



点击下方卡片,关注“具身智能之心”公众号
作者丨Jiahan Zhang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
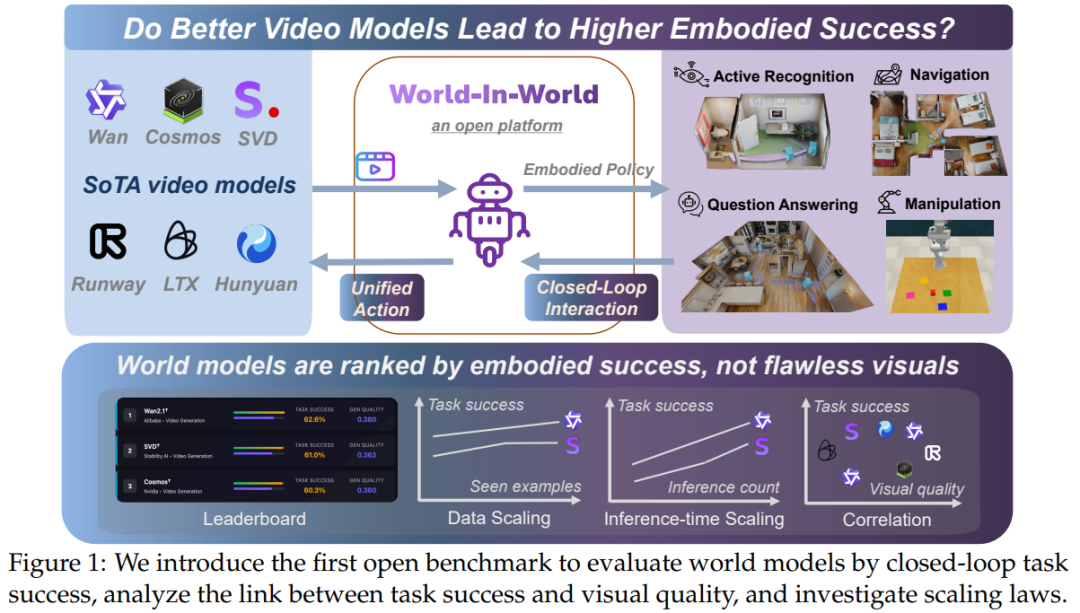
如果你关注过 AI 生成视频的进展,可能会对 Sora 生成的超写实画面或 Wan 系列模型的长视频能力印象深刻——这些技术背后的 “生成式世界模型”,理论上能像人类一样 “预判环境变化”,帮机器人导航、帮机械臂抓取物体。但有个很现实的问题一直没解决:画面越逼真的世界模型,真的能让具身智能体(比如机器人)更好地完成任务吗? 现有的评估基准总盯着 “视频清不清晰”“场景合不合理”,却没人测试这些模型能不能真正帮智能体做决策。于是,约翰・霍普金斯大学、北京大学等团队联合推出了 “World-in-World” 平台,第一次用 “闭环交互” 的方式,让世界模型在真实的具身任务里接受考验,而不是在实验室里比 “画画技巧”。
论文标题:World-in-World: World Models in a Closed-Loop World
论文链接:https://arxiv.org/pdf/2510.18135
Code:https://world-in-world.github.io/
为什么需要重新定义世界模型的评估?
先从一个简单的场景说起:如果让机器人用 “左转→前进” 的动作找目标,A 模型能生成超清晰的画面,但 “左转” 指令下画面却在 “右转”;B 模型画面稍模糊,却能精准跟着动作变场景——你觉得哪个模型能帮机器人找到目标?答案显然是 B,但过去的评估体系只会给 A 打高分。这就是当前的核心痛点:
生成式世界模型的技术已经很成熟了,视频生成能做分钟级、3D 场景能动态变化,甚至能根据动作预测后续画面;但现有评估(比如 VBench 看视频质量、WorldModelBench 看视觉合理性)全是 “开环” 的——模型生成完内容就结束了,没人管它能不能帮智能体完成 “识别物体”“导航到目标” 这类实际任务。更关键的是,具身任务需要的是 “动作和预测对齐”:智能体做 “前进 0.2 米”,模型就得预测出对应距离的场景变化,而不是只顾着把画面画得好看。这种 “视觉质量” 和 “任务有用性” 的脱节,就是 World-in-World 要解决的核心问题。
World-in-World 平台:怎么让世界模型 “实战”?
