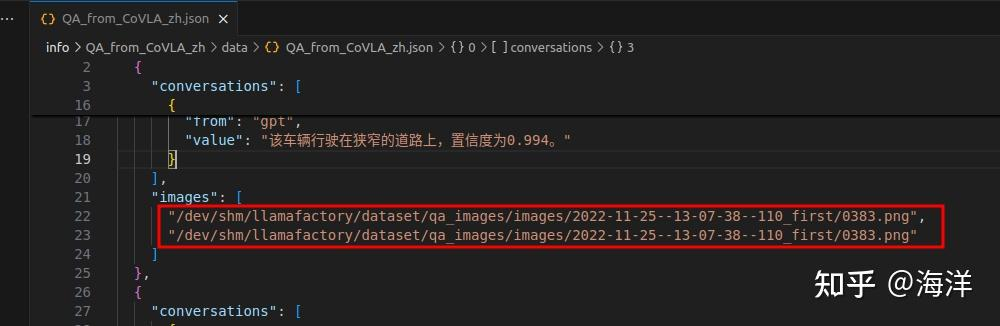
 基于Qwen2.5-VL实现自动驾驶VLM微调
基于Qwen2.5-VL实现自动驾驶VLM微调




作者 | 海洋 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1932832893274652877
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
简单介绍
本次实现GPU 3090, 显存24G, 只用到了400张图片对话(很小的数据集)
参考 https://docs.alayanew.com/docs/documents/useGuide/LLaMAFactory/mutiple/?utm_source=LLaMA-Factory
LLaMA Factory
LLaMA Factory是一款开源低代码大模型微调框架, 以下是对它的详细介绍:LLaMA Factory集成了业界广泛使用的微调技术,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub星标超过4万。本示例将基于Qwen2.5-VL-7B-Instruct模型,介绍如何LLaMA Factory训练框架得到适用于VLM场景的自动驾驶辅助器:给出车辆所处的交通状况,通过自然语言(以对话形式)触发自动驾驶辅助器的功能,并以特定格式返回。
Qwen2.5-VL Technical Report
在本项目中, 模型底座使用Qwen2.5-VL , 以下是对它的详细介绍:Qwen2.5-VL 是 Qwen 视觉 - 语言系列的旗舰模型。它在视觉识别、物体定位、文档解析和长视频理解等方面实现了重大突破,能够使用边界框或点准确地定位物体,还能从发票、表单等中提取结构化数据。该模型引入了动态分辨率处理和绝对时间编码,可处理不同大小的图像和长达数小时的视频。Qwen2.5-VL 提供三种不同大小的模型,旗舰型号 Qwen2.5-VL-72B 的性能与 GPT-4o 和 Claude 3.5 Sonnet 等最先进模型相当,较小的 Qwen2.5-VL-7B 和 Qwen2.5-VL-3B 在资源受限环境中表现出色。
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
在本项目中使用了数据集CoVLA(Comprehensive Vision-Language-Action)以下是对它的详细介绍:CoVLA 是用于自动驾驶的综合视觉 - 语言 - 动作数据集。它包含 10,000 个真实驾驶场景,总计超过 80 小时的视频。该数据集利用基于自动数据处理和描述生成流程的可扩展方法,从原始车载传感器数据生成精确驾驶轨迹,并配以详细的自然语言描述,能准确匹配驾驶环境和操作。其在规模和标注丰富性方面超越了现有数据集,为训练和评估视觉 - 语言 - 动作模型提供了全面平台,有助于构建更安全、可靠的自动驾驶系统。基于该数据集还开发了 CoVLA - Agent 模型,用于可解释的端到端自动驾驶。
下载模型及数据集
下载并安装LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation输入命令看下是否安装成功
llamafactory-cli安装huggingface_hub
pip install -U huggingface_hub -i https://pypi.tuna.tsinghua.edu.cn/simple下载Qwen2.5-VL模型 https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct
export HF_ENDPOINT="https://hf-mirror.com" # 配置清华源来加速下载Hugging Face资源
huggingface-cli download --resume-download Qwen/Qwen2.5-VL-7B-Instruct --local-dir ./model/Qwen2.5-VL-7B-Instruct --max-workers=3上面下载似乎很慢,可以在浏览器上直接手动下载模型
下载CoVLA数据集 https://huggingface.co/datasets/AlayaNeW/QA_from_CoVLA_zh
export HF_ENDPOINT="https://hf-mirror.com" # 配置清华源来加速下载Hugging Face资源
huggingface-cli download AlayaNeW/QA_from_CoVLA_zh --repo-type dataset --local-dir ./QA_from_CoVLA_zh图片:基于CoVLA数据集中的images,过滤筛选出400张图片。 QA问答对:基于QA_from_CoVLA数据集进行整理翻译。因为只有400张图片, 所以实际数据并不太大.下面是图片 2022-07-14--14-32-55--11_first/0553.png 的一些对话. 对话内容在QA_from_CoVLA_zh.json

{
"conversations": [
{
"from": "human",
"value": "<image>\n图片中的天气如何?"
