



点击下方卡片,关注“具身智能之心”公众号
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

每次再聊具身智能时,总能看到很多paper一直说 “突破、创新”。但很少完整地把整个技术路线串起来,让大家清晰地知道具身是怎么发展的?碰到了哪些问题?未来的走向是怎么样的?
机器人操作如何让机械臂精准 “模仿” 人类?多模态融合怎样让智能体 “身临其境”?强化学习如何驱动系统自主进化?遥操作与数据采集又怎样打破空间限制?这些具身智能的关键内容需要我们认真梳理下。
今天我们将会为大家带来领域里比较丰富的几篇研究综述,带你拆解这些方向的发展逻辑。
机器人操作相关
参考论文:The Developments and Challenges towards Dexterous and Embodied Robotic Manipulation: A Survey
论文链接:https://arxiv.org/abs/2507.11840
作者单位:浙江大学、浙江省协同感知与自主无人系统重点实验室
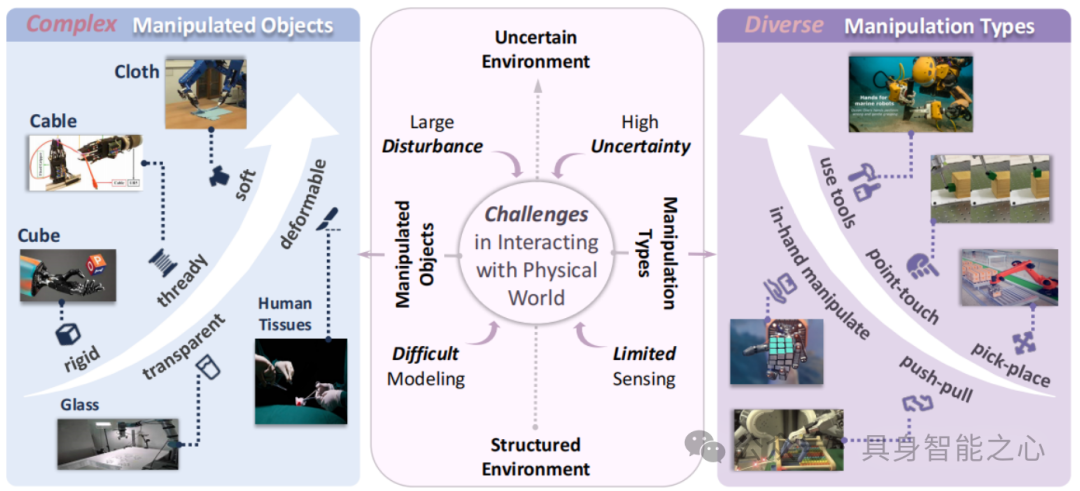
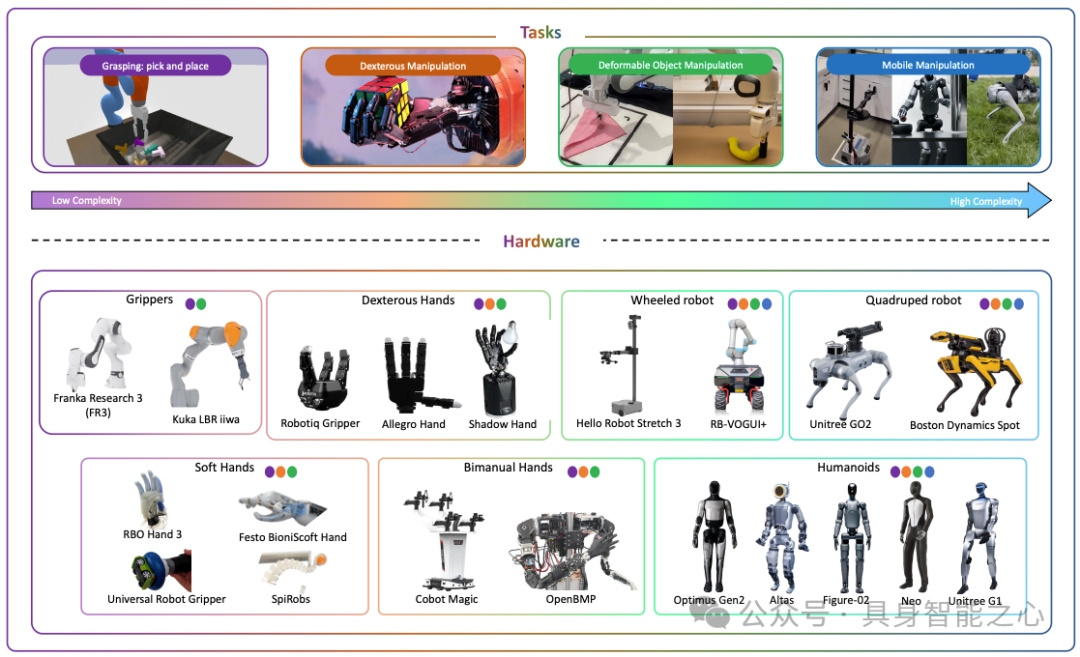
背景与主题:类人灵巧机器人操作是机器人领域关键目标与挑战,人工智能(AI)推动机器人操作快速发展,聚焦其从机械编程到具身智能、从简单夹爪到多指灵巧手的演进。
综述内容:概述机器人操作演进,明确关键特征与主要挑战;聚焦当前具身灵巧操作阶段,突出灵巧操作数据采集(模拟、人类演示、遥操作)和技能学习框架(模仿学习、强化学习 )的最新进展;基于现有数据采集范式和学习框架,总结并讨论灵巧机器人操作发展的三大关键挑战。
核心技术方向:Dexterous Manipulation(灵巧操作)、Multi - fingered Hands(多指手)、AI - Enabled Robotics(人工智能赋能机器人)、Data Collection(数据采集)、Imitation Learning(模仿学习)、Reinforcement Learning(强化学习 )。
具身导航相关
参考论文:A Survey of Robotic Navigation and Manipulation with Physics Simulators in the Era of Embodied AI