为了让不同类型的世界模型能在同一个 “考场” 里比 “实战能力”,平台设计了一套完整的闭环体系 —— 简单说就是让智能体、世界模型、环境形成 “观测→决策→执行→再观测” 的循环,每个环节都有标准化规则,确保公平和实用。
先解决 “模型兼容”:统一动作 API
不同世界模型的 “输入语言” 天差地别:有的认文本(比如 “机器人左转 22.5 度”),有的认相机轨迹(比如坐标和角度),有的只认简单动作指令。为了让它们能处理同一个任务,平台设计了 “统一动作 API”,把智能体的原始动作转换成模型能懂的格式:比如把 “前进 0.2 米→左转 22.5°” 转换成文本提示给Hunyuan,转换成相机位姿序列 给 PathDreamer,确保不管模型原本用什么输入,都能接收到一致的 “动作意图”。
再实现 “闭环决策”:从预判到执行的完整流程
平台模仿人类 “想清楚再做” 的逻辑,让智能体和世界模型配合完成决策,具体分三步(如图 3 所示):
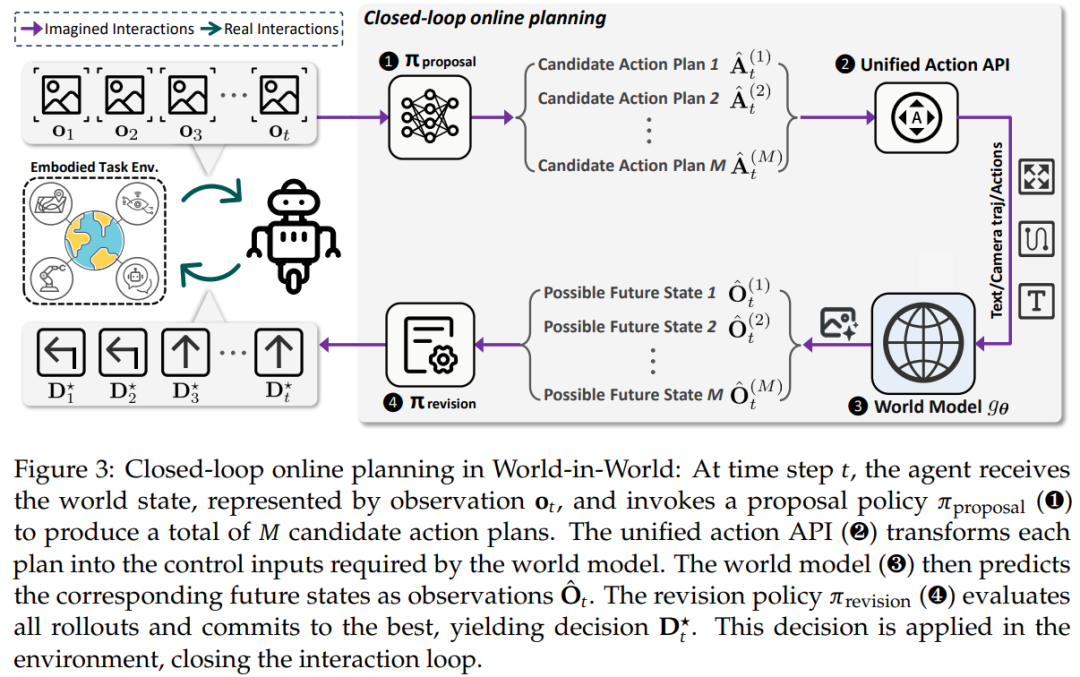
第一步:提方案(提案阶段):智能体根据当前看到的画面( )和任务目标(比如 “找红色沙发”),生成 M 个候选动作序列(比如 “方案 1:左转→前进;方案 2:前进→左转”)。
第二步:做预判(模拟阶段):世界模型根据每个候选方案,预测出执行后的未来画面( )—— 比如 “方案 1” 会生成左转后能看到的场景,“方案 2” 生成前进后的场景。
第三步:选最优(修正阶段):智能体根据任务目标给每个预测打分(比如 “方案 1 的预测里能看到沙发一角,方案 2 看不到”),选最高分的方案执行,然后根据新看到的画面( )开始下一轮循环。