},
{
"from": "gpt",
"value": "天气多雨,置信度为0.978。"
},
{
"from": "human",
"value": "<image>\n车辆真正行驶在哪种道路?"
},
{
"from": "gpt",
"value": "该车辆行驶在宽阔的道路上,置信度为0.659。"
}
],
"images": [
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png",
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png"
]
},
{
"conversations": [
{
"from": "human",
"value": "<image>\n自动驾驶汽车应该关注哪些风险?"
},
{
"from": "gpt",
"value": "风险是:注意交通信号灯和道路上的其他车辆,置信度为0.656。"
},
{
"from": "human",
"value": "<image>\n您可以在图片中看到行人或车辆吗?"
},
{
"from": "gpt",
"value": "没有行人的概率为0.130。存在其他车辆的概率为43.064%。"
}
],
"images": [
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png",
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png"
]
},QA_from_CoVLA_zh.json文件是一些对image的描述性对话, 而"images"的路径名和实际本地存放image的路径应该是不一致的, 这时需要全局替换成本地实际image存放的路径.
LLaMA Factory的Web UI
SwanLab是一款开源且轻量级的AI模型训练可视化追踪工具。在本次微调任务中,我们将使用SwanLab记录整个微调过程。安装SwanLab的命令行(不安装也行)
pip install swanlab -i https://pypi.tuna.tsinghua.edu.cn/simple/copy备份一份模型和数据集, 以免操作失误导致损坏.
cp -r /home/hy/data/QA_from_CoVLA_zh /home/hy/source/code/transformer/LLaMA-Factory/info
cp -r /home/hy/data/model/Qwen2.5-VL-7B-Instruct /home/hy/source/code/transformer/LLaMA-Factory/info记得将对话中的images字段路径也要跟着改动一下.
在LLaMA-Factory路径下输入:
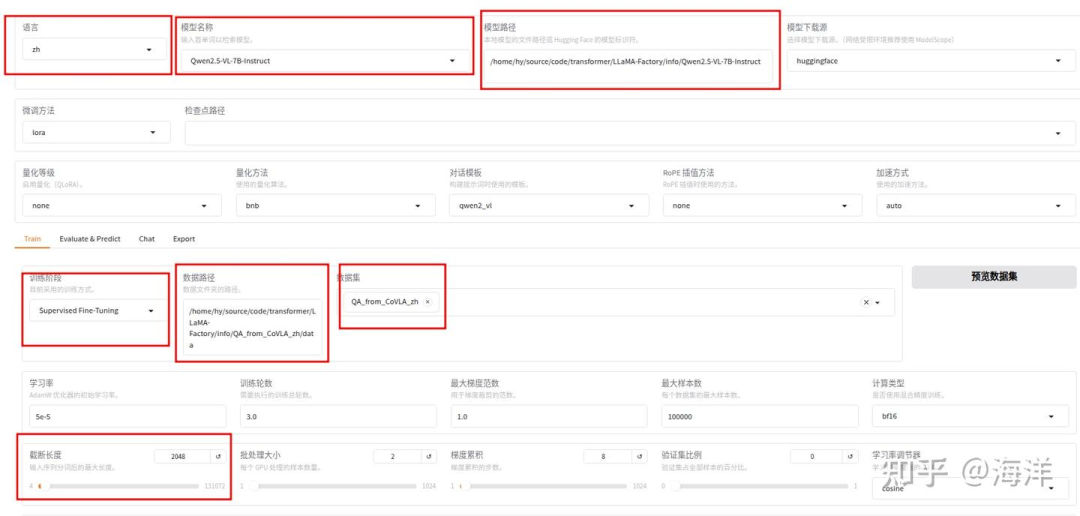
llamafactory-cli webui # 启动web ui界面通过http://localhost:7860启动web ui界面并设置配置参数. 截断长度应该设置的大一些,否则会报错.
