



点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享一篇被ICCV 2025接收的多模态模型相关工作。本文提出了 Talk2DINO ,旨在解决开放词汇分割(OVS)任务中视觉 - 语言模型空间定位能力不足与自监督视觉模型缺乏语言整合的问题。如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→大模型技术交流群
本文只做学术分享,如有侵权,联系删文
论文标题:Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation
论文作者:Luca Barsellotti等
作者单位:意大利摩德纳和雷焦艾米利亚大学等
论文链接:https://arxiv.org/pdf/2411.19331
开源链接:https://lorebianchi98.github.io/Talk2DINO/
背景与动机
开放词汇分割(Open-Vocabulary Segmentation, OVS) 是计算机视觉领域的一项基础任务,其目标是根据推理时提供的自然语言概念,将输入图像分割成一系列连贯的区域。与传统分割任务不同,OVS所使用的概念集合通常以自由形式的自然语言提供,这使得相关方法摆脱了仅依赖训练时给定的特定固定类别集合的限制。要完成这一任务,需要对图像像素与自然语言所传达含义之间的语义关联有细粒度的理解。
在OVS领域,以往的研究多采用像素级标注作为监督信息,但近年来,利用最先进的骨干网络所学习到的相关性,以无监督方式解决该问题成为一种趋势。对比性嵌入空间(如CLIP)在需要整体理解视觉和语言模态的任务中表现出良好性能,因此被应用于无监督OVS。然而,基于CLIP的骨干网络虽然具有强大的跨模态能力,但它们主要是为了预测文本和图像之间的全局相似度分数而训练的,这限制了其空间理解能力,进而影响了基于密集预测的任务表现。尽管已有研究通过引入架构修改来解决这一限制,但训练方式带来的空间理解约束仍然阻碍了这些骨干网络在OVS中的有效性,这凸显了探索具有更强感知能力的替代模型的潜在价值。
自监督纯视觉骨干网络(如DINO和DINOv2) 在无需标注数据的情况下,展现出捕捉细粒度和局部空间特征的显著能力。这类骨干网络中的自注意力机制生成的注意力图能够持续定位图像中的相关区域,因此被广泛用于前景目标分割。然而,视觉自监督网络所产生的嵌入空间与文本概念并非固有对齐 ,这使其与OVS任务不兼容。
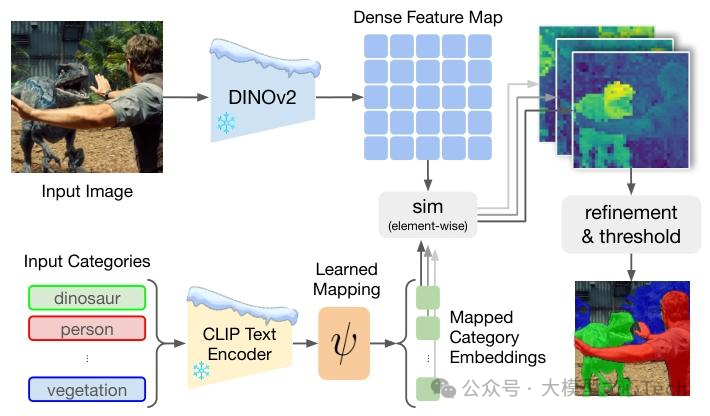