这里有个关键的数学表达能帮我们理解这个过程:在修正阶段,智能体最终选择的最优决策 ,是通过修正策略 对 M 个候选动作 - 预测对 、当前观测 和任务目标g进行评估后得到的,公式如下:
这个公式的核心是:决策不是靠 “拍脑袋”,而是结合了 “候选动作、预测结果、当前情况、任务目标” 四要素,确保每一步都有依据。
最后定 “考试内容”:四类真实具身任务
为了全面测试世界模型的能力,平台选了四类机器人最常遇到的任务(如图 4 所示),每个任务都有明确的 “场景、目标、评分标准”:

主动识别:机器人要在被遮挡或极端视角下认出目标(比如被柜子挡住的花瓶),还得少走路;
图像导航:给机器人一张参考图(比如 “客厅阳台视角”),让它找到拍照的 exact 位置;
具身问答:机器人自己逛环境,然后回答问题(比如 “红色沙发上有几个靠垫”);
机械臂操作:控制机械臂做精细动作(比如 “把红色方块推到蓝色区域”)。
另外,考虑到很多世界模型是 “预训练好的视频生成模型”,平台还设计了 “后训练”:用任务相关的 “动作 - 画面” 数据微调模型——比如用导航场景的 “前进 0.2 米 + 对应画面” 数据微调,让模型更快适应具身任务,而且训练场景和测试场景完全分开,避免 “作弊”。
实验告诉我们什么?核心结论很明确
平台用 12 个主流世界模型做了大量实验,最终的结论推翻了很多 “想当然” 的认知,也给后续研发指了明路:
画面逼真≠任务能成,“动作对齐” 才是关键
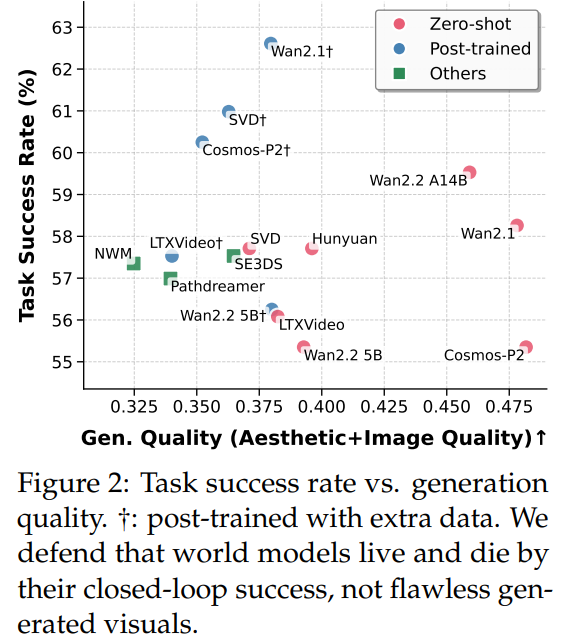