论文链接:https://arxiv.org/abs/2505.01458
作者单位:香港城市大学、慕尼黑工业大学、鲁汶大学、汉堡大学
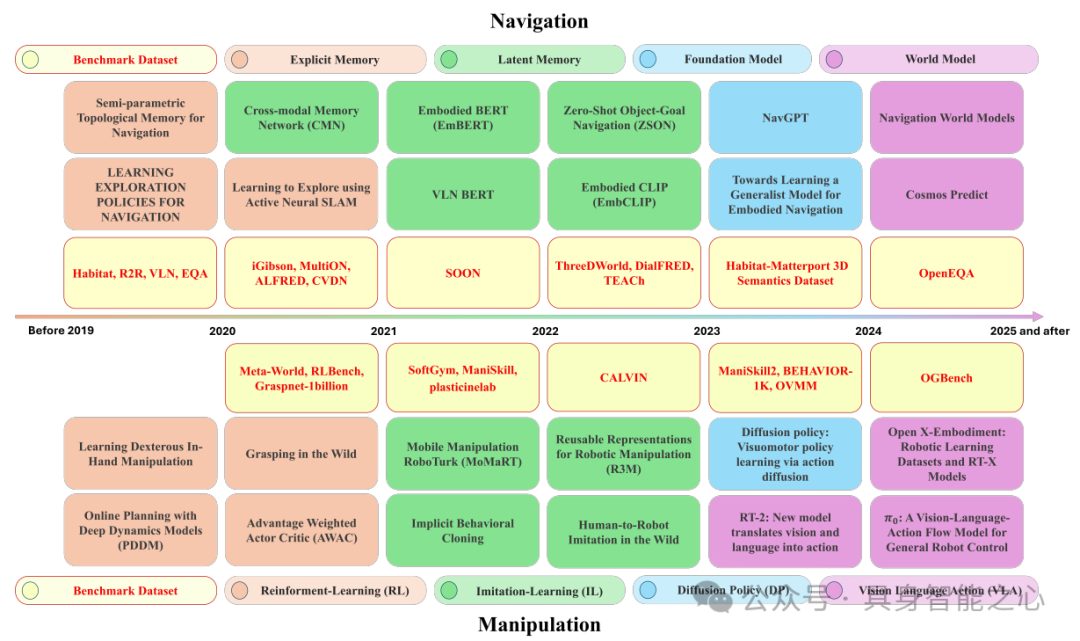
背景与主题:导航与操作是具身智能核心能力,现实训练存在高成本、数据难等问题,Sim-to-Real迁移为关键方案却受域差距制约。本文以物理模拟器为核心,探讨其如何解决机器人导航与操作训练难题,梳理领域从传统方法到数据驱动的演进。
综述内容:
聚焦于具身智能中机器人的导航和操作任务,以及用于支持这些任务训练的物理模拟器。
概述机器人导航与操作的发展历程:导航从显式记忆转向隐式记忆(潜表征、基础模型等),操作从强化学习(RL)拓展至模仿学习(IL)、扩散策略(DP)及 VLA 模型,明确各阶段特征与瓶颈;
聚焦物理模拟器的作用与分类:分析模拟器在缩小 “Sim-to-Real 差距” 中的核心价值,按应用场景将导航模拟器分为室内(如 Habitat、AI2-THOR)、室外(如 CARLA、AirSim)和通用型(如 ThreeDWorld、Isaac Sim),按技术特性将操作模拟器分为经典物理引擎(如 MuJoCo、PyBullet)和可微分物理引擎(如 Dojo、Genesis),对比其物理建模精度与视觉渲染能力。
梳理关键支撑资源与方法:总结导航(如 HM3D、VLN-CE)和操作(如 GraspNet-1Billion、CALVIN)领域的基准数据集,分析导航任务的评估指标(如成功率 SR、路径效率 SPL)与操作任务的感知表示(如 SO (3)/SE (3) 等变表示)、策略学习(如 RL/IL、VLA 模型)方法,最后指出当前领域在高质量数据集、静态学习框架鲁棒性、端到端学习泛化性上的三大挑战及未来研究方向。

核心技术方向:Embodied AI(具身人工智能)、Robotic Navigation(机器人导航)、Robotic Manipulation(机器人操作)、Physics Simulator(物理模拟器)、Sim-to-Real Transfer(模拟到现实迁移)、Reinforcement Learning(强化学习)、Imitation Learning(模仿学习)、Vision-Language-Action (VLA)(视觉 - 语言 - 行动)
