



作者 | 深蓝学院 来源 | 深蓝AI
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
摘要
在大模型飞速发展的当下,让多模态大语言模型(VLM)在自动驾驶场景图像中做出准确的空间推理,依然是人工智能领域的一大挑战。学术界一直缺乏针对自动驾驶场推理的大规模基准,现有方法往往依赖外部专家模型,难以全面衡量模型能力。
与此形成鲜明对比的是,人类可以凭借已有知识轻松判断图像中物体的朝向,或推理多个物体的相对位置。而VLM同样具备丰富的知识,却仍在此类任务上表现不足。
为此,武汉大学联合中科院自动化所,北京智源人工智能研究院 (BAAI)等多家单位推出首个面向驾驶场景的VLM空间推理大规模基准 SURDS,系统评测了包括 GPT 系列在内的通用模型及 SpatialRGPT 等空间推理模型,全面揭示了当前VLM在空间理解方面的短板。研究团队通过设计“感知准确性”和“逻辑一致性”奖励,并结合 SFT 与 GRPO 训练,使得在更少参数量的条件下,模型依然表现出显著增强的空间推理能力。
《SURDS: Benchmarking Spatial Understanding and Reasoning in Driving Scenarios with Vision Language Models》于2025年9月18日被人工智能和机器学习领域的顶级国际学术会议NeurIPS接收。
论文链接: https://arxiv.org/pdf/2411.13112
代码地址: https://github.com/XiandaGuo/Drive-MLLM
1
—
主要方法
本研究提出了SURDS,这是一个大规模基准测试,旨在系统地评估VLM的空间推理能力。SURDS基于nuScenes 数据集构建,包括 41,080 视觉-问答训练实例和 9,250 评估样本,涵盖六个空间类别:方向识别、像素级定位、深度估计、距离比较、左右排序以及前后关系。总体框如下图所示:

图1|SURDS 基准的框架概述©️【深蓝AI】编译
空间推理大规模基准SURDS
这是一个专为自动驾驶研究设计的大规模公开数据集,包含六个摄像头的全景图像、LiDAR、雷达和GPS/IMU等多模态信息。数据采集于波士顿和新加坡的城市环境,涵盖多种交通状况、天气和昼夜场景,保证了测试的多样性与真实感。 为了确保样本清晰、无歧义,本研究设计了一套多阶段的数据筛选流程:首先剔除被严重遮挡的目标;再去除边界外或尺寸过小的目标;最后利用大模型生成描述,排除语义模糊或噪声样本,如下图所示:
