




点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享香港科技大学&地平线最新的工作—DrivingWorld!通过视频GPT构建自动驾驶世界模型。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Xiaotao Hu等
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
最近自回归(AR)生成模型的成功,如自然语言处理中的GPT系列,促使人们努力在视觉任务中复制这一成功。一些工作试图通过构建能够生成逼真的未来视频序列和预测自车状态的基于视频的世界模型,将这种方法扩展到自动驾驶。然而,先前的工作往往产生不令人满意的结果,因为经典的GPT框架旨在处理1D上下文信息,如文本,并且缺乏对视频生成所必需的空间和时间动态进行建模的固有能力。本文介绍了DrivingWorld,这是一个GPT风格的自动驾驶世界模型,具有多种时空融合机制。这种设计能够有效地对空间和时间动态进行建模,从而促进高保真、长持续时间的视频生成。具体来说,我们提出了一种下一状态预测策略来模拟连续帧之间的时间一致性,并应用下一token预测策略来捕获每个帧内的空间信息。为了进一步提高泛化能力,我们提出了一种新的掩码策略和重新加权策略用于token预测,以缓解长期漂移问题并实现精确控制。我们的工作展示了制作高保真、持续时间超过40秒的一致视频片段的能力,这比最先进的驾驶世界模型长2倍多。实验表明,与先前的工作相比,我们的方法实现了卓越的视觉质量和更精确的可控未来视频生成。
开源链接:https://github.com/YvanYin/DrivingWorld
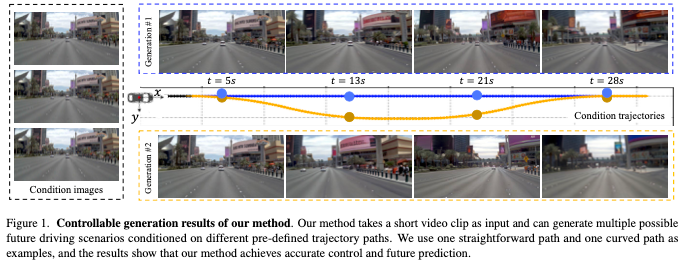
总结来说,本文介绍了DrivingWorld,这是一个基于GPT风格视频生成框架的驾驶世界模型。我们的主要目标是在自回归框架中增强时间一致性的建模,以创建更准确可靠的世界模型。为了实现这一目标,我们的模型结合了三个关键创新:1)时间感知标记化:我们提出了一种时间感知标记器,将视频帧转换为时间相干标记,将未来视频预测的任务重新表述为预测序列中的未来标记。2)混合token预测:我们引入了一种下一状态预测策略来预测连续状态之间的时间一致性,而不是仅仅依赖于下一个token预测策略。之后,应用下一个token预测策略来捕获每个状态内的空间信息。3)长时间可控策略:为了提高鲁棒性,我们在自回归训练过程中实施了随机标记丢弃和平衡注意力策略,从而能够生成具有更精确控制的持续时间更长的视频。DrivingWorld使用AR框架增强了视频生成中的时间连贯性,学习了未来进化的有意义表示。实验表明,所提出的模型具有良好的泛化性能,能够生成超过40秒的视频序列,并提供准确的下一步轨迹预测,保持合理的可控性。
相关工作回顾
世界模型。世界模型捕捉了环境的全面表示,并根据一系列行动预测了未来的状态。世界模型在游戏和实验室环境中都得到了广泛的探索。Dreamer利用过去的经验训练了一个潜在动力学模型,以预测潜在空间内的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