具身多模态大模型相关
参考论文:Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions
论文链接:https://arxiv.org/pdf/2502.15336
作者单位:广东人工智能与数字经济实验室(深圳)、深圳大学、巴黎理工学院、中山大学
背景与主题:具身智能以环境物理交互为认知基础,大模型技术推动其与多模态融合形成具身多模态大模型(EMLMs),可弥合感知、认知与动作鸿沟,在机器人等领域价值显著。但现有综述多聚焦传统大模型或广义具身智能,缺乏对EMLMs的系统梳理,故需全面综述其发展、数据集及挑战。
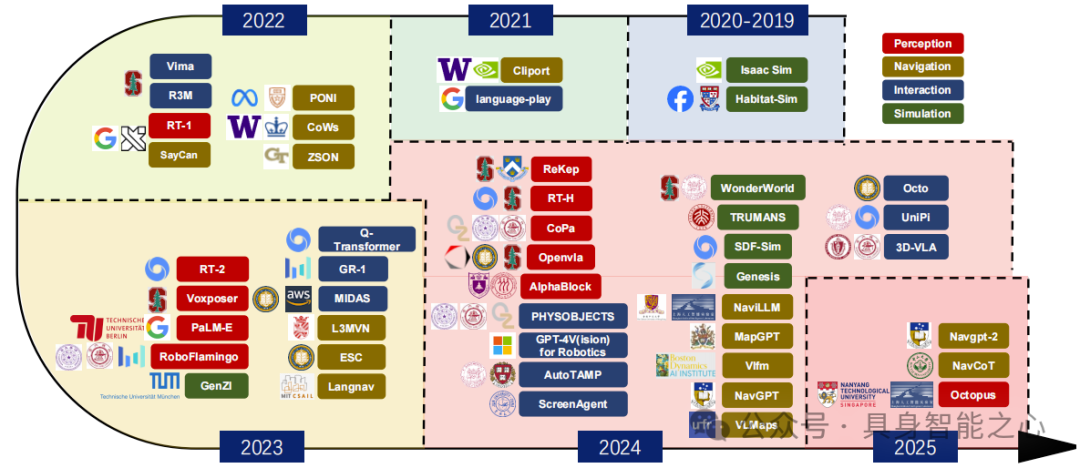
综述内容:
基础模型发展:剖析 EMLMs 的基础构成,分析 EMLMs 构成,包括具身智能体(机器人、自动驾驶汽车等)、LLMs(GPT 系列等)、LVMs(ViT 等)、LVLMs(CLIP 等)及视觉 - 音频 / 触觉等多模态模型。
核心任务进展:围绕具身感知、导航、交互、仿真四大核心任务展开。其中,具身感知(分 GPT 与非 GPT 模型)、导航(分通用与专用模型)、交互(分短 / 长视域动作策略)、仿真(分通用与真实场景模拟器)。
数据集与挑战:总结感知交互(如 Open X-Embodiment)、导航(如 HM3D)类数据集,指出跨模态对齐难、计算资源消耗大、领域泛化性弱、时序信息处理难等技术挑战及数据质量、伦理问题,提出跨模态预训练等未来方向。
核心技术方向:Embodied Multimodal Large Models(具身多模态大模型)、Large Language Models(大语言模型)、Large Vision Models(大视觉模型)、Vision-Language Models(视觉 - 语言模型)、Embodied Perception(具身感知)、Embodied Navigation(具身导航)、Embodied Interaction(具身交互)、Multimodal Datasets(多模态数据集)、Robotic Manipulation(机器人操控)
具身仿真相关
