




点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
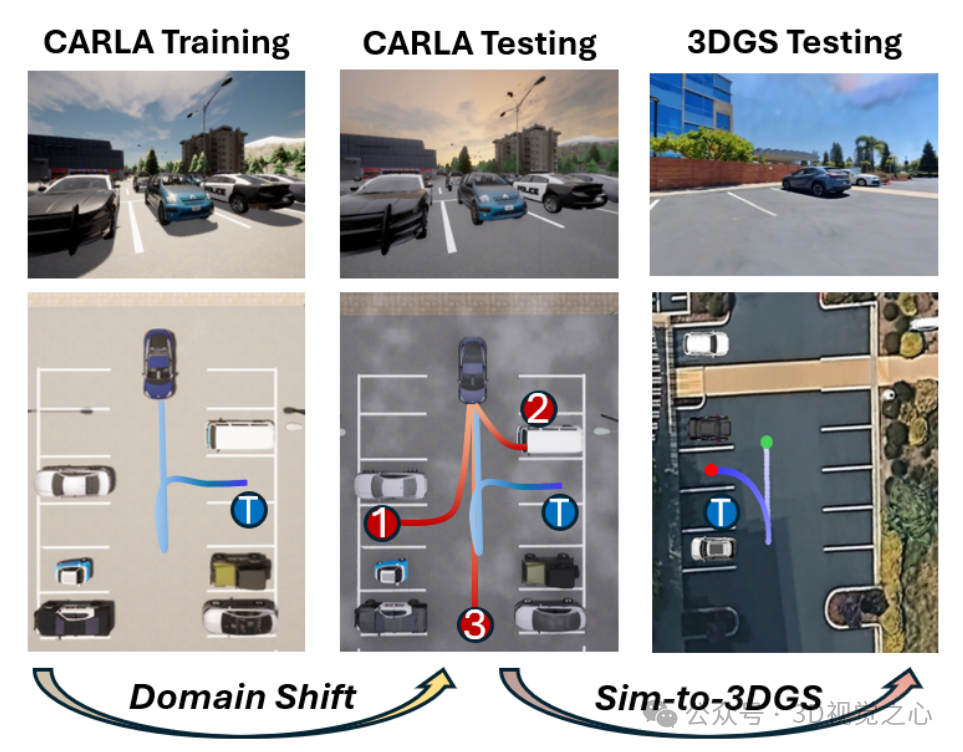
E2E停车模型容易受到天气影响失效
自动驾驶技术近年来发展迅速,全球近60%的新车已配备某种形式的自动驾驶功能。这些系统通过多种传感器感知环境,并根据车辆状态做出决策,实现低干预的自动控制。与开放道路驾驶不同,自动停车面临独特挑战:空间受限、频繁转向、低速复杂路径规划。值得注意的是,停车相关事故占美国所有车辆事故的20%,其中91%发生在倒车过程中,凸显了精确感知、规划和控制的重要性。
早期研究通常假设拥有高精度地图,重点在于轨迹搜索和优化控制。为实现完整的停车系统,后续研究聚焦于从环视图像构建鸟瞰图(BEV)表示,并用于感知任务。
近年来,端到端(E2E)方法逐渐成为主流。相比传统基于规则的方法,E2E 方法将感知与规划统一,利用真实数据提升泛化能力。然而,这类方法通常对训练与测试分布的一致性要求较高,视觉变化(如天气、光照)会导致策略失效,尤其在跨域迁移时表现不佳。
论文标题:Dino-Diffusion Modular Designs Bridge the Cross-Domain Gap in Autonomous Parking
项目链接: https://github.com/ChampagneAndfragrance/ Dino_Diffusion_Parking_Official
为解决这一问题,本文提出一种模块化、级联的停车系统,结合视觉基础模型(DINOv2)与扩散模型进行轨迹建模,并引入数据增强策略以提升跨域泛化能力。我们的主要贡献如下:
首次提出面向跨域自动驾驶停车的零样本迁移方法;
构建模块化停车系统,解耦感知、规划与控制,避免过拟合;
在 CARLA 跨域基准测试中显著优于现有方法,并在3DGS环境中验证其 sim-to-real 潜力。
具体方法
我们提出的 Dino-Diffusion Parking(DDP) 系统包括以下模块:
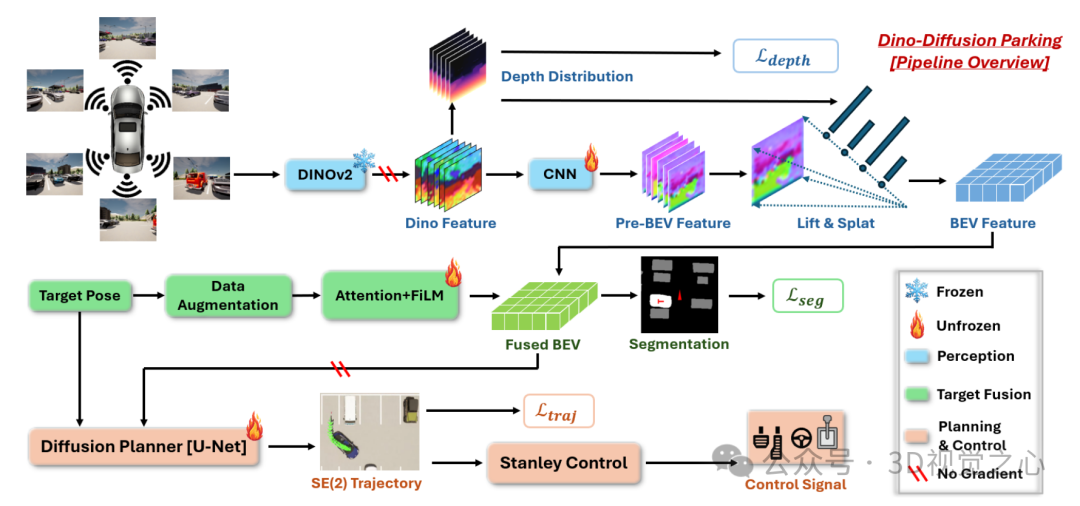
A. 基于视觉基础模型的鲁棒感知
我们使用预训练的 DINOv2 模型提取图像特征,并将其转换为BEV表示。由于DINOv2具备强大的跨域泛化能力,即使在视觉变化下也能生成一致的嵌入表示,从而为后续规划提供稳定输入。
