





点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享上海期智研究院、理想、同济和清华团队最新的工作—DriveAgent-R1!自动驾驶Agent时代来临,以混合思维和主动感知推动基于VLM的自动驾驶发展。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群加入,也欢迎添加小助理微信AIDriver005
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Weicheng Zheng等
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
DriveAgent-R1 是一款为解决长时程、高层级行为决策挑战而设计的先进自动驾驶智能体。当前VLM在自动驾驶领域的潜力,因其短视的决策模式和被动的感知方式而受到限制,尤其在复杂环境中可靠性不足。
为应对这些挑战,DriveAgent-R1 引入了两大核心创新:
混合思维 (Hybrid-Thinking) 框架: 智能体能够根据场景复杂度,智能地在高效的纯文本推理和深入的工具辅助推理之间自适应切换。
主动感知 (Active Perception) 机制: 配备了强大的视觉工具箱,使智能体能够主动探查环境以解决感知不确定性,从而提高决策的可解释性、透明度与可靠性。
我们设计了一种新颖的三阶段渐进式强化学习策略,创新提出模式分组GRPO(MP-GRPO),强化DriveAgent-R1的双模式特异性能力,为后续智能体的自由探索奠定基础。大量实验证明,DriveAgent-R1 取得了当前最佳性能(SOTA),甚至超越了如 Claude Sonnet 4 等顶尖的多模态大模型。消融实验充分验证了我们训练方法的有效性,并证实了智能体的决策是基于主动感知的视觉驱动,推动了更安全、更智能的自动驾驶。
关键词: 自动驾驶、Agent、视觉语言模型 (VLM)、混合思维、多模态思维链 (M-CoT)、强化学习
论文链接:https://arxiv.org/abs/2507.20879
研究动机与核心挑战
让自动驾驶智能体像人类一样主动“观察”与“思考”
人类驾驶员在面对复杂或不确定的路况时,其行为远非简单的“看到-反应”模式。我们的决策过程是一个主动的、探索性的过程。例如:
在夜间或恶劣天气下行驶时,我们会更加专注地观察,试图从模糊的视野中辨认远处的路标、信号灯或潜在障碍物。
准备在繁忙路口右转时,我们不会只依赖主视野,而是会主动、反复地查看右后视镜和侧窗,确保盲区安全,并预测其他车辆的动向。
遇到前方有施工或事故警示牌时,我们会放慢速度,主动寻找绕行路线或观察交警的指挥手势。
这种“主动寻求信息以消除不确定性”的能力,是人类驾驶员安全、可靠行驶的关键。然而,当前的自动驾驶VLM在很大程度上缺乏这种能力。它们主要面临两大核心挑战:
决策短视 (Myopic Decision-Making): 现有方法(如AlphaDrive)大多专注于单步的动作预测,缺乏对未来数秒内的连贯、长时程规划能力。这就像一个驾驶员只考虑下一秒踩油门还是刹车,而没有一个完整的“通过路口”的计划。
感知被动 (Passive Perception): 模型通常被动地接收固定的、低维度的文本指令(如速度、导航)和高维度的视觉信息。在规划任务中,模型很容易忽视丰富的视觉细节,形成“视觉忽略” (visual neglect)。它们无法像人类一样,在感觉“看不清”或“不确定”时,主动地去“再看一眼”或“凑近点看” 。
因此,我们的核心任务是:赋能智能体进行长时程、高层级的行为决策,同时,当面临不确定性时,能像人类驾驶员一样主动地从环境中寻求关键信息。
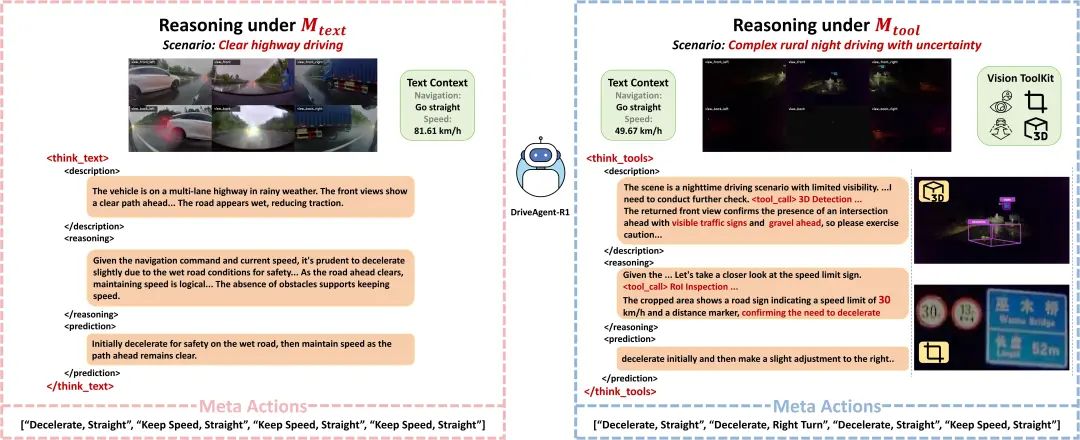
上图生动展示了DriveAgent-R1在面对不同场景的两种思考过程。在一个视线较为清晰的公路上行驶时,DriveAgent-R1准确判断初始输入已经提供了充足的视觉信息,并采用<think_text>模式依赖纯文本做出最终决策。而在一个光线条件较差,充满不确定的乡村夜间道路中,智能体主动调用了“3D Object Detection”和“RoI Inspection”工具,以获取前方道路碎石块和限速标志的关键视觉信息,从而做出了更安全、更有依据的减速决策。
核心创新点
业界首个基于强化学习的智能思维架构: 我们首次在自动驾驶智能体中实现并提出了混合思维架构。DriveAgent-R1能够根据驾驶场景的复杂度,在高效的纯文本多模态思维链 Text-based M-CoT和基于视觉工具辅助多模态思维链 Tool-based M-CoT之间自适应切换,从而智能地适应不同的驾驶场景。
引入主动感知概念: 我们将“主动感知”的概念引入到基于VLM的自动驾驶中,为智能体配备了一个强大的视觉工具箱,使其能够在不确定的环境中主动探索,显著增强其感知鲁棒性。
完整的三阶段渐进式训练策略: 我们设计了一套完整的、以强化学习为核心的三阶段渐进式训练策略,并建立了一套全面的评估体系,用以评估模型的预测准确性、推理质量和自适应模式选择能力。
在挑战性数据集上取得SOTA性能: 在极具挑战性的SUP-AD数据集上,我们的方法取得了SOTA性能,甚至超越了如Claude 4 Sonnet,Gemini2.5 Flash 等前沿多模态大模型 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