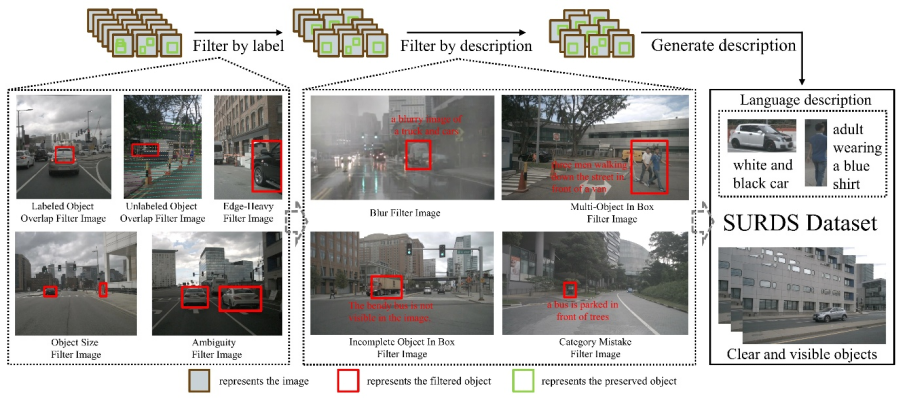
图2|构建SURDS数据集的数据获取流程©️【深蓝AI】编译
经过严格过滤后,最终保留 27,152 张训练图像和 5,919 张验证图像,并生成 41,080 条训练问答对与 9,250 条验证问答对,构成空间推理问答基准。在任务设计上,本研究覆盖了六类空间推理能力。单目标任务包括方向识别、像素级定位以及深度估计,考察模型的基础空间理解。多目标任务则涉及距离比较、左右排序以及前后关系,要求模型处理复杂的目标间空间关系。
后训练对齐:增强空间理解
在提升多模态模型的空间推理能力时,本研究首先关注数据生成。传统的强化学习训练主要依赖模型已有的知识,而小规模模型往往缺乏内在的推理能力,因此需要通过有监督微调(SFT)引入推理知识。由于原始数据集中并不包含思维链(CoT)标注,本研究提出了一条自动化流程来生成高质量的推理思维链,如下图所示:
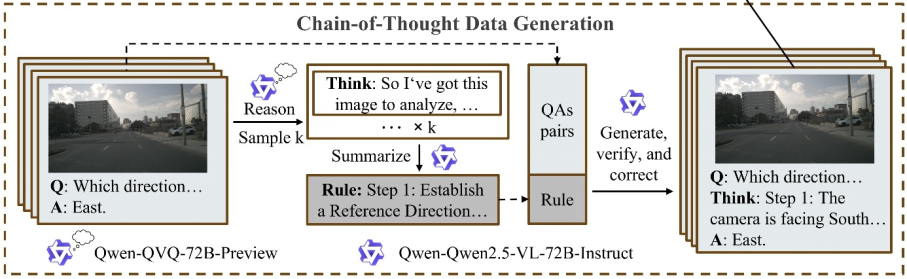
图3|CoT的生成框架©️【深蓝AI】编译
具体而言,先利用视觉推理模型 QVQ 对部分问答对进行推理,再由 Qwen2.5-VL-72B 总结并提炼出可泛化的推理规则,最后结合规则和原始数据生成带有 CoT 标注的新问答数据,并通过模型自校验机制进行筛选与修正。这一过程兼顾效率与质量,解决了直接批量生成推理链成本高、输出冗余不规范,以及单独依赖大模型容易产生幻觉的问题。
在此基础上,本研究进一步进行强化学习训练。首先通过 SFT 完成模型的冷启动,包括视觉编码器、多模态投影层和语言模型的联合训练。随后,引入基于 GRPO 的强化学习框架,要求模型在每次推理中依次生成目标的边界框、逐步的推理过程以及最终答案。训练中设置了多重奖励机制:若预测框与真实区域的交并比较高,给予定位奖励;若输出符合指定格式,给予格式奖励;若最终答案正确,给予准确率奖励。
此外,本研究还设计了逻辑奖励来保证推理链的连贯性。不同于以往依赖外部冻结模型进行一致性判断,本研究仅将推理链输入正在训练的模型,让其自我验证答案是否一致。这种方式降低了额外计算开销,并能随着模型能力提升而动态适应。通过这样的奖励设计,模型在空间推理上的逻辑性与可靠性得到了显著增强,如下图所示:
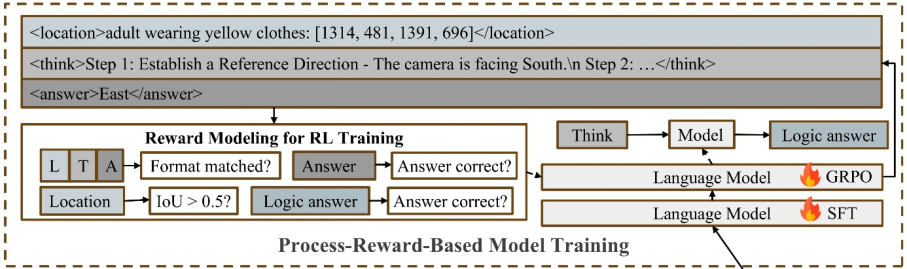
图4| 模型的训练框架©️【深蓝AI】编译
2
—
实验结果
