



点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享自动驾驶场景重建图像几何SOTA新工作。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Nan Wang等
编辑 | 自动驾驶之心
导读
在自动驾驶场景的三维重建中,神经渲染技术(如高斯溅射)正扮演日益重要的角色。然而,真实世界中光照、相机参数和视角的不断变化,导致了图像间的“色彩不一致性”,这严重挑战了重建的真实感与几何精度。为解决此问题,作者们提出了一个创新的多尺度双边网格框架。该框架巧妙地统一了外观编码(Appearance Codes)和双边网格(Bilateral Grids),实现了对驾驶场景中复杂光影变化的精确建模,从而显著提升了动态场景重建的几何精度和视觉真实感。

论文链接:https://arxiv.org/abs/2506.05280
代码仓库(Github):https://github.com/BigCiLeng/bilateral-driving
项目主页:https://bigcileng.github.io/bilateral-driving/
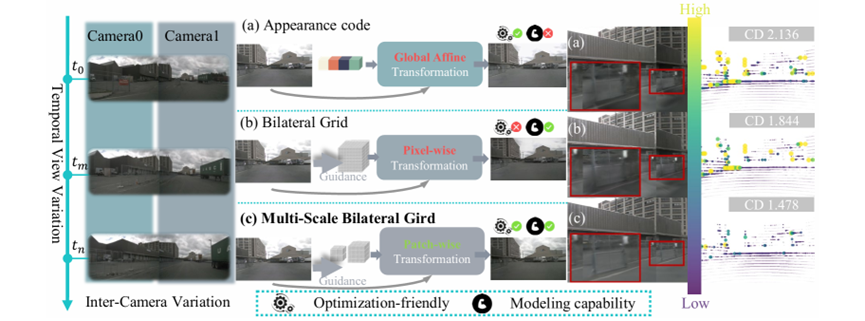
图注:(a)外观编码进行全局变换,但建模能力有限。(b)双边网格支持像素级变换,能提升色彩一致性,但优化难度大。(c)本文提出的多尺度双边网格统一了前两者,实现了高效且强大的区块级变换。
动机:
凭借其高真实感的重建能力,神经渲染技术对于自动驾驶系统的开发与测试至关重要。然而,这些技术高度依赖于多视角图像间的色彩一致性(photometric consistency)。在复杂的真实驾驶场景中,光照条件、天气变化以及不同摄像头的内在参数差异,都会引入显著的色彩不一致,导致重建出错误的几何(如“浮空片”伪影)和失真的纹理。
现有的解决方案主要分为两类:
外观编码(Appearance Codes):该方法为每张图学习一个全局编码来校正色彩,但它只能进行整体调整,无法处理场景内的局部光影变化(如物体投下的阴影)。
双边网格(Bilateral Grids):该方法能够实现像素级的精细色彩调整,更灵活。但其优化过程非常复杂,在大型场景中容易出现不稳定、效果不佳等问题。
为了克服上述方法的局限性,本文提出了一个能同时拥有两者优点的全新框架。
核心贡献:
本文提出了一个新颖的多尺度双边网格(multi-scale bilateral grid),它无缝统一了全局的外观编码和局部的双边网格,能够根据尺度变化自适应地进行从粗到细的色彩校正。
通过有效解决色彩不一致性问题,本文的方法显著提升了动态驾驶场景重建的几何精度,有效抑制了“浮空片”等伪影,使重建结果更可靠。
本文在Waymo、NuScenes、Argoverse和PandaSet等四个主流自动驾驶数据集上进行了广泛的基准测试,结果表明本文的方法在各项指标上均优于现有方案。
本文的方法具有良好的通用性和兼容性。将其集成到现有的SOTA模型(如ChatSim、StreetGS)中,能一致地带来显著的性能提升

