



端到端之后,学术界和工业界聚焦的方向是什么?无疑是VLA。VLA提供了类人思考的能力,把车辆决策的过程通过思维链的形式展现出来,从而提供更可靠更安全的自动驾驶能力。自动驾驶VLA目前可以分为模块化VLA、一体化VLA和推理增强VLA三个子领域。
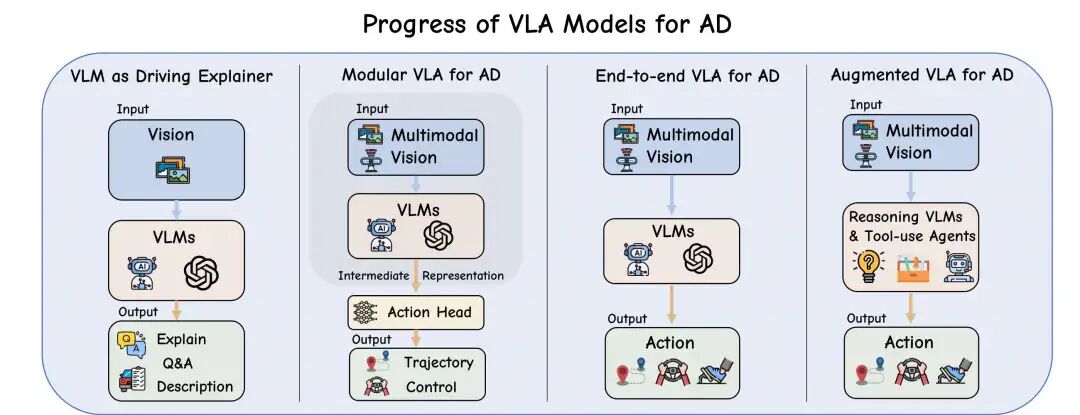
从技术的成熟度及就业的需求来看,自动驾驶VLA是各家企业急需攻克的方案。主流的自动驾驶企业,无论是智驾方案供应商还是车企,都在发力自动驾驶VLA的自研。我们花了三个月的时间设计了一套自动驾驶VLA的学习路线图,从原理到实战细致展开。
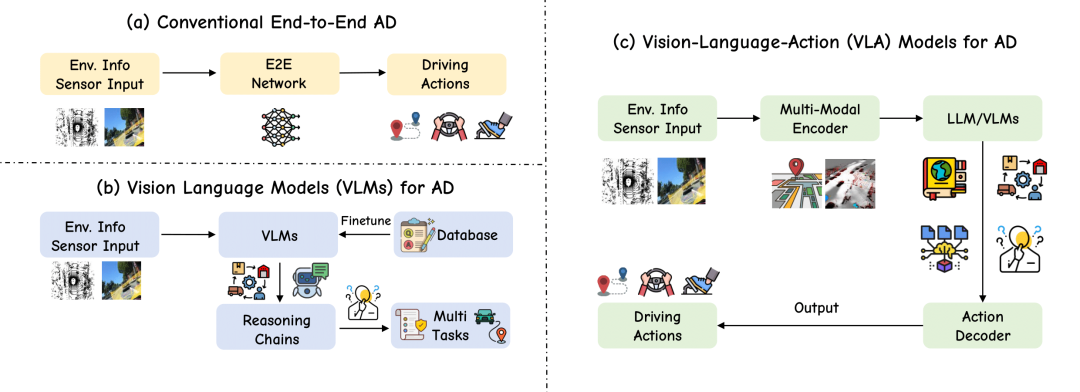
自动驾驶VLA涉及的核心内容包括视觉感知、大语言模型、Action建模、大模型部署、数据集制作等等。最前沿的算法包括CoT、MoE、RAG、强化学习。通过学习VLA,可以让自己对自动驾驶的感知系统有更深刻的认知。
为此我们联合清华大学的教研团队开展了这门《自动驾驶VLA与大模型实战课程》!课程包含自动驾驶VLA三个子领域前沿算法的细致讲解,并会配备两个实战及一个课程大作业深入理解自动驾驶VLA。