正是由于现有的视觉-语言模型(如CLIP)在空间定位方面存在挑战,而自监督视觉模型(如DINOv2)虽在细粒度视觉编码方面表现出色却缺乏与语言的整合,两者之间存在明显的差距。为了弥合这一差距,研究人员提出了Talk2DINO方法,旨在结合DINOv2的空间准确性和CLIP的语言理解能力,实现高度本地化的多模态图像理解,从而推动OVS任务的发展。
核心创新
提出了Talk2DINO模型,这是首个直接对齐DINOv2和CLIP特征空间以用于OVS的模型。通过使用非线性扭曲函数将CLIP的文本嵌入映射到DINOv2空间,Talk2DINO有效地为DINOv2赋予了语言属性。
所提出的模型采用了一种新颖的训练模式,该模式能够选择最相关的视觉自注意力头,并且不需要对骨干网络进行微调,在仅学习少量参数的情况下实现了良好性能。
展示了Talk2DINO在无监督OVS中的能力,设计了计算高效的推理管道,其中包含了一种基于DINOv2自注意力的背景清理新方法,提升了分割效果。
本文首发于大模型之心Tech知识星球,硬核资料在星球置顶:加入后可以获取大模型视频课程、代码学习资料及各细分领域学习路线~

核心方法细节
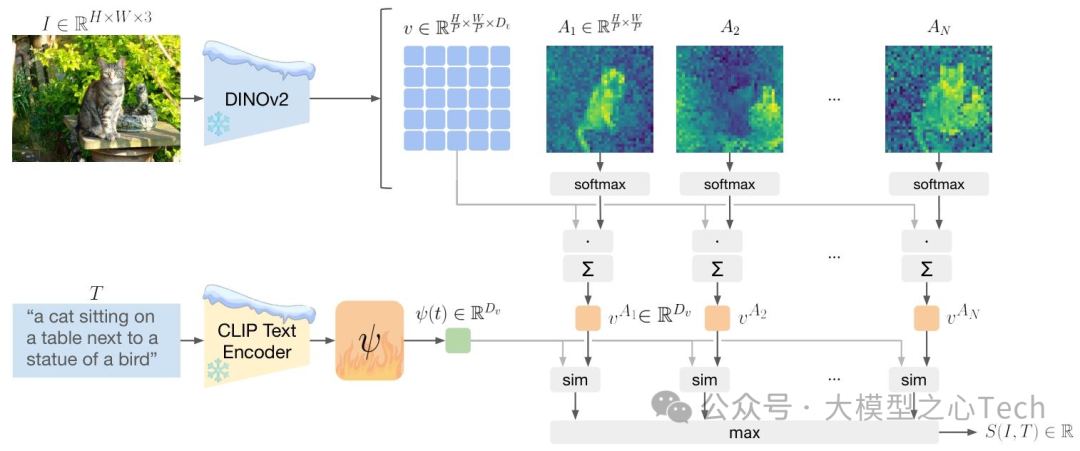
Talk2DINO的核心方法围绕着将CLIP的文本嵌入空间与DINOv2的视觉嵌入空间进行对齐,并利用DINOv2的注意力机制来提升分割性能,具体细节如下:
基本任务定义与前提
开放词汇分割任务中,设图像 ,其由基于Transformer的视觉骨干网络提取的密集特征图为 (输入补丁大小为P,嵌入空间维度为 );设任意文本类别集合为 ,其由预训练文本骨干网络提取的嵌入为 。在多模态设置中,若 ,图像I和类别 的相似度图 定义为文本嵌入 与每个空间位置的视觉特征 的余弦相似度,通过上采样可得到全分辨率相似度图 ,分割掩码则通过将像素分配给具有最高相似度分数的类别得到。这一过程要求视觉和文本的嵌入空间不仅维度相同,还需具有相同的语义。
CLIP和DINOv2存在对偶性,CLIP等视觉-语言模型能自然适应上述公式,但其在文本特征与空间补丁特征的精确对齐方面存在不足;而DINOv2等纯视觉自监督骨干网络的空间嵌入具有显著的语义和局部一致性,但缺乏与自然语言的有效连接,无法直接用于上述相似度计算。研究表明,CLIP的文本嵌入空间可通过可学习的非线性扭曲和仿射变换投影到DINOv2空间。
增强DINO的语义:CLIP嵌入空间的扭曲与映射
为将文本嵌入映射到DINOv2的视觉补丁嵌入空间,学习了一个投影 ,该投影通过将两个仿射变换与双曲正切激活函数组合而成,公式为 ,其中 和 是可学习的投影矩阵, 是可学习的偏置向量。
为学习该非线性投影 ,利用DINOv2固有的分割能力来确定视觉补丁特征中与 应对齐的精确空间子集。首先从DINOv2的最后一层提取N个注意力图 (每个对应一个注意力头),每个 能突出图像中不同的语义区域。对于每个注意力图 ,通过对特征图进行加权平均计算出视觉嵌入 ,其中权重为注意力图经softmax处理后的值,即 。然后计算每个 与投影后的文本嵌入 的余弦相似度,并通过选择函数对不同注意力头的相似度分数进行选择,选取所有注意力头中的最大相似度分数,以促进文本和视觉表示之间的稳健对齐,适应与文本查询对应的最显著视觉特征。