过去总觉得 “画面越好看,模型越好用”,但实验发现完全不是这样。如图 2 所示,有些视觉质量很高的模型(比如 Zero-shot 的 Wan2.1),在主动识别任务里成功率只有 57% 左右;而经过后训练的 SVD†,画面质量中等,成功率却能到 61%。原因很简单:后训练让模型的 “动作 - 预测对齐”(也就是 “可控性”)变好了——比如 “左转” 指令下,模型预测的画面真的是左转后的场景,而不是乱变。
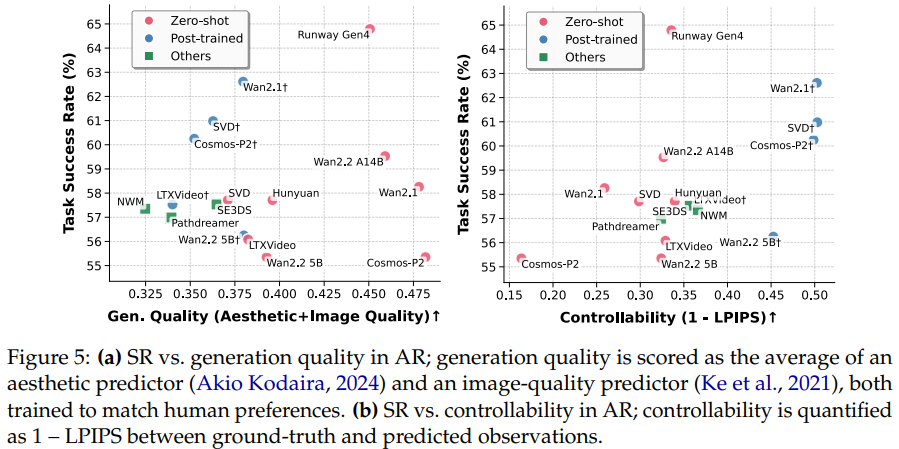
如图 5b 所示,可控性(用 1-LPIPS 衡量,值越高对齐越好)和成功率几乎是正相关的,这说明对具身任务来说,“听话” 比 “好看” 重要得多。
用任务数据微调,比换个更大的预训练模型更划算
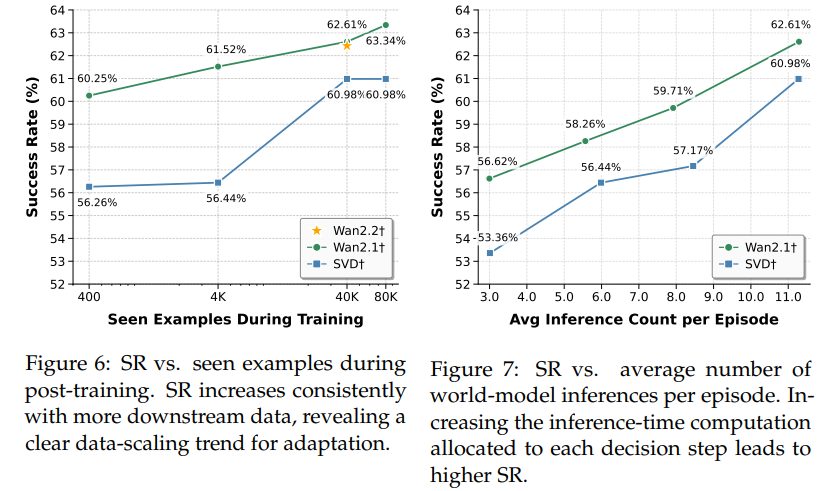
很多人觉得 “模型参数越大越好”,但实验证明,给小模型加任务数据微调,效果比换大模型还好。如图 6 所示,1.5B 参数的 SVD†用 80K 数据微调后,主动识别成功率从 56.3% 升到 61%;而 14B 参数的 Wan2.2†如果不微调,成功率还不如微调后的 SVD†。而且微调成本很低 ——80K 数据的训练成本,只有训练一个新大模型的 1/10 不到,对资源有限的团队来说,这是性价比最高的优化方向。
多花点算力做模拟,任务成功率会明显提升
