



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Qirui Hou等
编辑 | 自动驾驶之心
一、研究背景与挑战
自动驾驶系统的安全性和可靠性高度依赖4D动态场景重建(即3D空间+时间维度的实时、高保真环境感知)。当前行业面临两大核心矛盾:
传感器成本与效率的平衡:传统多模态方案依赖LiDAR、RaDAR等设备,虽精度高但成本昂贵;纯视觉方案(仅用摄像头)虽具备成本优势,却需解决“稀疏视角+动态物体”带来的重建难题——如何从360度环视相机的连续帧中,实时输出几何准确、视觉真实的大尺度动态场景。
现有渲染技术的局限:神经渲染方法(如NeRF、3D高斯溅射3DGS)在静态场景重建(如StreetGaussian、DrivingGaussian)中表现出色,但受限于“逐场景离线优化”范式,无法满足自动驾驶的实时性需求;而面向动态场景的方案(如EmerNeRF)同样存在离线问题,端到端动态建模方法(如Driv3R)虽尝试在线重建,却因未解耦“静态场景基础”与“动态物体运动”,不仅计算负担重,还会导致重建细节丢失、稳定性差(如动态物体重影、模糊)。
此外,静态前馈方案(如DrivingForward、pixelSplat)虽实现了在线推理,但因假设“场景无动态”,面对行驶车辆、行人等移动目标时会产生严重伪影,难以适配真实驾驶场景。
二、核心创新点
哈尔滨工业大学联合理想汽车等研究团队通过三大关键设计突破现有瓶颈,实现“实时性+高保真+多任务输出”的统一:
静到动两阶段训练范式:先从大规模数据中学习鲁棒的静态场景先验(如建筑、道路等刚性结构),冻结静态网络后再训练动态模块,彻底解决端到端训练的不稳定性,同时降低动态建模的复杂度。
混合共享架构的残差流网络:设计“共享深度编码器+单相机解码器”结构——共享编码器学习通用运动先验,轻量化单相机解码器适配不同相机的内外参,仅预测“动态物体的非刚性运动残差”(而非完整运动场),兼顾跨视角尺度一致性与计算效率。
纯视觉在线前馈框架:仅输入两帧连续环视图像,即可实时输出3D高斯点云、深度图、场景流等多任务结果,无需离线优化或多模态传感器,适配自动驾驶的在线感知需求。
三、相关工作梳理
静态驾驶场景重建
代表方案:DrivingForward、pixelSplat、MVSplat、DepthSplat
核心特点:基于3DGS或多视图立体匹配(MVS),采用前馈推理实现静态场景的快速重建,可处理稀疏环视视角。
不足:均假设场景无动态,面对移动车辆、行人时会出现重影、几何偏移等伪影,无法适配真实驾驶场景的动态性。
动态驾驶场景重建
代表方案:Driv3R、EmerNeRF
核心特点:Driv3R采用端到端架构建模4D动态,但未解耦静动态成分,模型参数大(2.512GB)、训练耗时(约7.5天)、推理慢(0.71s/帧);EmerNeRF通过自监督实现时空分解,但依赖逐场景离线优化,无法满足实时性。
3D高斯溅射(3DGS)衍生方法
代表方案:StreetGaussian、DrivingGaussian