讲师介绍
咖喱,清华大学硕士生:在ICCV/IROS/EMNLP/Nature Communications发表论文若干篇。目前从事多模态感知、自动驾驶VLA、大模型Agent等前沿算法的预研,并已主持和完成多项自动驾驶感知和大模型框架工具,拥有丰富的自动驾驶、大模型研发和实战经验。
Max,QS30高校博士在读:在EMNLP、IROS、ICCV、AISTATS等国际顶级会议发表多篇论文,研究方向涵盖多模态大模型与自动驾驶VLA等前沿领域。长期维护GitHub上多个自动驾驶与计算机视觉开源项目,总Star数已超过2k,具备扎实的多模态大模型研发能力与丰富的实战经验。
Eric,清华大学硕士生:在RAL/IROS/EMNLP发表论文若干篇。目前从事在线建图感知、自动驾驶VLA、大模型Agent等前沿算法的预研,拥有丰富的自动驾驶、大模型研发和实战经验。
课程大纲

这门课程讲如何展开
第一章:自动驾驶VLA算法介绍
第一章主要是针对自动驾驶VLA概括性的内容讲解,这一章老师会带大家复盘一下VLA算法的概念及发展历史,并带大家拆解一下自动驾驶VLA这个任务。随后详细介绍目前学术界和工业界有哪些开源的BenchMark和常见的评测指标。学完这一章节,同学们将对自动驾驶VLA这个任务有个整体的了解,方便后续章节的深入学习。
第二章:VLA的算法基础
承接第一章,在对VLA有了概括性的了解后,老师将会带着大家学习VLA相关的算法基础:
视觉感知涉及的BEV感知/动静态检测/OCC及轨迹预测;
语言模型涉及的序列建模/Transformer,以及建立vision-language的模态对齐的算法等;
动作模块的基础知识,判别式解码器和生成式解码器是如何输出action的;
前三个小节聚焦于Vision、Language和Action三个模块的基础知识,第四个小节将展开讲解大模型与自动驾驶VLA如何结合,这个小节会讲到:
涉及prompt engineering和in-context learning的RAG和CoT技术;
监督微调SFT和强化学习RL如何应用到自动驾驶VLA中;
混合专家模型的技术原理及其在自动驾驶中的应用。
前面四个小节已经为大家讲解了VLA算法的核心基础,我们了解到不少同学对大模型的部署和使用很感兴趣,因此我们专门扩展了一个小节讲解常用开源大模型的部署和使用:以Qwen 2.5VL-72为例,如何使用transformers或ms-swift本地部署大模型。
为了更好的让大家理解VLA这个任务,我们设计了自动驾驶VLA数据集制作专题,对有兴趣在VLA这个方向深造的同学十分重要,都是干货!
场景理解QA数据如何设计;
检测Grounding数据如何设计;
Planning数据如何设计;
思维链数据如何设计。
第三章:VLM作为自动驾驶解释器
第三章进入到咱们课程算法部分讲解的部分,自动驾驶VLA这个概念提出以前,VLM大多作为解释器参与到自动驾驶的场景理解中。这个章节我们会讲解几篇经典和最新的算法:DriveGPT4、TS-VLM、DynRsl-VLM、SENNA。重点讲解这些算法的动机、网络结构以及算法核心。目前VLM作为自动驾驶解释器仍然还有很多方向可以探索,很适合有意愿从事自动驾驶VLM/VLA科研学习的同学进一步深入学习。
第四章:模块化&一体化VLA
第四章正式进入到自动驾驶VLA的部分。这一章节聚焦在模块化和一体化VLA这个领域,随着VLA研究的发展,Language从被动的场景描述演变为模块化架构中的主动规划组件。模块化VLA的方法强调多阶段的pipeline(感知→语言→规划→控制),语言模型的输入和输出开始为规划决策提供信息,而不仅仅是对驾驶环境的描述。一体化VLA直接连接动作解码器(如扩散模型或自回归控制器)。省略语言到规划的中间步骤,实现感知→控制的端到端映射。通过单次前向传播,直接将传感器输入(视觉+语言)映射为控制动作(如轨迹或转向指令),消除模块间耦合延迟。这一章节,我们重点讲解:
慕尼黑工大提出的OpenDriveVLA;
上海交通大学提出的DriveMoE;
博世和清华AIR提出的DiffVLA;
UC Berkeley和Waymo中稿CVPR2025的S4-Driver;
第四章配套了实战的代码学习,我们选取了华科和小米最新提出的ReCogDrive!ReCogDrive包含了预训练、模仿学习训练和强化学习训练三个阶段。涵盖了自动驾驶VLA训练的主流范式,非常适合小白学习。ReCogDrive涉及的技术栈包含预训练、模仿学习、强化学习GRPO、扩散模型轨迹输出等等。
第五章:推理增强VLA
第五章则聚焦在推理增强VLA子领域上。自动驾驶大模型的趋势由解释转向了长思维链推理、记忆和交互,将VLM/LLM置于控制的中心。相比之前的算法,新增推理模块(如Chain-of-Thought、记忆体、工具调用),生成决策依据同时,根据决策依据再输出动作。这类方法的特点是行动与解释并行:同步输出控制信号和自然语言解释(如ORION的“QT-Former”记忆体+语言解释)。在端到端控制流中显式嵌入语言推理层,支持长时序规划、因果解释及多模态交互。在这一章节,我们重点讲解:
华科&小米 ICCV2025中稿的ORION;
阿里&西交团队提出的FutureSightDrive;
UCLA提出的AutoVLA;
中科院和华为诺亚提出的Drive-R1;
第五章配套了实战的代码学习,我们选取了清华AIR和博世提出的Impromptu VLA!Impromptu VLA基于开源Qwen2.5 VL进行数据集的制作、训练和推理。非常适合想在通用大模型上研究自动驾驶任务的同学。
第六章:大作业
为了让同学们更好的理解和掌握自动驾驶VLA,第六章的大作业我们从网络构建开始,基于ms-swift框架,自定义数据集和加载模型,开启自己的训练任务并进行微调,并提供V-L-A各部分的代码解读以及可修改优化的demo。这个章节注重的是同学们自己动手实操,对于未来有计划在自动驾驶VLA方向继续深造的硕博,可以重点关注。
学习要求
需要自备GPU,推荐算力在4090及以上;
一定的自动驾驶领域基础,熟悉自动驾驶的基本模块;
了解transformer大模型、强化学习、BEV感知等技术的基本概念;
一定的概率论和线性代数基础,熟悉常用的数学运算;
具备一定的python和pytorch语言基础;
学后收获
这门课程是国内首个自动驾驶VLA进阶实战教程,我们期望能够推动自动驾驶VLA在学术界和工业界中的发展,助力更多想要加入到自动驾驶行业的同学真正理解VLA。
我们期望学完本课程:学完能够彻底理解自动驾驶VLA的当前进展,掌握前沿VLA的算法核心;
掌握VLA的三大子领域:作为解释器的VLM、模块化&一体化VLA及推理增强VLA;
对视觉感知、多模态大模型、强化学习等关键的前沿人工智能技术有更深刻的了解;
可复现VLA主流算法,适用于后续科研学习及工程落地;
能够将所学应用到项目中,真正搞懂如何设计自己的VLA模型;
无论是实习、校招、社招都能从中受益;
课程进度安排
课程开课时间:10.20日,预计两个半月结课。离线视频教学,vip群内答疑+三次线上答疑;
开始解锁时间 | 对应章节 |
|---|---|
10.20 | 第一章 |
10.27 | 第二章 |
11.17 | 第三章 |
12.01 | 第四章 |
12.15 | 第五章 |
12.29 | 第六章 |
课程咨询
早鸟优惠!扫码学习课程

更多内容咨询小助理


















 2772
2772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