训练过程
为优化文本和视觉嵌入之间的对齐,采用InfoNCE损失,该损失利用一批图像-文本对的相似度分数。对于每个图像-文本对 ,计算投影后的文本嵌入 与最大激活的视觉嵌入 之间的相似度分数,其中 是从与对应文本 最相关的注意力头导出的视觉嵌入,即 。
将真实的图像-文本对视为正例,批次内的其余对视为负例,这种对比方法促使模型提高匹配对的相似度,降低非匹配对的相似度。对于一批B个图像-文本对,InfoNCE损失 定义为 。
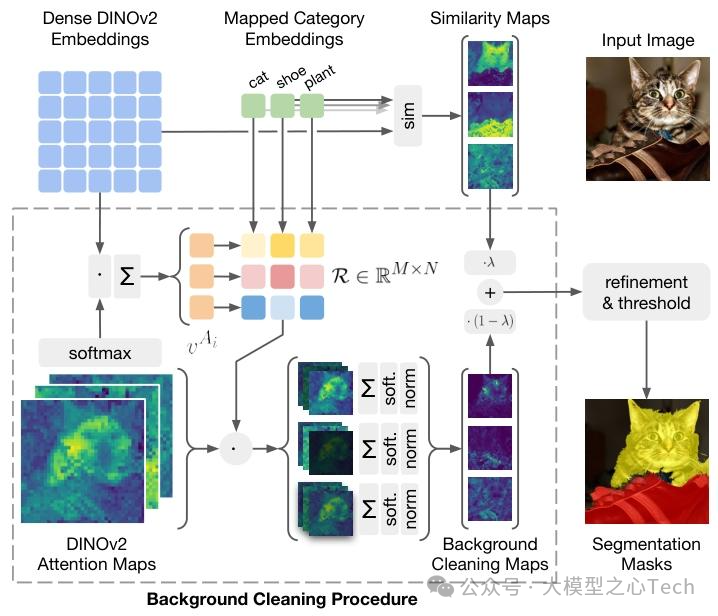
背景区域识别:背景清理程序
为提升模型识别背景的能力,提出基于DINOv2骨干网络自注意力头的背景清理程序。给定N个注意力图 和M个类别的投影文本嵌入 ,首先如上述方法计算平均视觉嵌入 ,然后计算每个 与 的相似度,得到相似度分数矩阵 ,并对其进行行归一化(通过softmax操作)。矩阵 定义为 ,其中 。
对于每个类别 ,计算其平均注意力图 ,公式为 ,并对 进行空间轴上的softmax归一化,再将其值线性重新投影到相似度图 的值域范围内。最终每个类别的增强相似度图 通过相似度图和背景清理图的凸组合得到,公式为 ,其中 是一个超参数,表示背景塑造在计算分割掩码中的相关性。背景区域的分割掩码则被识别为在所有语义类别中,增强相似度图低于某个阈值的像素集合。
实验验证
实验设置
数据集:在八个广泛使用的语义分割基准上进行评估,根据是否包含背景类别进行分类。其中,在Pascal VOC 2012、Pascal Context、COCO Stuff、Cityscapes和ADE20K的验证集上进行实验,这些数据集分别包含20、59、171、150和19个语义类别且不包含“背景”类别;还在COCO Objects数据集(包含80个前景目标类别)以及修改后的包含“背景”类别的Pascal VOC 2012和Pascal Context版本上进行了额外实验。
实现细节:主要实验采用DINOv2 ViT-B/14作为基础模型,DINOv2 ViT-L/14作为大型模型,均搭配CLIP ViT-B/16文本编码器,使用带有寄存器的DINOv2变体,将输入图像调整为518×518以匹配DINOv2的原始训练分辨率,得到37×37的补丁。在COCO Captions 2014训练集(包含约80k图像)上,使用Adam优化器、128的批次大小、 的学习率训练模型100个 epoch。为抵消最终掩码中的不准确之处,采用像素自适应掩码细化(PAMR)进行掩码细化,背景清理中 设为5/6,相似度分数的阈值设为0.55以确定“背景”类别,使用掩码细化时PAMR采用10次迭代。