方法简述
为解决真实驾驶场景中复杂的光度不一致性(photometric inconsistency),本文提出了一种新颖、高效的真实感渲染管线。该管线的核心是一个精心设计的多尺度双边网格(Multi-Scale Bilateral Grid),它巧妙地将全局调整与局部细节增强相结合,实现了对渲染图像由粗到细的层次化色彩校正。
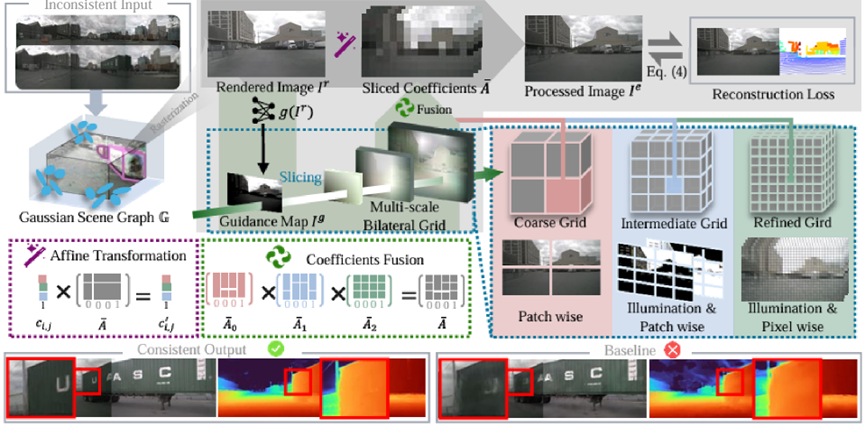
整个流程可以分解为以下几个关键步骤:
1)场景表示与初始渲染
首先,我们采用高斯溅射(Gaussian Splatting)技术对复杂的驾驶场景进行建模。参考最新的重建方法,场景被分解为一个混合场景图(hybrid scene graph),包含独立建模的天空、静态背景和动态物体(如车辆、行人)。通过对这个场景图进行渲染,我们得到一幅初步的图像
。这幅图像虽然在几何上是准确的,但由于多摄像头、多光照环境的影响,通常带有明显的光度不一致问题,为后续的校正提供了输入。
2)多尺度双边网格校正
初步渲染的图像
将被送入一个层次化的多尺度双边网格中进行处理,最终输出一幅色彩一致、观感真实的高质量图像
。该过程具体如下:
亮度引导(Guidance Map):校正的第一步是根据输入的渲染图像 生成一张单通道的亮度图 (luminance-based guidance map)。这张图编码了场景中的光照分布(如阴影和高光),它将作为“向导”,指导后续网格在不同空间位置应用恰当的色彩变换。
层次化网格结构(Hierarchical Grid Structure):我们的框架包含一个由三个不同尺度的双边网格组成的“金字塔”:
a. 粗糙层(Coarse Grid):一个极小的网格(例如2×2×1×12),负责捕捉并校正场景级的整体光照和色调偏差。它的作用类似于一个全局的外观编码(Appearance Code),进行区块级(Patch-wise)的初步调整。
b. 中间层(Intermediate Grid):一个中等尺寸的网格(例如4×4×2×12),在前一层的基础上,进一步处理区域性的光影变化,例如大块的阴影或光斑。
c. 精细层(Fine Grid):一个尺寸较大的网格(例如8×8×4×12),进行像素级的精细微调,精确恢复物体的局部细节和材质。它的行为逼近于传统的双边网格,但优化过程更稳定。每个网格张量的最后一个维度为12,代表一个3x4的仿射颜色变换矩阵(affine color transformation matrix),用于执行色彩变换。
对于图像中的每个像素,我们通过“切片”(Slice)操作从每个层级的网格中提取一个局部的仿射变换矩阵 。该过程通过三线性插值实现,确保了变换的平滑性:
由粗到细的融合校正(Coarse-to-Fine Fusion):我们的框架并非孤立地使用这三个网格,而是通过一种函数式复合(hierarchical function composition)的方式将它们串联起来。具体来说,亮度图 会引导粗糙层网格先对图像进行全局校正;然后,其输出结果将作为中间层网格的输入,进行区域性修正;最后,再由精细层网格进行最终的局部细节完善:
这种逐级传递、残差式优化的策略,使得模型能够灵活且稳定地统一两种主流方法的优点,从而还原出色彩一致、几何精确的高质量3D场景。
3)优化策略与真实世界适应性
为了确保模型训练的稳定高效及其在真实世界中的应用效果,我们设计了专门的优化和渲染策略。
训练策略: 我们采用由粗到细的优化策略,为粗糙层网格分配较高的学习率,为精细层网格分配较低的学习率。这确保了模型首先学习全局的色彩基调,再逐步优化局部细节,增强了训练的稳定性。
优化目标:复合损失函数
为了稳定地训练整个模型,我们设计了一个复合损失函数,它不仅要求重建结果在外观和几何上与真值对齐,还引入了正则化项来保证学习到的色彩变换是平滑且合理的。总损失函数 定义为:
其中 是核心的重建损失,结合了L1损失和结构相似性指数,共同衡量渲染图像与真值图像之间的差异;几何损失 计算渲染深度图与激光雷达(LiDAR)提供的真实深度数据之间的损失,以保证几何形状的准确性;而 和 是为了提升图像质量和模型鲁棒性引入的正则化项。循环正则化损失( ) 鼓励学到的色彩变换是可逆的,从而有效约束了变换空间,防止产生伪影,保证了高质量的视觉效果:
而自适应总变分正则化( )惩罚网格内部特征的剧烈变化, 使我们多尺度网格学习到的颜色变换更加平滑,并减少噪声伪影。
动态渲染与ISP适配: 自动驾驶系统在真实世界中会遇到动态变化的图像信号处理器(ISP)参数。为了适配这种变化,在渲染新视角图像时,我们提出了一种动态插值策略。对于一个新时间戳 的图像,我们首先找到temporally closest的两个训练时间戳t1和t2。然后,对两者的粗糙和中等尺度网格进行线性插值,生成用于新图像渲染的网格,使得我们的模型能够有效适应真实世界动态变化的相机特性,显著增强了方法的实用性和鲁棒性。
实验结果
本文在Waymo、NuScenes、Argoverse和PandaSet这四个大规模自动驾驶数据集上对所提出的框架进行了全面评估。实验结果在定量和定性上都雄辩地证明了方法的先进性。
(1)定量评估:几何与外观的同时改进
在定量分析中,本文的方法在衡量三维几何形状准确性的几何度量和衡量渲染图像真实感的外观度量上,均取得了业界领先的成果。
几何精度显著提升:几何精度对于自动驾驶的安全至关重要。实验表明,本文的方法在所有测试数据集上都稳定地优于所有基线模型。以最关键的几何误差指标之一——倒角距离(Chamfer Distance, CD)为例,在Waymo数据集上,基线模型的CD为1.378,而本文的方法将其大幅降低至0.989,精度提升显著。这一优势得益于本文的模型能有效处理由色彩不一致性引起的“浮空片”(floater)等伪影。
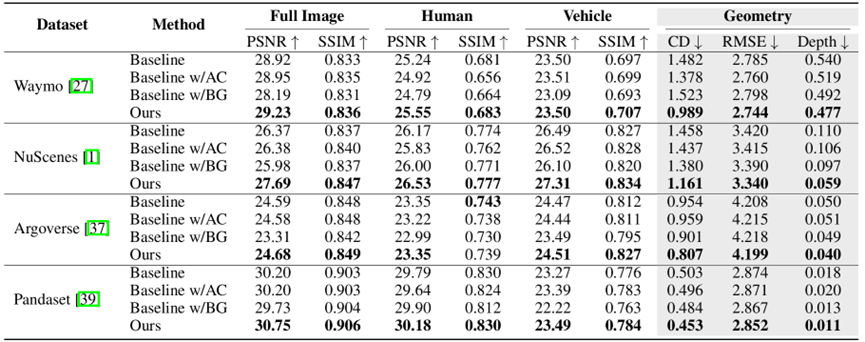
图注:在Waymo、NuScenes等四个极具挑战性的主流数据集上,将本文的方法(Ours)与三种基线方法(包含单独使用外观编码或双边网格的方案)进行了全面对比。评估指标覆盖了几何精度(CD、RMSE)和外观真实感(PSNR、SSIM)。表格数据清晰显示,本文的方法在几乎所有数据集的所有指标上都取得了最佳成绩。以几何精度为例,在Waymo数据集上,本文的倒角距离(CD)仅为0.989,远低于基线模型的1.378。这证明了本文的方法在生成高精度三维模型方面的卓越能力。
外观真实感刷新SOTA:在外观保真度上,本文的方法在PSNR(峰值信噪比)和SSIM(结构相似性)指标上同样表现出色,在所有数据集的全图像重建中均取得了最高分。特别是在处理场景中的动态物体时,优势更为明显。例如,在NuScenes数据集上,针对“车辆”类别的渲染,模型的PSNR达到了27.31,超越了基线模型的最佳结果26.52。
对现有SOTA模型的增强能力:为了验证方法的通用性,本文将其核心模块集成到了两种先进的基线方法ChatSim和StreetGS中。结果显示,本文的方法能作为即插即用的增强模块,带来巨大提升。例如,它将ChatSim的重建PSNR从25.10提升至27.04;同时将StreetGS的重建PSNR从25.74提升至27.90,并将其几何误差(CD)从1.604降低到1.272。