参考论文:A Survey of Embodied AI: From Simulators to Research Tasks
论文链接:https://arxiv.org/pdf/2103.04918
作者单位:南洋理工大学、新加坡科技设计大学、新加坡科技研究局
背景与主题:AI领域正从“互联网AI”向“具身AI”范式转变,具身AI强调智能体通过与环境的第一视角交互学习,但缺乏当代全面综述。本文聚焦9个主流具身AI模拟器,结合7项核心特征评估其性能,同时梳理视觉探索、视觉导航、具身问答三大核心研究任务,填补领域综述空白。
综述内容:
具身 AI 模拟器分析:评估 DeepMind Lab、AI2-THOR 等 9 个模拟器,从 7 项特征(环境构建方式、物理引擎、物体类型、物体属性、控制器、动作能力、多智能体支持)及衍生的 “真实感、可扩展性、交互性” 三维度对比。
核心研究任务梳理:【视觉探索】:智能体通过运动 / 感知构建环境内部模型(拓扑图、语义图等),方法分好奇心驱动(预测误差为奖励)、覆盖最大化(观测区域最大化)、重建驱动(还原未观测区域),核心数据集为 Matterport3D、Gibson V1。【视觉导航】:含点导航(目标坐标)、物体导航(目标类别)、带先验导航(融合语义 / 音频)、视觉 - 语言导航(自然语言指令),主流方法结合强化学习(如 DD-PPO)与经典规划,评估指标以成功率(SR)、路径长度加权成功率(SPL)为主。【具身问答】:需导航与问答结合,分单目标、多目标、交互式问答,需智能体探索环境后推理作答,数据集如 EQA、IQUAD V1,评估兼顾导航误差与问答准确率。
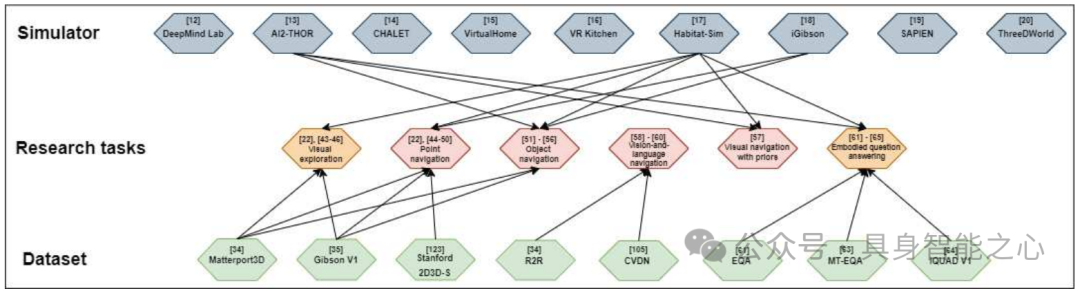
挑战与趋势:模拟器存在真实感(缺高保真 + 高级物理结合的方案)、可扩展性(3D 场景采集成本高)、交互性(精细操作与多状态物体平衡)问题;研究任务面临长轨迹记忆设计、多组件消融难、多智能体研究少等挑战,未来或向 “任务交互式问答(TIQA)” 发展。
核心技术方向:3D Simulators(3D 模拟器)、Visual Exploration(视觉探索)、Visual Navigation(视觉导航)、Embodied Question Answering(具身问答)、Computer Vision(计算机视觉)、Reinforcement Learning(强化学习)、Multi-agent Systems(多智能体系统)
