模态需求(包括鸟瞰布局和场景描述),以与后续的生成模型进行交互。
2.3 核心模块2:DriveSora(高保真数据生成)
2.3.1 基础架构:时空扩散Transformer(STDiT)
整体结构:28层Transformer块,分为encoder(前13层)和decoder(后15层),输入为噪声latent (维度 ,B=批次、V=视图数、T=帧数、S=嵌入分辨率、C=通道数);
预训练初始化:基于OpenSora 1.1 checkpoint,单视图模型先训练30k迭代,再扩展为多视图模型训练25k迭代。
2.3.2 关键技术1:ControlNet-Transformer集成(3D布局约束)
核心目标:让生成视频严格对齐BEV布局中的道路草图和边界框;
实现逻辑:
为STDiT的前13层encoder各添加一个可训练的“复制块”(Base Block_1~13);
复制块输出经Zero初始化的线性层,与原encoder块输出相加,作为下一层输入;
道路草图( )经VAE编码为 ,注入ControlNet-Transformer,实现精准控制;
优势:不破坏原STDiT的生成能力,仅通过增量训练实现布局约束。
2.3.3 关键技术2:参数无关多视图空间注意力(空间一致性)
传统方案缺陷:需额外跨视图注意力层,增加参数且一致性差;
创新操作:
重塑输入特征:将 转为 ;
直接应用自注意力:让不同视图的特征在同一注意力窗口中交互,无需额外参数;
效果:多视图生成的车辆位置、航向角一致性提升15%,FVD降低2.8%。
2.3.4 关键技术3:多条件无分类器引导(语义对齐)
训练阶段:
每个条件(文本 、前景 、背景 )独立以5%概率设为 (空),同时全部设为空的概率也为5%;
损失函数:标准扩散损失,联合优化多条件对齐;
推理阶段:
采用整流流采样(30步),提升生成速度;
按公式叠加各条件的引导信号,强化文本与布局的协同约束——交替屏蔽文本、前景、背景条件,强化单个约束的引导作用,公式如下:
其中 。
2.3.5 自动标注流程
3D边界框:用预训练3D检测器(NDS=34.56)对生成视频进行帧级标注;
轨迹生成:基于边界框序列,用卡尔曼滤波平滑得到连续轨迹;
输出格式:与nuScenes数据集一致,支持直接用于模型微调。
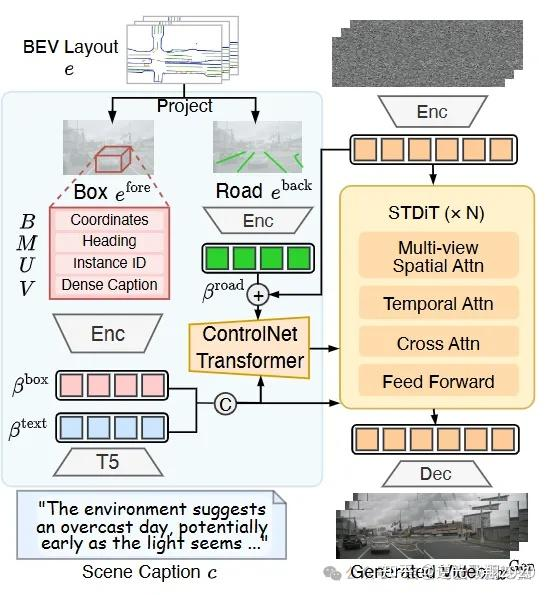
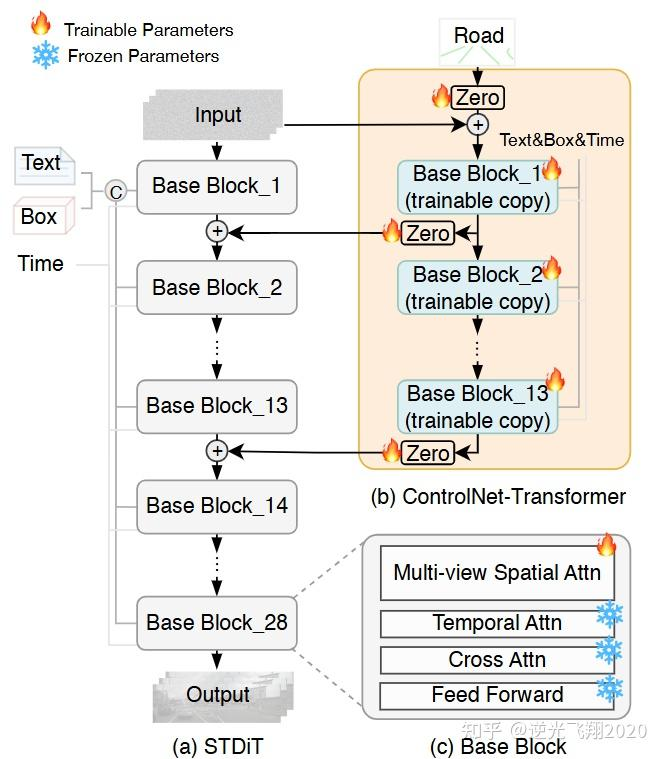
📷 图7:DriveSora框架和ControlNet-Transformer,执行数据生成任务,旨在产生高质量、多样化的新型数据。
2.4 核心模块3:自校正循环(迭代优化机制)
2.4.1 分布对齐量化
指标:Hellinger距离(D-D),衡量生成数据与故障案例的分布差异,值越小对齐度越高;
计算流程:
用LLM提取故障案例和生成数据的场景关键词(Top 100高频词);