实验还发现,推理时让模型多 “想几步”(也就是多生成几个候选动作的预测),效果会显著变好。如图 7 所示,主动识别任务里,SVD†的推理次数从 3 次增加到 11 次,成功率从 53.4% 升到 61%;而且多模拟还能让机器人少走路 ——11 次推理的平均路径长度,比 3 次缩短了 12%。这给工程落地提了个醒:只要算力够,让模型多模拟几个可能的未来,决策会更准。
模型在感知、导航上好用,但做机械臂操作还差点意思
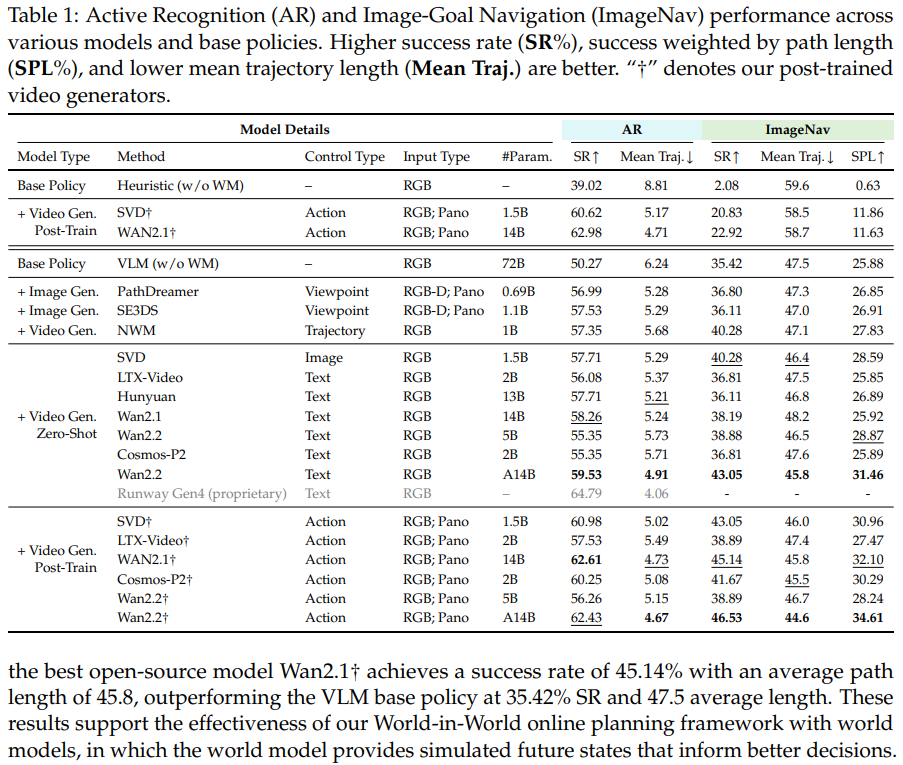
不同任务的表现差距很大:在主动识别和图像导航任务里,最好的模型比没有模型的基础策略,成功率能高 10 个百分点以上;
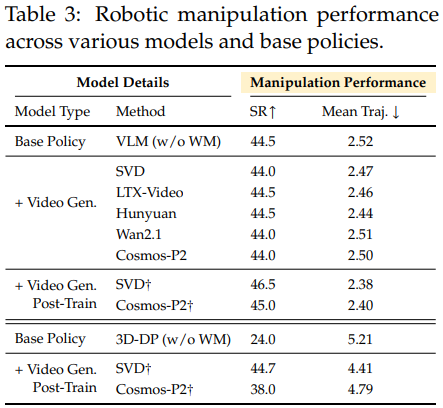
但在机械臂操作任务里,最好的 SVD†成功率也只有 46.5%,只比基础策略高 2 个百分点。问题出在 “物理建模”——操作任务需要精准算碰撞、摩擦力这些物理规则,而当前世界模型只关注视觉生成,没考虑物理规律,预测的画面和实际操作结果对不上,自然帮不上忙。
总结:世界模型该往哪走?
World-in-World 最核心的价值,是把世界模型的评估从 “比画画” 拉回了 “比实用”。未来想让世界模型真正帮上具身智能体,不用再死磕 “画面逼真度”,而是要聚焦三个方向:一是提升 “可控性”,让模型能精准响应动作;二是用少量任务数据做微调,低成本提升效果;三是在操作任务上补 “物理建模” 的短板,让模型懂点 “力学”。只有这样,世界模型才能从 “实验室里的玩具”,变成真正能帮机器人干活的 “大脑”。


















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