在评测结果中,不同模型在空间推理任务上表现出了明显差异,如下表所示。闭源模型中,Gemini 在多目标任务上表现最好;开源模型里,Qwen 的整体表现也较为突出。而一些被设计为具备空间理解能力的模型,整体表现反而不理想,甚至有的模型因为缺乏指令跟随能力而无法完成部分任务。本研究的模型在多个单目标任务上取得了领先优势,其中深度估计准确率相比第二名提升了近 60%,整体平均分也超过第二名 14.25%,显示出较强的综合性能,如下表所示:
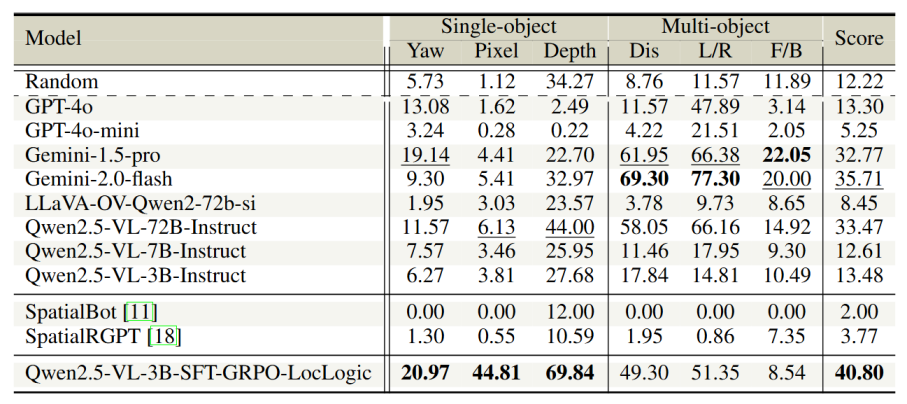
表1|与其他VLM的效果比较
上述结果进一步地揭示了当前模型的局限性。首先,在单目标测试中,大部分模型的准确率接近随机水平,像素级定位甚至很少超过 10%,说明现有模型仍难以学习到绝对的姿态和度量信息。其次,在多目标任务中,模型在简单比较任务(如左右关系、距离比较)上表现稍有提升,但在需要前后方向推理等更复杂情境下,准确率明显下降,说明相对空间推理依然脆弱。第三,从规模分析来看,模型参数量并不是决定空间理解能力的关键,单纯扩大模型规模并不能有效弥补空间推理的不足。
本研究进一步进行了消融实验,以探究奖励机制与训练设计的作用。结果表明,单独加入定位奖励或逻辑奖励提升有限,但当两者结合时,模型的性能有显著提升。这说明定位能力是空间推理的基础,而逻辑监督则进一步增强了推理一致性。
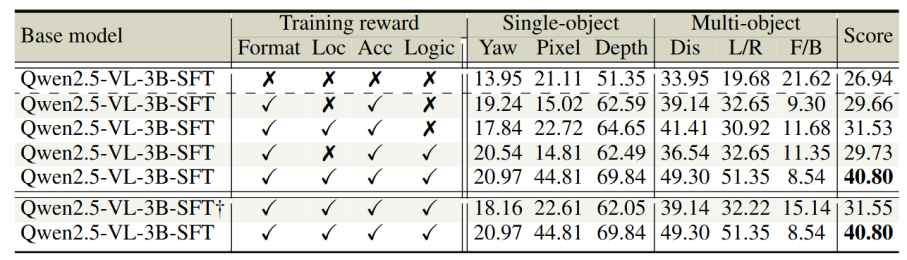
表2|模型奖励消融实验
最后,本研究比较了不同训练策略:无论是否经过 SFT 冷启动,GRPO 强化学习都能提升性能,但只有在 SFT 模型上加入定位和逻辑奖励,才能带来显著的进一步提升,反映了冷启动对模型定位能力的重要作用。
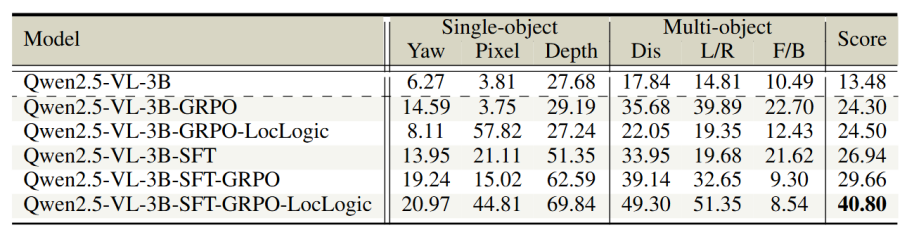
表3|不同训练策略消融实验
3
—
总结
本研究提出了 SURDS 基准,涵盖 41,080 条训练问答对和 9,250 条验证样本,覆盖六类空间推理任务,包括方向识别、像素级定位、深度估计、距离比较、左右排序以及前后关系。对现有通用多模态模型的测试表明,它们在精细空间理解上仍存在明显不足。为此,本研究设计了一套基于强化学习的训练框架,将空间定位奖励与推理一致性目标结合起来。实验结果显示,该方法在多项任务上显著优于现有模型,并通过消融实验验证了训练策略和奖励设计的有效性。目前方法尚未在更大规模模型上验证,线性奖励缩放和多阶段 GRPO 训练等潜在改进方向也有待进一步探索。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