评估协议:遵循无监督OVS的标准评估协议,不允许在评估前访问目标数据,使用MMSegmentation工具包提供的默认类别名称,所有模型均使用所有类别的平均交并比(mIoU)进行评估,将图像调整为较短边为448,采用步长为224像素的滑动窗口方法。
主要实验结果
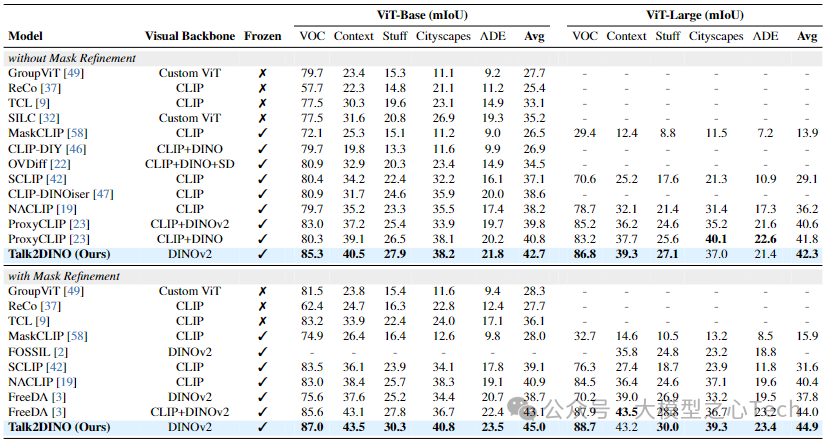
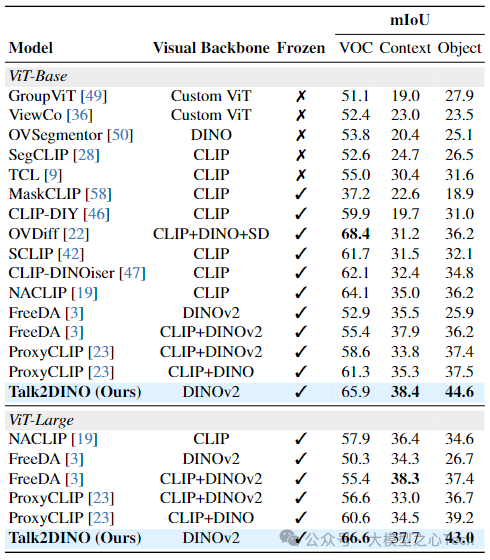
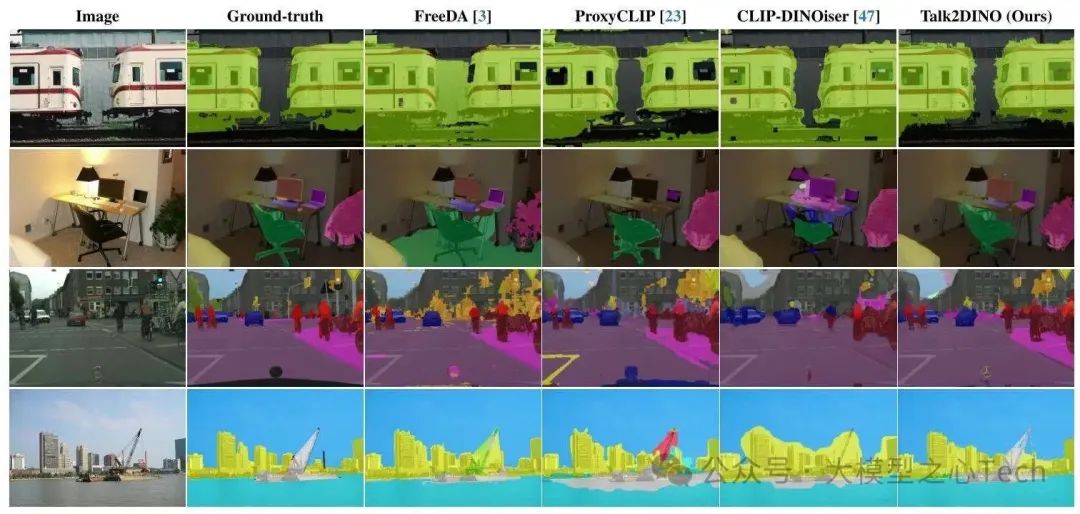
将Talk2DINO与以往无监督OVS的最先进方法在5个不含“背景”类别的基准和3个含“背景”类别的基准上进行比较。比较的竞争对手包括基于原型的方法(如ReCo、OVDiff等)、CLIP改编方法(如MaskCLIP、SCLIP等)、在大规模图像-标题对集合上训练的方法(如GroupViT、TCL等)以及旨在结合CLIP和DINO互补特性的方法(如CLIP-DINOiser、ProxyCLIP等)。
在不含背景的五个基准(Pascal VOC、Pascal Context、COCO Stuff、Cityscapes、ADE)上,无论是基础配置还是大型配置,无论是否使用掩码细化技术,Talk2DINO在所有配置上的平均mIoU均最佳,与所考虑的竞争对手相比有持续的改进。在含背景类别的三个基准上,Talk2DINO在所有考虑的配置中均取得最佳或次佳结果,显著优于通过检索过程构建视觉原型的FreeDA方法,表明直接从CLIP文本编码器到DINOv2的投影训练能在无需计算和内存开销的情况下,在两个嵌入空间之间建立更准确的桥梁。
消融实验
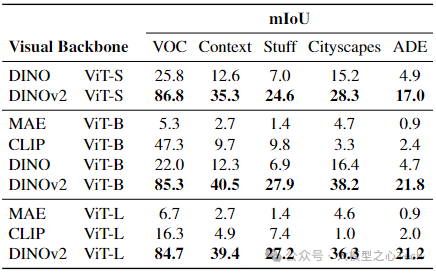
不同视觉骨干网络的选择:当改变视觉骨干网络和所采用的ViT架构大小时,与DINOv2不同的骨干网络表现不佳,无法通过可学习的映射与CLIP文本编码器对齐。DINO虽然平均性能第二,但Talk2DINO从DINOv2密集特征的强大语义表示及其自注意力头突出图像连贯区域的能力中显著受益,且该方法在不同ViT大小上均表现出一致且高性能,即使使用ViT-Small骨干网络也有良好结果。
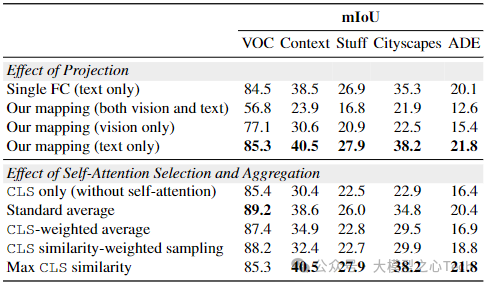
核心组件的影响:在投影的影响方面,用线性投影替代所提出的投影会导致性能略有下降,但表明DINOv2和CLIP空间本质上是兼容的;而将所提出的投影应用于DINOv2之上或在两个空间上应用两个投影会导致性能显著下降,证实了所提方法的适当性。在自注意力头的选择和聚合策略方面,在Pascal VOC数据集上,标准平均自注意力的嵌入表现出更好的性能,但在所有其他基准上,选择与文本CLS token最相似的注意力头嵌入的方法最有效,进一步验证了选择方法的稳健性。