图注:验证了本文方法的通用性和即插即用的价值。将核心模块集成到ChatSim和StreetGS这两个先进模型后,它们的性能均获得巨大提升。例如,StreetGS的重建PSNR从25.74提升至27.90,同时几何误差(CD)从1.604大幅降低至1.272。
(2)定性评估:无惧复杂真实场景
定性对比结果更直观地展示了本文方法的鲁棒性。
下图提供了直观的视觉对比,展示了本文的方法在处理真实世界复杂情况时的鲁棒性。通过对比真实图像(Ground Truth)、我们的结果(Baseline + Ours)和基线结果(Baseline),可以观察到:
有效抑制视觉伪影:如下图所示,与依赖单一外观编码或双边网格的基线方法相比,本文的统一框架能生成更清晰、更完整的几何结构。它能有效减少由光影突变导致的几何错误,并显著抑制“漂浮物”伪影,使得重建的场景更加干净、真实。
驾驭多样化挑战:真实驾驶场景充满了挑战。本文的方法被证实能够稳健地处理各种极端情况,包括:
物体表面的高光反射(Specular highlights)
快速移动车辆造成的运动模糊(Motion Blur)-夜晚或隧道中的低光照环境(Low-Light)
由遮挡或视角限制导致的不完整几何(Incomplete Geometry)
在这些困难的场景下,基线方法往往会出现明显的失真、伪影或模型坍塌,而本文的方法则能保持高质量和高稳定性的输出。