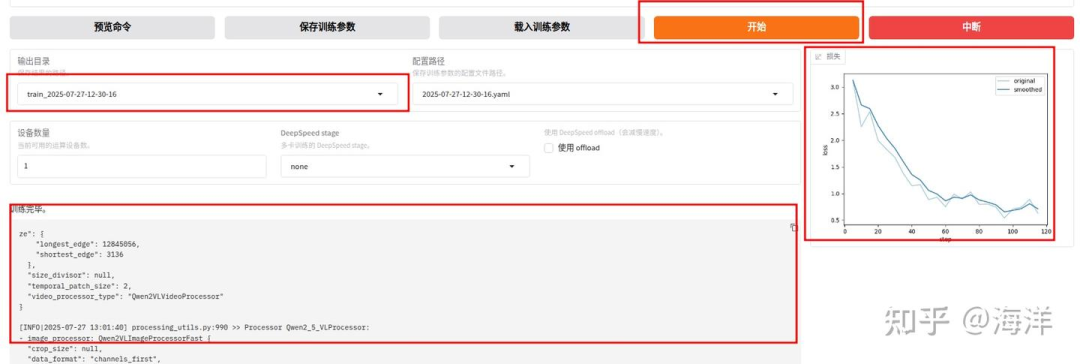
各项参数配置完成后,单击“开始”按钮,执行大模型的微调任务。开始微调后,页面最下方会显示微调过程的日志。微调后的模型被保存在 /home/hy/source/code/transformer/LLaMA-Factory/saves/Qwen2.5-VL-7B-Instruct/lora/train_2025-07-27-12-30-16 中, ui会显示loss进度和进度条。
可能会显示CUDA out of memory, 修改"批处理大小"和"梯度累积"的参数应该可以缓解.

测试VLM
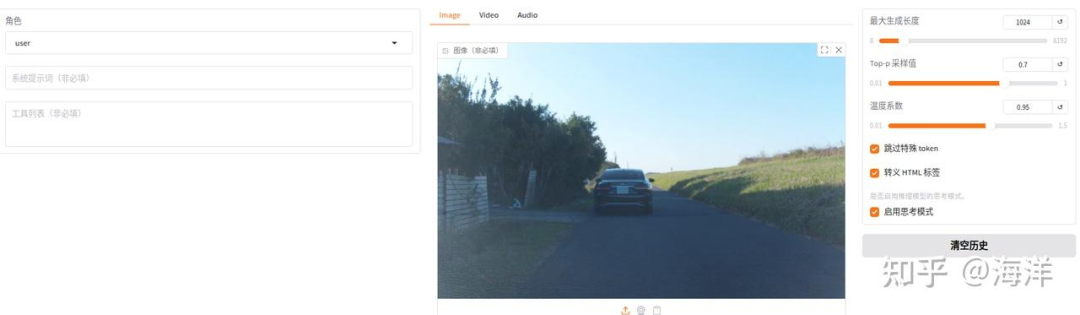
训练完成后在Web UI界面,配置检查点路径中选择微调模型的路径,示例如下图高亮所示。
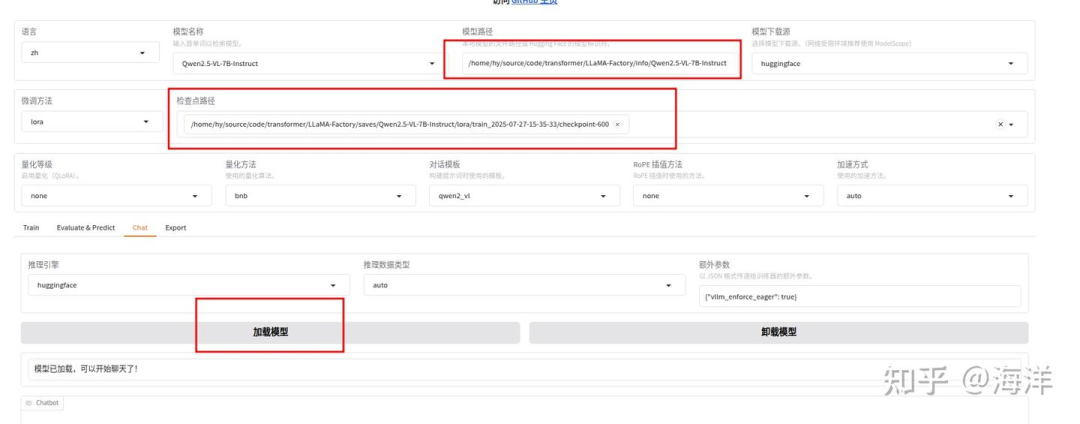