核心特点:将3DGS应用于城市/驾驶场景,提升静态场景的渲染质量与效率。
不足:均为离线优化范式,需针对每个场景单独训练,无法支持自动驾驶的在线感知任务。
四、主要技术方案
整体框架如figure 2所示:输入两帧连续环视图像,先通过静态模块生成3D高斯表示的静态场景,再通过残差流网络预测动态运动,最终融合生成4D动态场景。
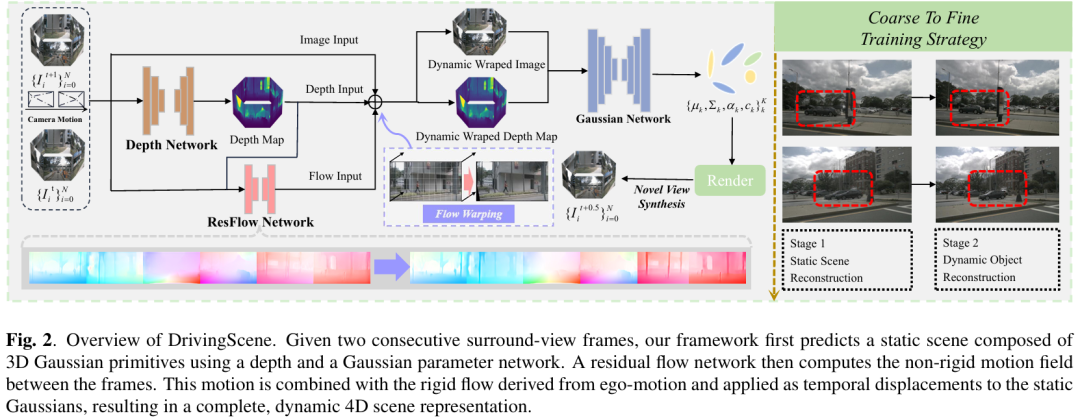
静态场景几何与外观建模
以3D高斯溅射(3DGS)为场景表示核心,每个高斯基元定义为 ,其中:
:3D空间均值(位置);
:协方差矩阵(形状);
:不透明度;
:球谐函数(SH)系数(外观)。
设计两个前馈网络实现高斯参数的直接预测:
深度网络(D):输入环视图像与相机姿态,输出逐像素深度图,进而计算所有高斯基元的 (位置信息);
高斯参数网络(P):输入图像特征与深度特征,推理 等剩余参数。
所有相机视角的高斯基元通过已知外参转换到世界坐标系,拼接为统一静态场景表示。该过程无需3D空间去重或融合,而是依赖可微渲染器在视图合成时自动抑制遮挡、不一致的高斯基元(使其对最终像素颜色贡献最小)。
基于残差场景流的动态建模
为捕捉动态物体运动,提出残差流网络(R),将总运动场分解为“刚性运动( )+非刚性残差运动( )”:
:由预测深度与相机姿态计算,对应“自车运动引发的全局场景运动”(如车辆前进导致的背景平移);
:由残差流网络预测,仅建模“动态物体的非刚性运动”(如其他车辆变道、行人行走)。
残差流网络架构如figure 3所示,采用“粗到细”优化策略:
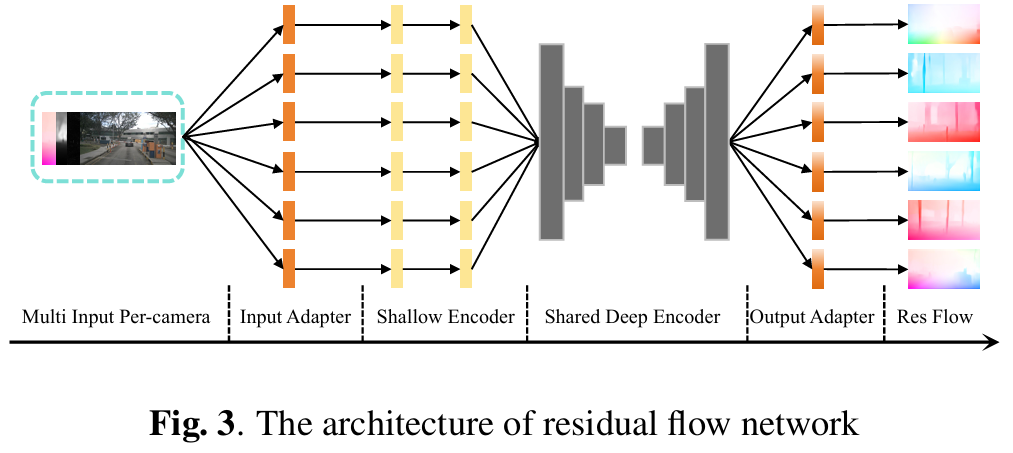
共享深度编码器:提取多尺度通用运动特征;
单相机金字塔解码器:从低分辨率到高分辨率迭代优化流场,每个分辨率的预测作为下一级的初始估计,有效处理大位移运动;
输入适配层:针对不同相机的内外参调整输入特征,确保跨视角的尺度一致性。
两阶段训练策略与损失函数
阶段1:静态网络训练(冻结前)
仅训练深度网络(D)与高斯参数网络(P),损失函数为:
:多视图一致性损失,通过 photometric 重投影误差确保不同视角的几何一致性;
:视差图平滑损失,惩罚深度图中的大梯度,避免几何碎片化;
:渲染损失,最小化渲染图与真值图的差异,公式为:
其中 为像素级损失, 为感知损失(权重0.05),确保视觉保真度。
阶段2:残差流网络训练(静态网络冻结)
仅训练残差流网络(R),损失函数为:
:流场一致性损失,通过“前向-后向流场校验”确保运动估计的几何合理性;
:流场扭曲损失,对“由总运动场扭曲的源图像”与目标图像施加一致性约束,公式为:
其中 为扭曲图像, 、 ,结合L1(像素级)、SSIM(结构相似性)、LPIPS(感知)损失,强化运动与渲染的耦合一致性;
:与阶段1一致,确保动态场景的渲染质量。
五、实验验证与结果分析
实验设置
数据集:nuScenes(700个训练场景、150个验证场景),图像分辨率352×640;
硬件:PyTorch框架,NVIDIA RTX5090 GPU(32GB);
训练参数:Adam优化器(学习率1e-4),阶段1(6轮)、阶段2(6轮);