计算关键词频率分布的Hellinger距离:

📷图8:关键词提取的prompt。
2.4.2 迭代微调策略
数据混合:原始训练数据与生成数据 按4:1比例混合;
超参数:学习率2e-5,优化器HybridAdam,批次大小16,微调迭代10k;
迭代终止条件:连续2轮D-D<0.1或碰撞率<0.2%。
2.4.3 多轮迭代效果
迭代1:D-D=0.15,L2=1.06m,碰撞率=0.26%;
迭代2:D-D=0.11,L2=1.04m,碰撞率=0.22%;
迭代3:D-D=0.09,L2=0.98m,碰撞率=0.19%;
关键结论:生成数据分布逐步向故障场景收敛,模型故障修复率持续提升。
3 实验结果:性能验证与关键发现
3.1 实验设置
数据集:①nuScenes(700训练/150验证场景,6视图、12Hz,单场景20s);②内部挑战性数据集(3M训练/0.6M验证场景,6视图、10Hz,含36%变道、15.8%转弯场景);
对比方法:AIDE(检索式数据扩充,重构适配端到端规划任务);
评估模型:UniAD、VAD、内部自研端到端模型(基于STDiT架构);
硬件:训练(8×A800 GPU),推理(L40S GPU)。
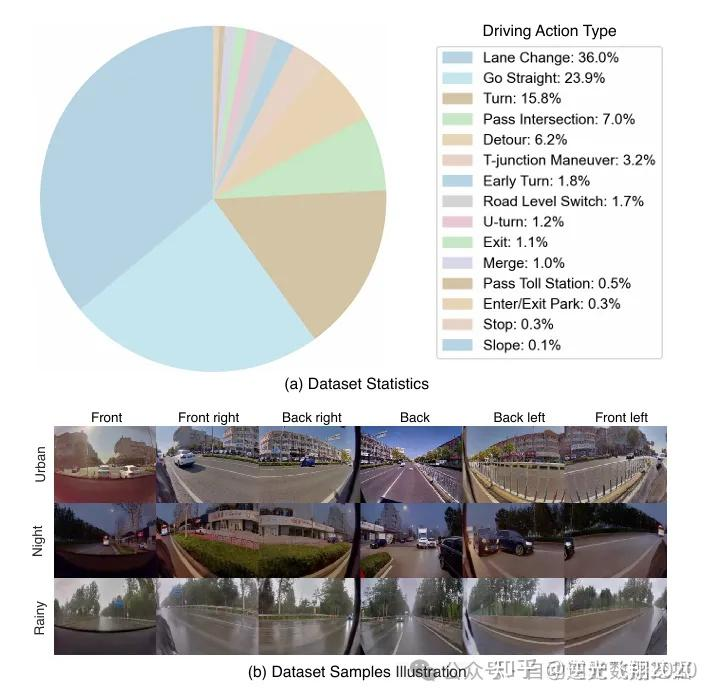
📷图9: 内部数据集驾驶动作统计数据

📷图10: GT的因果示例,以及PM-Agent和基线(单步GPT4o)对响应的影响。
3.2 核心性能结果
(1)故障修复与安全指标提升
数据集 | 方法 | 故障修复率 | L2误差(m)↓ | 碰撞率(%)↓ |
|---|---|---|---|---|
nuScenes | 基线(UniAD) | - | 1.25 | 0.35 |
nuScenes | AIDE | 31.2% | 1.06 | 0.29 |
nuScenes | CorrectAD | 62.5% | 0.98 | 0.19 |
内部数据集 | 基线(自研) | - | 1.06 | 0.26 |
内部数据集 | AIDE | 28.5% | 0.79 | 0.22 |
内部数据集 | CorrectAD | 49.8% | 0.62 | 0.19 |
(2)DriveSora生成质量对比
生成模型 | FID↓ | CLIP↑ | FVD↓ | NDS↑ |
|---|---|---|---|---|
MagicDrive-v2 | 20.91 | 85.25 | 94.84 | 35.79 |
Panacea | 16.96 | 84.23 | 139.0 | 32.10 |
DriveSora | 15.08 | 86.73 | 94.51 | 36.58 |
(3)多轮迭代效果
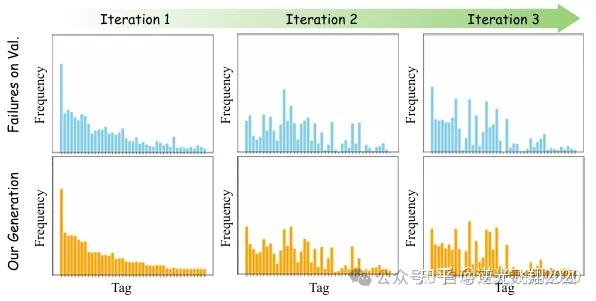
📷图11:多轮迭代中增强数据与验证集上失败案例之间的分布差距。