强化学习相关
参考论文:Reinforcement Learning in Vision: A Survey
论文链接:https://arxiv.org/pdf/2508.08189
项目链接:https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning
作者单位:新加坡国立大学、浙江大学、香港中文大学
背景与主题:RL在大语言模型(如RLHF优化的InstructGPT)中成效显著,近年拓展至视觉多模态领域(视觉-语言、生成、具身动作模型等),但面临高维视觉输入、复杂奖励设计等挑战,且缺乏系统综述。
综述内容:
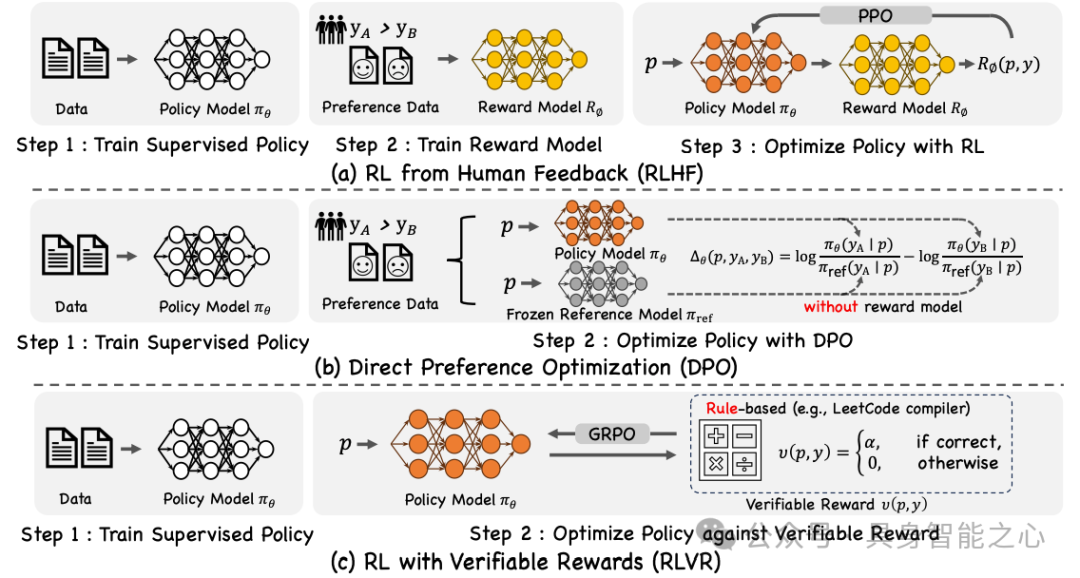
基础理论与优化策略:将视觉生成视为马尔可夫决策过程,涵盖 RLHF、DPO、RLVR 三大对齐范式,及 PPO(价值网络降方差)、GRPO(组内基准简化计算)两种策略优化算法,均通过 KL 正则约束政策偏移。
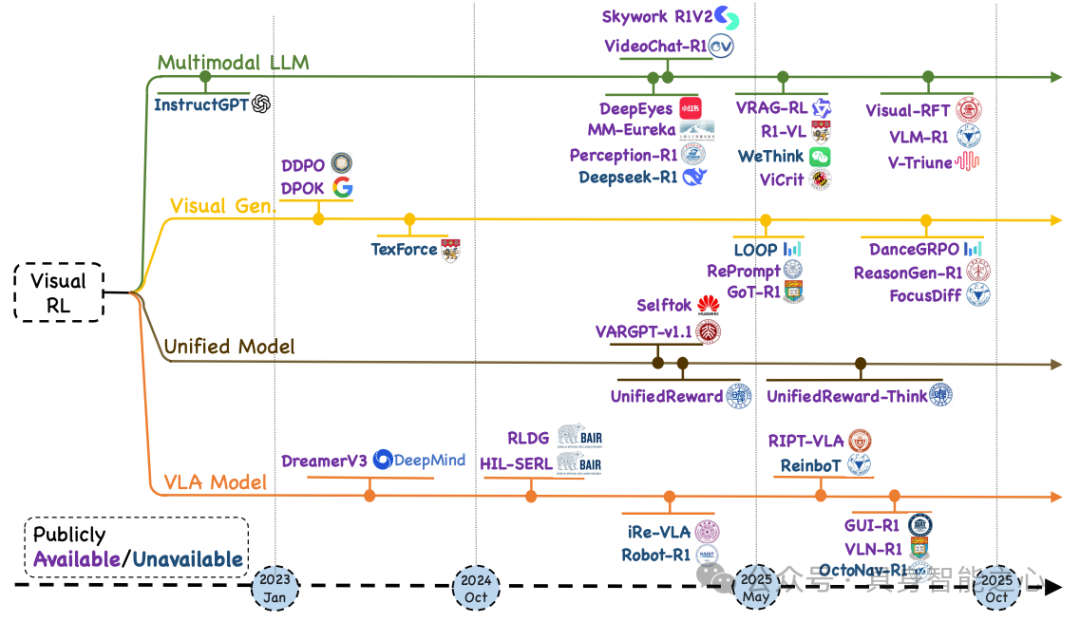
核心研究方向:多模态大语言模型(用 RL 提升跨模态一致性)、视觉生成(RL 优化生成质量与 prompt 对齐)、统一模型(统一 RL 跨任务迁移 / 任务特定 RL 单任务优化)、视觉 - 语言 - 动作模型(RL 优化长序列动作决策)。
评估体系与潜在挑战:评估分集合级(FID)、样本级(RLHF 奖励)、状态级(KL 监控),配套 SEED-Bench-R1 等 benchmarks;挑战含长序列奖励稀疏、生成奖励泛化弱,未来需探索分层 RL 与自适应奖励。
核心技术方向:Reinforcement Learning (强化学习)、Visual RL (视觉强化学习)、Multimodal Large Language Models (多模态大语言模型)、Visual Generation (视觉生成)、Vision-Language-Action Models (视觉 - 语言 - 动作模型)、RLHF (基于人类反馈的强化学习)、Policy Optimization (策略优化)、Unified Model (统一模型)