图注:通过视觉对比,展示了本文的方法在处理真实世界复杂情况时的鲁棒性。通过对比真实图像(Ground Truth)、我们的结果(Baseline + Ours)和基线结果(Baseline),可以观察到:(a)高光区域:基线方法在车身反光处出现过曝和细节丢失,而本文的方法能有效抑制高光,还原出下方纹理。(b)运动模糊:本文的方法能生成比基线更清晰的动态物体边缘,有效减轻运动模糊带来的影响。(c)和(d)不完整几何与伪影:基线方法在重建远处或被遮挡的物体时,容易产生不完整的、破碎的几何结构,而本文的方法能生成更连贯、更完整的场景。(e)低光照:在光线不足的场景下,本文的方法能更好地提亮暗部细节,同时避免噪点,还原出更真实的夜间场景。


下图则更进一步,直观地证明了本文方法在几何精度上的优越性。图中用颜色标示了几何重建与真实激光雷达数据之间的误差,黄色代表高误差,紫色代表低误差。可以清晰地看到,无论是对比(a)外观编码还是(b)单尺度双边网格,(c)本文的方法所生成的场景中黄色区域都显著减少,表明其重建的几何模型与真实世界更为贴合,有效减少了“浮空片”(floaters)等错误。

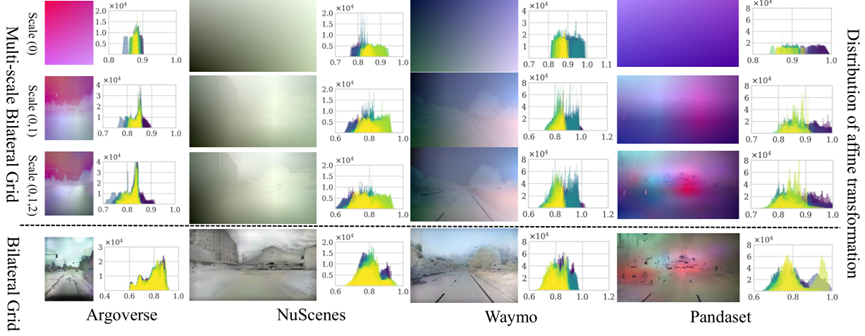
下图则深入剖析了本文的方法为何有效。它通过直方图的形式,可视化了不同方法所“学习”到的色彩校正策略。
下排(Bilateral Grid):代表传统的单尺度双边网格。可以观察到,其学习到的变换分布通常呈现出两个尖锐的峰值(即“双峰分布”)。这表明它只学会了少数几种固定的、缺乏弹性的校正模式,难以适应真实世界中多样化的光照变化。
上三排(Multi-scale Bilateral Grid):代表本文的多尺度方法。其最终聚合后的变换分布直方图(最右侧叠加图)显得平滑和分散。这证明本文的方法学习到了一个极其丰富和多样化的色彩变换集合,能够从全局、区域到像素级别进行平滑过渡和精细调整。正是这种强大的适应性和表示能力,使其能够在各种复杂场景中取得鲁棒的、高质量的渲染结果。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1979
1979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