3.3 消融实验验证
(1)模块贡献
配置 | L2误差(m)↓ | 碰撞率(%)↓ |
|---|---|---|
随机复制训练数据 | 1.25 | 0.35 |
仅DriveSora(无PM-Agent) | 1.12 | 0.29 |
仅PM-Agent(无DriveSora) | 1.09 | 0.27 |
CorrectAD(完整配置) | 0.98 | 0.19 |
(2)关键技术贡献
配置 | FID↓ | NDS↑ |
|---|---|---|
无多模态约束+无多视图注意力 | 25.65 | 25.23 |
有多模态约束+无多视图注意力 | 17.23 | 36.37 |
有多模态约束+有多视图注意力 | 15.08 | 36.58 |
3.4 定性结果
故障修复示例:低能见度夜间场景中,基线模型偏离车道碰撞,CorrectAD生成对应数据微调后,模型能提前减速避让;
生成数据一致性:DriveSora生成的6视图视频中,车辆位置、航向角跨帧跨视图一致,无MagicDrive的“航向错误”“物体突变”问题;
可控性验证:支持实例编辑(车辆颜色切换)和场景编辑(晴天→雨天),生成结果与约束完全对齐。
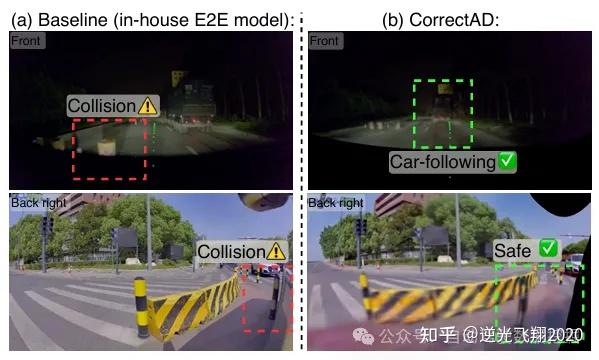
📷图12:在内部验证集上进行自校正前后的两个示例可视化结果:通过基于高斯泼溅的专有闭环模拟器渲染。
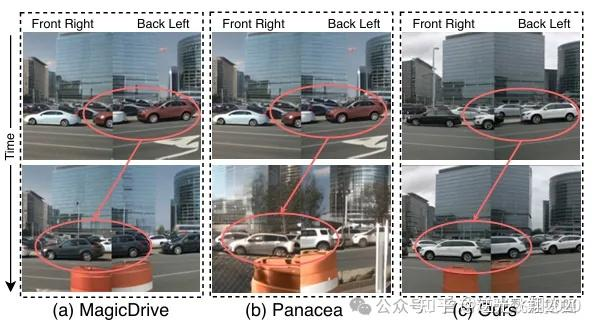
📷图13: 跨帧一致性比较。
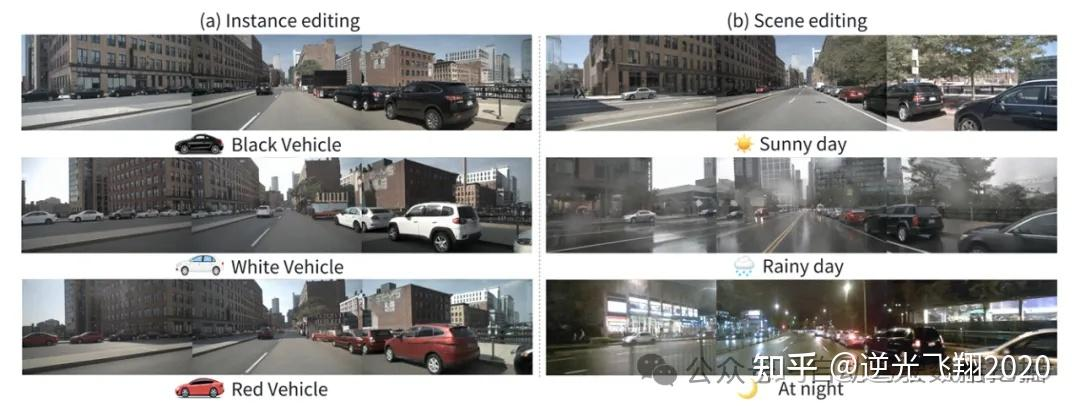
📷图14:实例与场景编辑的可视化效果。图(a)展示了实例层面的控制结果,如所有车辆的呈现属性;图(b)展示了场景层面的控制结果,包括天气和时间因素。
4 挑战与未来方向
4.1 当前局限
故障类型单一:仅将碰撞视为故障,未涵盖车道违规、交通规则违反等场景;
生成效率较低:DriveSora(1.1B参数)需8×A800 GPU训练72小时,推理单样本需4秒(L40S);
复杂交互场景生成不足:对多智能体复杂博弈场景的生成能力有待提升。
4.2 未来方向
扩展故障类型:结合多维度基准,纳入车道保持、交通规则遵守等评估维度;
提升生成效率:集成快速扩散模型(如SANA),优化推理速度;
增强复杂场景生成:引入博弈论建模多智能体交互,提升长尾场景覆盖;
闭环部署适配:与真实车辆部署流程结合,实现线上故障实时反馈与模型迭代。
5❓ 核心QA(基于论文内容)
Q1:PM-Agent如何保证故障原因分析的准确性?
A1:采用多轮问询策略,先分类(前景/背景/天气)再细化描述,结合ICL(上下文学习)注入故障案例示例,语义距离从单步问询的4.72降至3.49,前景/背景/天气析因准确率分别达92.59%、87.41%、91.85%。
Q2:DriveSora相比其他生成模型的核心优势是什么?