遥操作与数据采集
参考论文:Teleoperation of Humanoid Robots: A Survey
论文链接:https://arxiv.org/pdf/2301.04317
项目链接:https://humanoid-teleoperation.github.io/
作者单位:意大利技术研究院、佛罗里达人类与机器认知研究所、东京理工大学等
背景与主题:人形机器人遥操作可结合人类认知与机器人物理能力,适配人类环境与危险场景(如核救援、空间探索),但受高自由度动力学、非结构化环境、通信限制等挑战制约。
综述内容:
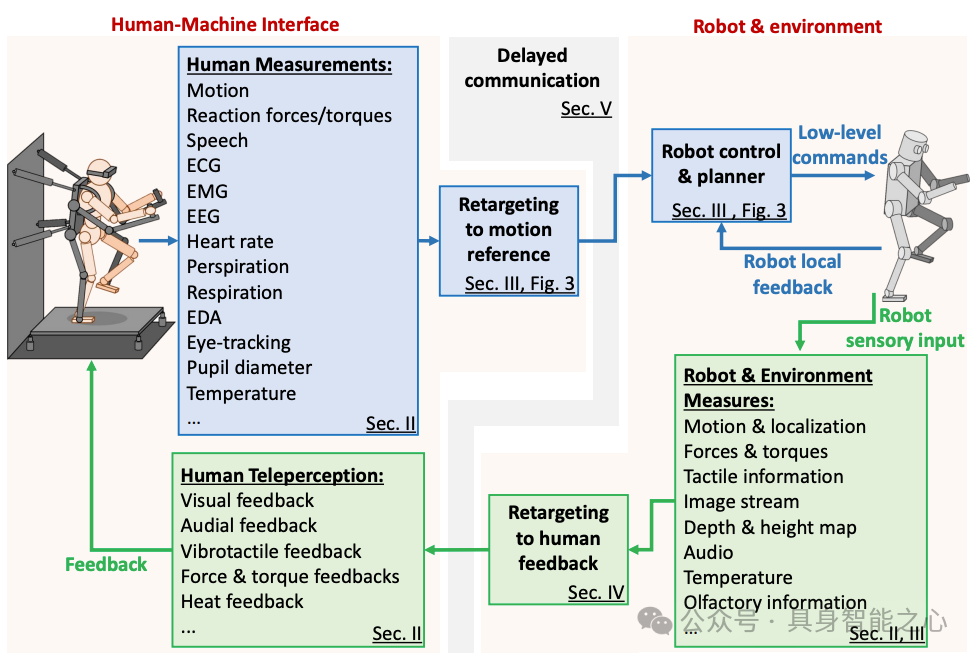
系统与设备:架构含人类状态测量(IMU、外骨骼等测运动,EMG/EEG 测生理)、运动重定向、机器人控制、多模态反馈(视觉 VR、触觉力反馈),支持单向 / 双向遥操作。
重定向与控制:用完整动力学模型与简化模型(LIPM),通过 ZMP/DCM 保证平衡,分 GUI 路径规划、上下肢 / 全身运动重定向,结合 QP 优化的全身控制与底层关节控制。
辅助策略:共享控制融合人机指令,监督防护系统防危险,双边遥操作传递力反馈实现动态耦合。
通信与评估:用 “移动 - 等待”、波变量法处理通信延迟,通过 SUS、NASA-TLX 等量表评估可用性与负荷。
应用与挑战:应用于远程存在、危险作业等,挑战集中在非专家操作门槛、动态环境适应、长延迟稳定性。
核心技术方向:Humanoid Robot(人形机器人)、Teleoperation(遥操作)、Motion Retargeting(运动重定向)、Bilateral Teleoperation(双边遥操作)、Shared Control(共享控制)、Communication Delay(通信延迟)、Human-Machine Interface(人机接口)
VLA大模型
参考论文:Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
论文链接1:https://arxiv.org/pdf/2505.04769
作者单位:康奈尔大学、香港科技大学等