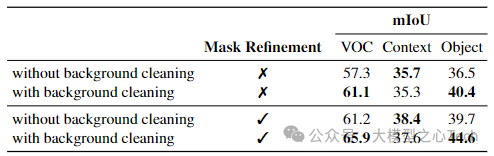
背景清理的效果:背景清理机制和PAMR掩码细化对性能有影响,背景清理对仅包含前景类别的Pascal VOC和COCO Object有积极影响,但对包含通常属于图像背景类别的Pascal Context的性能略有降低,且无论是否使用掩码细化,所提出的背景清理程序的有效性均得到证实。
其他分析:模型参数分析显示,Talk2DINO的参数数量少于最新竞争对手FreeDA和ProxyCLIP,同时平均mIoU更高,具有更好的性能与参数数量权衡。DINO寄存器的作用分析表明,不使用寄存器时性能下降与自注意力中的伪影存在直接相关,伪影会限制与标题最相似的自注意力头的选择机制,在ViT-L架构中性能差异最大,而ViT-S中无寄存器的骨干在五个基准中的四个上表现更好。训练CLIP最后一层的效果分析显示,解冻CLIP的最后一层会导致更差的结果,表明CLIP提供的文本表示若在不同管道中训练,可能会受到损害并失去部分多模态理解能力。文本token选择策略分析表明,CLIP的全局训练目标可能无法赋予文本token强大的局部属性,CLIP文本token的平均值在训练和推理中作为CLS token的替代方案,虽略优于对齐单个token,但仍不如CLIP token,说明CLIP token封装了用于与DINOv2补丁对齐的最有用且噪声更少的信息。
总结
本文提出了Talk2DINO,这是一种新颖的开放词汇分割方法,它将DINOv2自监督视觉骨干网络的空间详细嵌入与CLIP的高语义文本嵌入相结合。该方法通过一个轻量级的语言到视觉映射层,在无需对骨干网络进行大量微调的情况下,实现了文本概念与视觉补丁之间的细粒度对齐,并利用DINOv2的自注意力图来增强分割过程,包括新颖的背景清理程序,从而生成更自然、噪声更少的分割结果,有效区分前景目标与背景。
实验结果表明,Talk2DINO通过仅学习最少的参数集合,在多个无监督OVS数据集上展示了最先进的性能,凸显了自监督纯视觉编码器能够生成具有类似于文本表示的语义属性的嵌入,为解决CLIP类模型的空间理解限制开辟了新途径。
不过,该方法也存在一定局限性,例如DINOv2中存在的伪影现象会影响自注意力头的选择机制,进而影响模型性能,且在不同大小的ViT架构上,这种影响程度不同;此外,CLIP文本token的局部属性不足,限制了其与DINOv2补丁的对齐效果。未来的研究可针对这些局限性进行改进,进一步提升模型性能。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