算法1:鲁棒BEV生成
输入:相机图像 I,DINOv2 模型 φ_dino,相机参数
输出:BEV 特征图 F_b
步骤:
提取DINOv2特征:F = φ_dino(I)
特征处理与深度估计:F = φ_f(F),F_d = φ_d(F)
生成BEV:F_b = φ_b(F, F_d, CamParameter)
B. 基于重标注的目标融合
为避免目标位姿在跨域时漂移,我们提出一种后见目标重标注策略:在训练过程中对目标位姿进行扰动,并重新生成对应的分割图作为训练数据。通过交替使用专家数据与重标注数据,提升模型对目标位姿的鲁棒性。
此外,我们使用 FiLM 结构将目标位姿信息融合到BEV特征中,避免梯度传播带来的不稳定。
算法2:目标融合与分割
输入:BEV特征 F_b,目标位姿 P_tgt,分割图 I_s
输出:预测分割图 F_s
步骤:
随机扰动目标位姿并重新生成分割图
使用交叉注意力与FiLM融合目标信息
输出生成的分割图 F_s
C. 基于扩散模型的轨迹规划
我们将轨迹规划建模为扩散过程,状态包括车辆位置 (x, y) 与朝向角 θ。扩散模型以BEV特征、分割图和目标位姿为条件,生成未来轨迹。相比直接回归控制指令,该方法在SE(2)空间中建模,能有效降低误差累积。
算法3:扩散轨迹规划
输入:专家轨迹 T_v
输出:规划轨迹 τ
步骤:
将轨迹分段并降采样
在训练中加入噪声并进行去噪学习
推理阶段从高斯噪声中逐步去噪生成轨迹
D. Stanley控制器实现精准跟踪
我们使用Stanley控制器对生成的轨迹进行跟踪。该控制器结合朝向误差与横向误差,计算转向角:
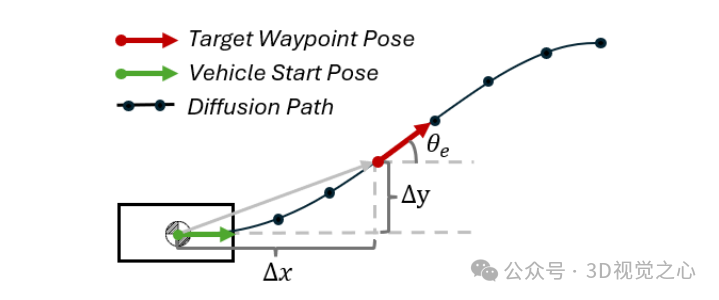
该控制器与扩散规划器协同工作,兼顾环境感知与精准控制,适用于狭小停车空间。
实验与讨论
A. 实验设置
我们在CARLA模拟器中训练系统,使用800条专家轨迹,测试环境包括三种天气设置:
Same:与训练环境一致
Mild:轻度域偏移(如云层、降水)
Large:重度域偏移(如低光照、大雾)
每个环境测试16个车位,6种起始位姿,评估指标包括成功率、碰撞率、误差、时间等。
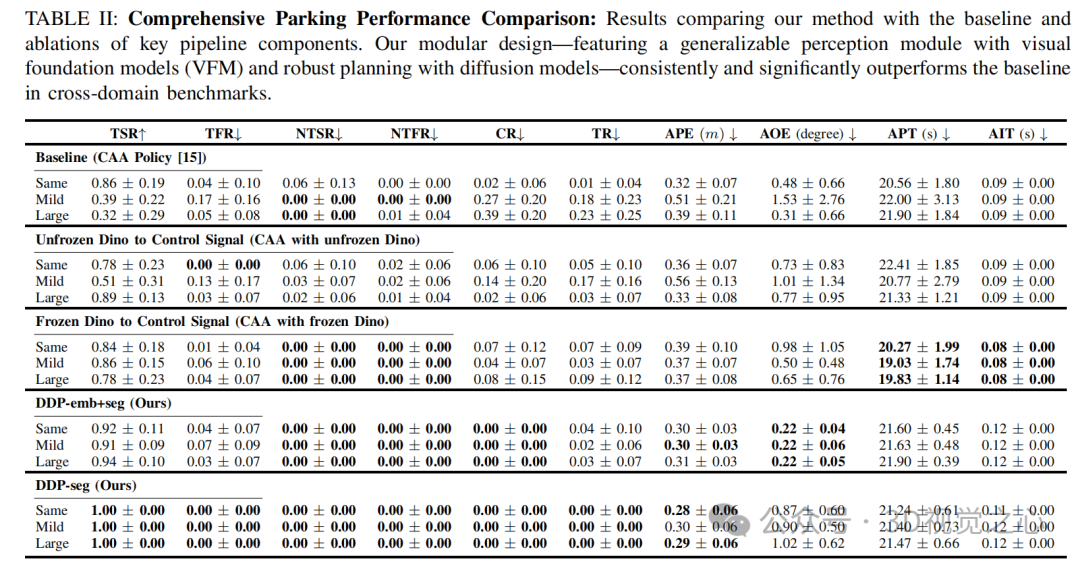
B. 视觉基础模型提升感知泛化能力