综述内容:系统综述视觉-语言-动作(VLA)模型,从概念基础、发展进展、应用场景到挑战展开分析。梳理 VLA 模型从跨模态学习架构到融合视觉语言模型(VLMs)、动作规划器和分层控制器的通用智能体的演化历程,涵盖 80 多个近三年发布的 VLA 模型,详述其架构创新、参数高效训练、实时推理加速等关键进展,探讨在类人机器人、自动驾驶、医疗与工业机器人、精准农业、增强现实导航等领域的应用,分析实时控制、多模态动作表示、系统可扩展性等核心挑战,并提出智能体 AI 自适应、跨实体泛化等针对性解决方案,最后展望 VLA 与 VLMs、智能体 AI 融合的未来路线图。
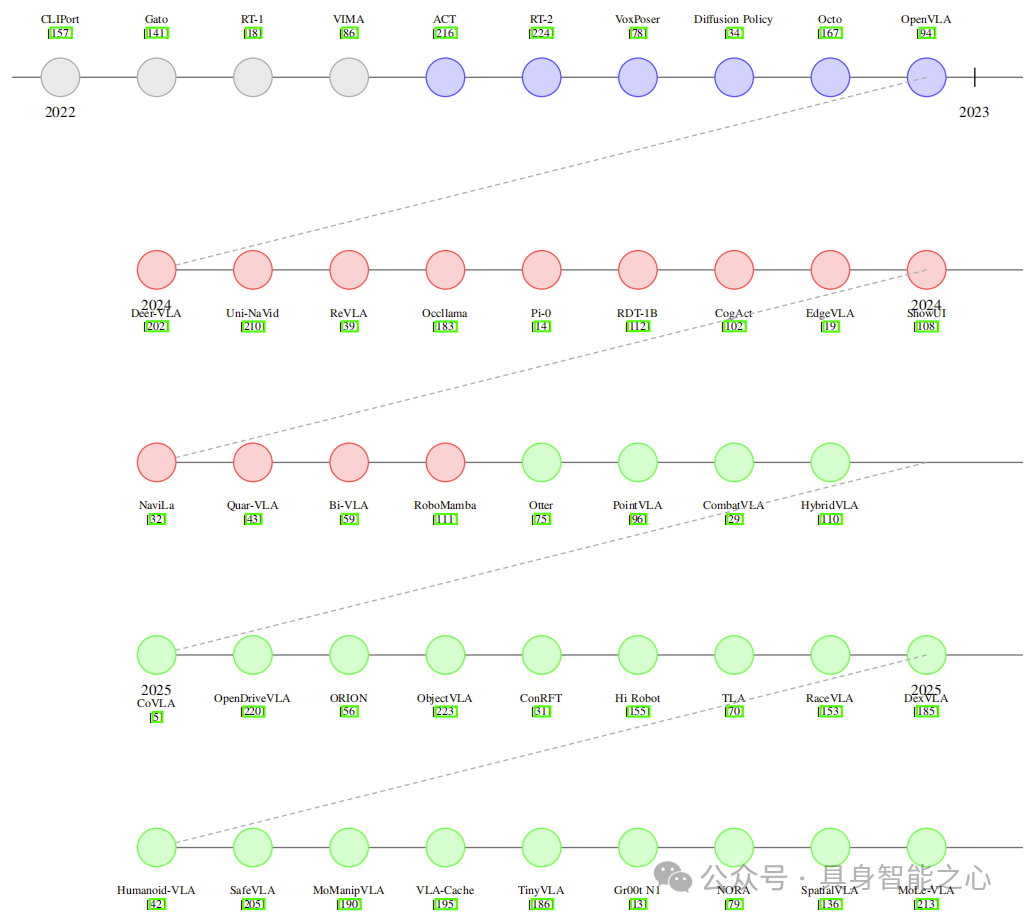
参考论文2:Vision Language Action Models in Robotic Manipulation: A Systematic Review
论文链接:https://arxiv.org/pdf/2507.10672
作者单位:哈利法大学、加泰罗尼亚理工大学
综述内容:聚焦 VLA 模型在机器人操作与指令驱动自主性领域的应用,系统分析 102 个 VLA 模型、26 个基础数据集及 12 个仿真平台。将 VLA 模型按架构范式分类,提出基于任务复杂度、模态多样性和数据集规模的新型数据集评估标准,构建语义丰富度与多模态对齐的二维数据集表征框架,评估仿真平台在大规模数据生成、虚实迁移及任务支持方面的效能,识别架构、数据集、仿真层面的挑战,明确可扩展预训练协议、模块化架构设计等未来研究方向,并提供含 VLA 模型、数据集和模拟器的公开仓库作为参考。
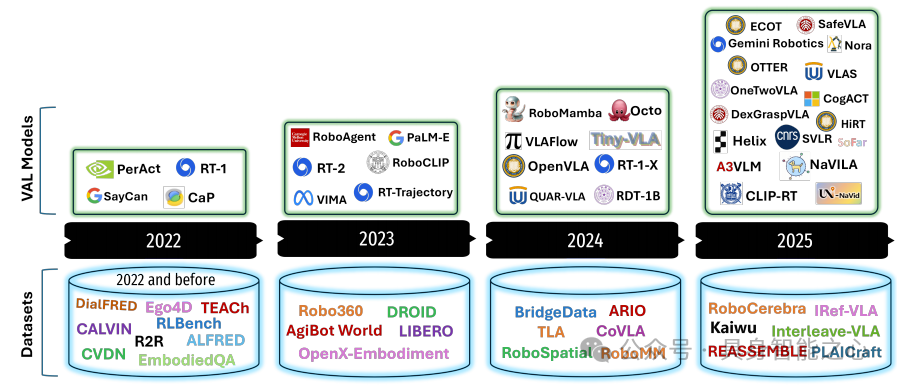
参考论文3:Survey of Vision-Language-Action Models for Embodied Manipulation
论文链接:https://arxiv.org/pdf/2508.15201
作者单位:中国科学院自动化研究所、北京中科慧灵机器人技术有限公司
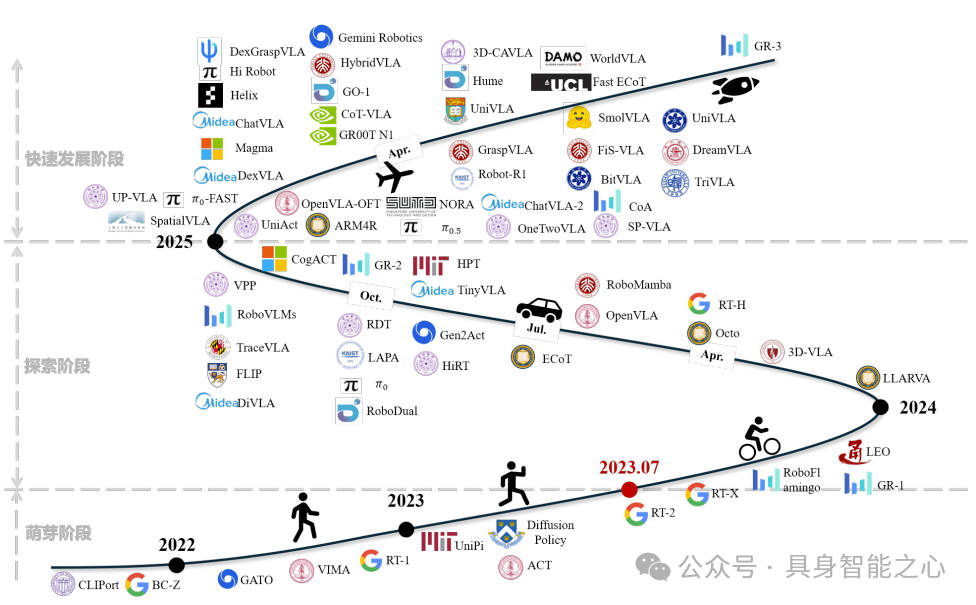
综述内容:从具身智能视角综述面向具身操作的 VLA 模型,将其发展历程划分为萌芽(功能相似模型出现,未形成 VLA 概念)、探索(架构多样,确立 Transformer 为核心骨干)、快速发展(架构向多层演进,多模态 VLA 崭露头角)三阶段。从模型架构(观测编码、特征推理、动作解码、分层系统)、训练数据(互联网图文、视频、仿真、真实机器人数据)、预训练方法(单一领域、跨域分阶段、跨域联合、思维链增强)、后训练方法(监督微调、强化微调、推理扩展)、模型评估(真实环境、仿真器、世界模型评估)五个维度剖析研究现状,最后总结 VLA 发展及机器人操作落地面临的挑战与未来方向。