A2:① 可控性强:通过BEV布局+文本双条件,精准匹配故障修正需求;② 多视图一致性好:参数无关多视图空间注意力解决跨视图错位;③ 生成质量高:FID 15.08、FVD 94.51,NDS 36.58,超现有SOTA模型。
Q3:CorrectAD为何支持多E2E模型?
A3:采用模型无关设计,核心是通过生成“通用高保真训练数据”补充模型的长尾场景覆盖,而非针对特定模型定制,因此可直接应用于UniAD、VAD、内部E2E等不同架构。
Q4:与检索式方法(如AIDE)的区别是什么?
A4:AIDE从现有数据集检索相似数据,数据多样性不足,无法覆盖未见过的故障;CorrectAD通过定向生成,可创造全新场景,生成数据与故障分布更贴合,故障修正率比AIDE高30%+。
Q5:迭代自校正的意义是什么?
A5:每轮迭代后,生成数据会更贴近故障分布,模型微调后新的故障会减少,同时暴露未修正的旧故障,持续迭代使故障修正率逐步提升,3轮迭代后nuScenes故障数从22降至14。
6 总结
核心价值
架构创新:首个“故障分析→定向生成→迭代优化”的自动化自校正框架,打破人工数据收集依赖;
数据质量卓越:DriveSora在保真度、一致性、适配性上超越现有生成模型,sim-to-real差距显著缩小;
模型无关兼容:适配主流端到端规划器,无需重构模型,落地成本低;
持续优化能力:迭代循环使生成数据与故障分布逐步对齐,模型性能持续提升。
总结金句
👉 “CorrectAD的核心突破,在于用‘PM-Agent精准锚定故障需求+DriveSora生成高保真数据+迭代循环持续优化’,将自动驾驶模型的故障修复从‘人工依赖’推向‘自动化闭环’,既解决了长尾场景数据稀缺的痛点,又大幅降低了模型迭代成本,为端到端自动驾驶的安全部署提供了可持续的优化方案。”
7 原论文信息
论文题目:CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
作者:Enhui Ma等(西湖大学Autolab+理想汽车+天津大学)
发表状态:arXiv preprint(2025年11月)
核心价值:提出自校正智能体系统,通过定向数据生成实现端到端模型故障自修复,大幅提升长尾场景鲁棒性
关键链接:arXiv链接:https://arxiv.org/pdf/2511.13297v1.pdf
核心数据:
故障修复率:nuScenes 62.5%,内部数据集49.8%;
碰撞率降低:nuScenes 39%,内部数据集27%;
生成模型性能:FID=15.08,FVD=94.51,NDS=36.58(SOTA水平)。
自动驾驶之心
端到端与VLA自动驾驶小班课!

添加助理咨询课程!

知识星球交流社区


















 2593
2593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