我们通过可视化与误差分析发现,DINOv2提取的特征在不同域下保持一致,而传统模型(如EfficientNet)则对视觉变化敏感。定量结果显示,我们的方法在多个特征层上误差显著降低,验证了其跨域鲁棒性。
C. 数据增强提升目标识别稳定性
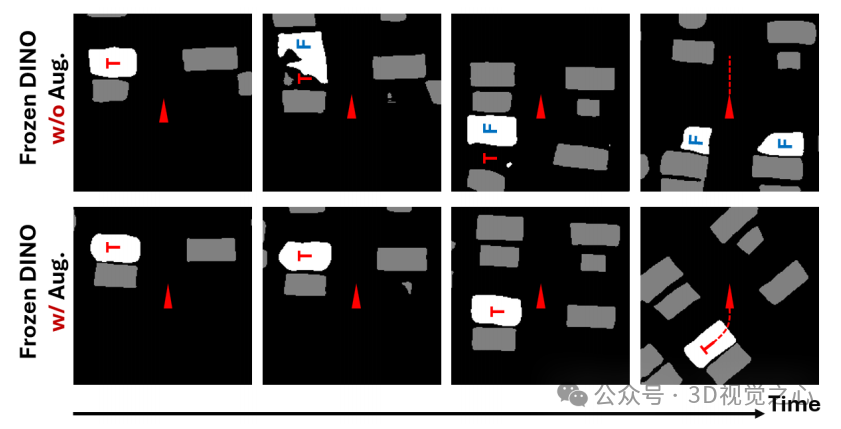
在目标识别任务中,我们发现原始模型在跨域时容易将非目标车位误识别为目标。通过引入重标注数据,模型能稳定识别目标车位,即使在视觉变化下也能保持一致性。
D. 扩散模型与Stanley控制提升规划精度
我们将扩散模型与Stanley控制器结合,替代原有Transformer回归头。实验表明,该组合在大域偏移下成功率提升16%,且轨迹误差更小,验证其在复杂环境下的优势。
E. 表征简化与精度权衡
我们进一步实验发现,仅使用分割图作为条件可提升成功率至100%,但轨迹误差略高。说明简化表征有助于提升鲁棒性,但可能牺牲部分精度。
F. 3D高斯喷溅环境中的零样本测试

我们在由真实停车场重建的3DGS环境中进行零样本测试。尽管存在较大域偏移,系统仍能部分成功完成停车任务,表明其具备一定的 sim-to-real 迁移能力。失败多由分割噪声或目标识别偏差引起,但整体展现出良好的迁移潜力。
结论与未来工作
本文提出了一种新颖的模块化自动驾驶停车系统,结合视觉基础模型、数据增强与扩散模型,实现了跨域零样本迁移能力。实验表明,该系统在CARLA与3DGS环境中均表现优异,为未来实现低成本、高泛化的自动驾驶停车系统提供了新思路。
总结来说,博世用视觉大模型 DINOv2 做“火眼”,扩散模型当“导航”,模块化一招打通晴天到雨雪的停车域 gap,仿真零样本直奔真实车库,成功率稳超 90%。
未来工作方向包括:
引入视频世界模型进一步缩小仿真与现实的差距;
在3DGS环境中收集人类演示数据进行训练;
在真实车辆上部署系统,验证其在多样化场景下的表现。
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、Diffusion Policy、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、各类学习路线等,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