单击“加载模型”按钮,加载微调后的模型,使用加载好的微调模型进行对话,下载素材图片,然后上传图片,如下图高亮所示。输入问题“自动驾驶车辆应该关注哪些风险?”,观察模型回答,如下图高亮所示。

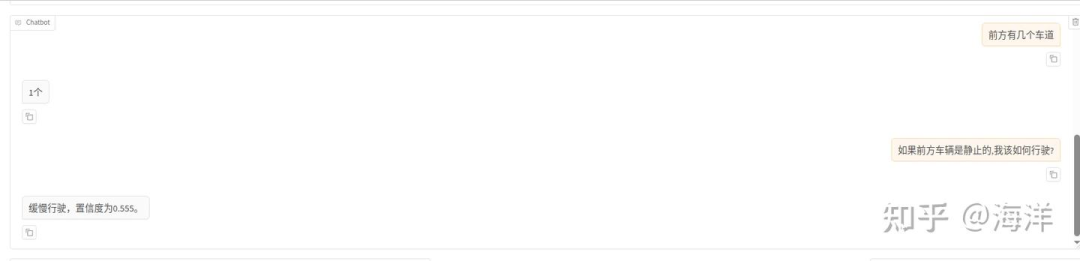
清空“检查点路径”LoRa配置,单击“加载模型”按钮,使用原生的Qwen2.5-VL-7B-Instruct模型进行对话,输入同一个问题:“自动驾驶车辆应该关注哪些风险?”,观察模型回答,示例如下图所示。
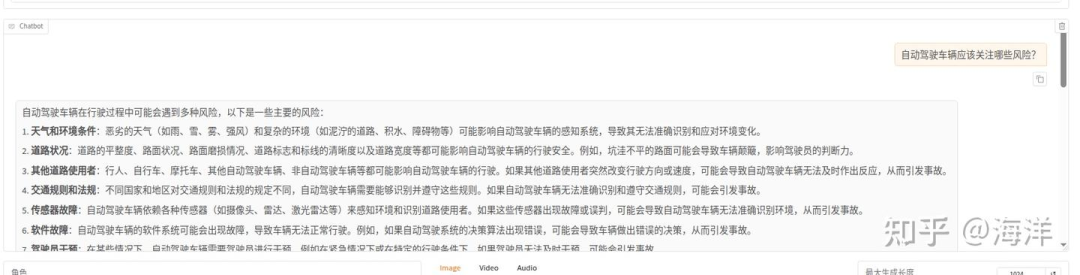


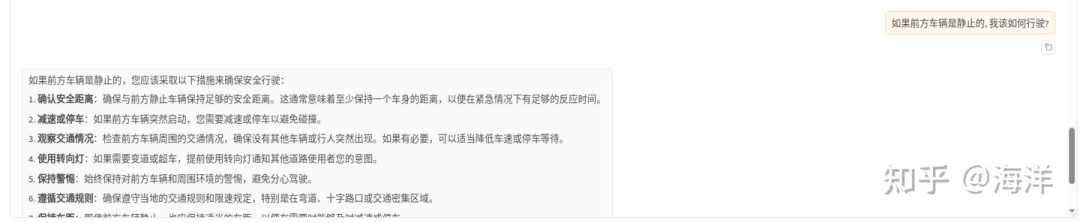
综合看来通过使用微调后的模型进行对话,可以获得更具参考价值的回答。原始模型虽然回答内容很多,但有些答非所问。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 3162
3162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