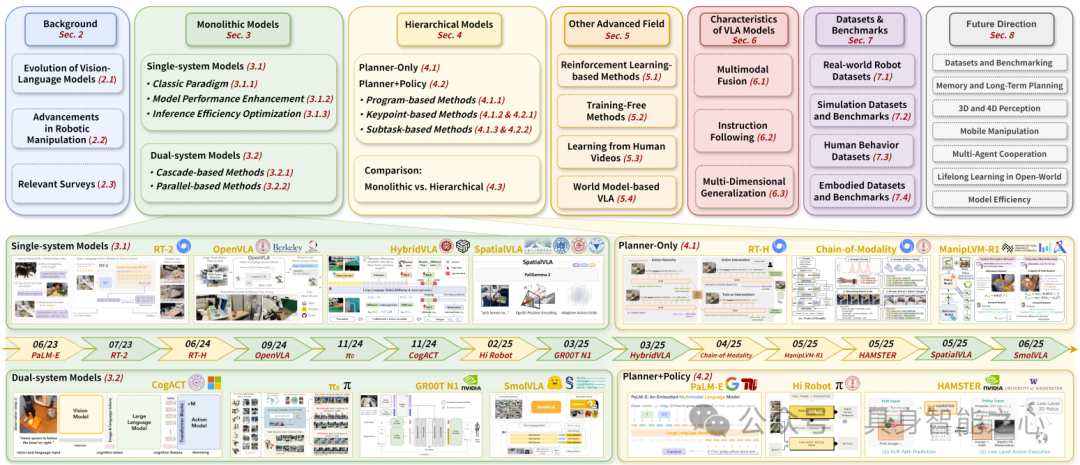
参考论文4:Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
论文链接:https://arxiv.org/pdf/2508.13073
项目链接:https://github.com/JiuTian-VL/Large-VLM-based-VLA-for-Robotic-Manipulation
作者单位:哈尔滨工业大学(深圳)
综述内容:系统回顾VLM的进化历程、机器人操作学习的技术进展及VLA范式的诞生,明确单体模型(Monolithic)与分层模型(Hierarchical)的发展路径,识别关键挑战并展望未来方向。横向整合VLA建模实践:提出更精细的VLA模型分类体系(单体/分层),从结构与功能双维度深入分析两类模型,探索强化学习融合、无训练优化等前沿方向,总结支撑模型发展的数据集与核心特性。
参考论文5:Survey on Vision-Language-Action Models
作者单位:哈萨克斯坦触觉机器人实验室
综述内容:系统梳理了 VLA 模型的技术框架(从 VLM/LM 基础到真实世界评估),适合作为 VLA 领域的入门资料。其核心价值在于验证 “AI 自动化学术综述” 的可行性,同时指出 AI 生成内容的改进方向(准确性、可信度);对于研究人员,可重点参考其数据集梳理、评估指标体系,以及 “混合数据训练” 的实践结论,为后续 VLA 模型的设计与落地提供借鉴。
从操作实践到理论突破,具身智能的拼图仍在完善。这场关于 “让智能具身、让机器懂行” 的探索,没有终点,只有待解的新题。而答案,永远在前行的路上。
如果您需要进一步学习和提升研究能力,欢迎了解我们的开学季活动。


















 4992
4992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