评价指标:novel view synthesis(PSNR、SSIM、LPIPS)、深度预测(Abs Rel、Sq Rel、RMSE)、效率(推理时间、VRAM占用、模型参数)。
定量结果(对比主流方案)
Novel View Synthesis
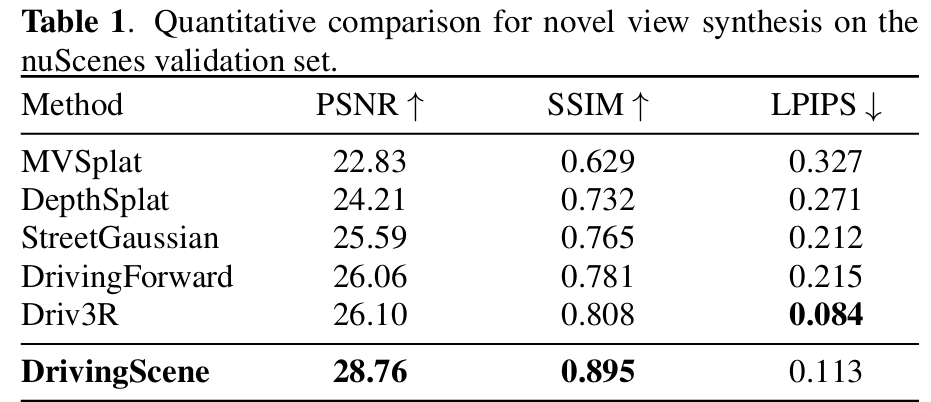
在nuScenes验证集上,该方法全面超越前馈类基线:
PSNR达28.76,较Driv3R(26.10)提升2.66dB,较DrivingForward(26.06)提升2.7dB;
SSIM达0.895,显著高于Driv3R(0.808)与DrivingForward(0.781);
LPIPS达0.113(越低越好),虽略高于Driv3R(0.084),但综合PSNR、SSIM仍体现更优的渲染保真度。
深度预测

几何准确性优于Driv3R:
Abs Rel(绝对相对误差)0.227 vs 0.234;
Sq Rel(平方相对误差)2.195 vs 2.279;
RMSE(均方根误差)7.254 vs 7.298,验证静态先验与动态残差结合的几何建模有效性。
5.2.3 效率与模型复杂度
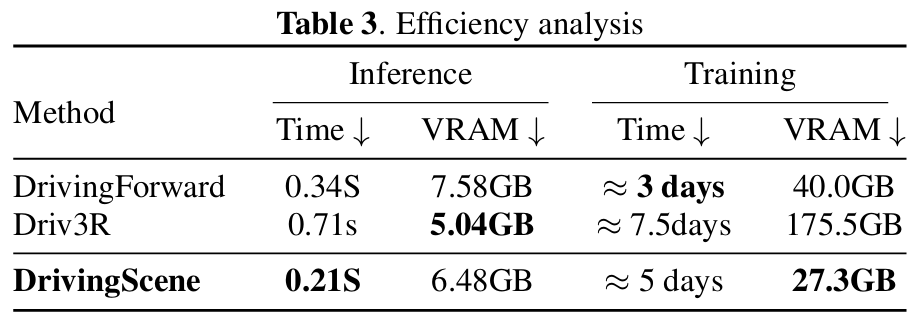

推理速度:0.21s/帧(6路环视图像),比DrivingForward(0.34s)快38%,比Driv3R(0.71s)快70%;
训练成本:训练时间约5天,VRAM占用27.3GB,远低于Driv3R(7.5天、175.5GB);
模型大小:参数0.117GB,仅为Driv3R(2.512GB)的4.6%、DrivingForward(0.173GB)的67.6%,体现轻量化优势。
定性结果
动态物体重建(figure 4):DrivingForward因静态假设,对移动车辆、行人产生明显重影;Driv3R虽能捕捉动态,但细节模糊;该方法可生成边缘清晰、时序一致的动态物体重建结果。
运动场分解(figure 5):刚性流( )准确捕捉自车运动引发的全局背景平移,全流( )可清晰定位动态物体(如侧方行驶车辆),验证残差流网络的动态建模能力。
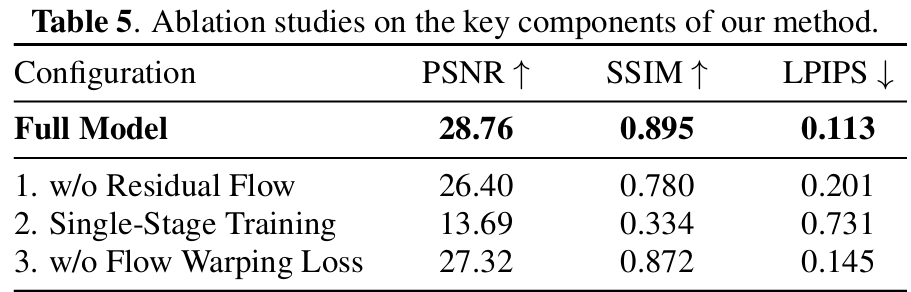
消融实验
验证核心设计的必要性:
残差流网络:去除后模型退化为“静态版”,PSNR、SSIM显著下降,证明动态建模对真实场景重建的关键作用;
两阶段训练:替换为端到端训练后,模型无法学习尺度一致的几何,渲染质量大幅退化,凸显静态先验的基础价值;
流场扭曲损失( ):去除后渲染图与动态运动的一致性下降,验证该损失对多任务协同的约束作用。
参考
[1]DrivingScene: A Multi-Task Online Feed-Forward 3D Gaussian Splatting Method for Dynamic Driving Scenes
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









