



作者 | 饭饭科技视频博客 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1920163120611070749
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
看到一篇非常不错的内容,想给大家分享一下
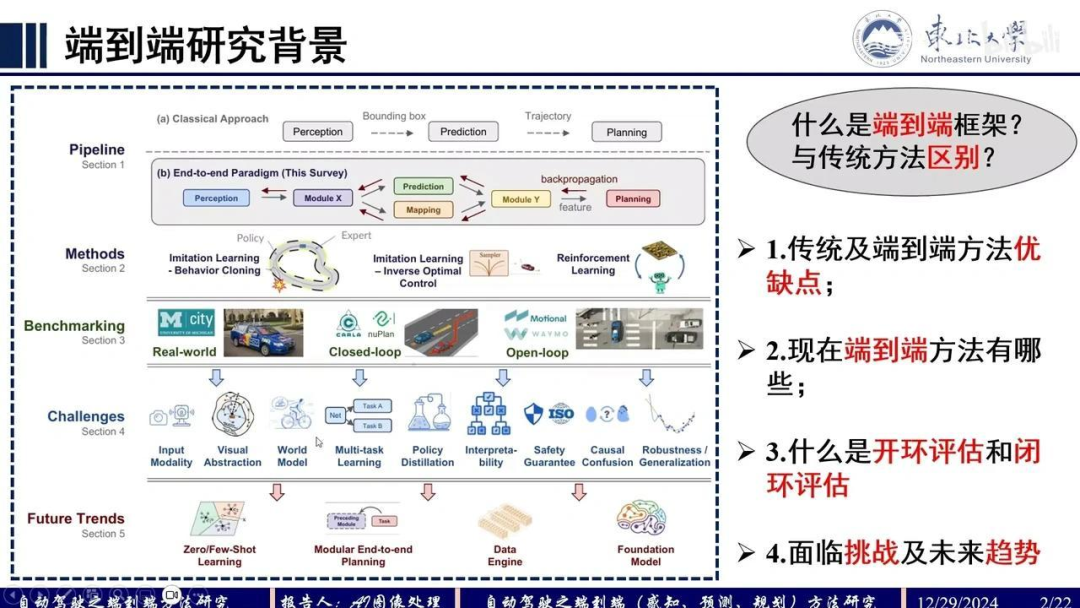
我们来看一下端到端自动驾驶算法的当前发展状况,并进行简要总结。首先,探讨端到端算法的研究背景。端到端算法框架是什么?它与传统算法有何区别?
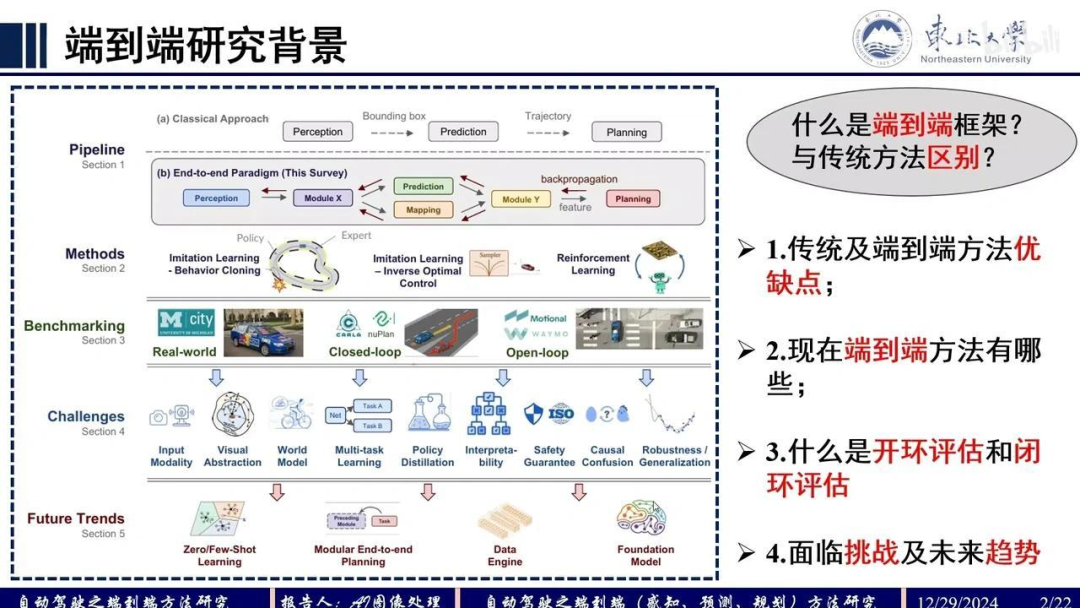
我们来看这个 pipeline 的第一行,这是传统自动驾驶算法的流程:先进行感知,然后预测,最后规划。每个模块的输入输出不同。
感知模块 的输入是图像或激光雷达数据,输出边界框作为预测模块的输入;预测模块 输出轨迹,再进行规划。这是传统算法的流程。
端到端算法 的输入是原始传感器数据,直接输出路径点。输出路径点与控制信号本质相同,因为从路径点到控制信号有固定算法转换。此外,回归路径点相对容易,因此多数算法选择输出路径点。
传统算法的优点是易于调试和问题定位,具有一定的 可解释性。缺点是存在 误差累积 问题,因为无法保证感知和预测模块完全无误差。
同时,感知信息的原始数据存在一定的信息损失。在预测时,仅输入了感知的输入结果。
然而,它并未与初始感知信息进行交互。传统端到端算法并非没有缺点。通过大量文献阅读发现,多段多算法也存在局限性。例如,当前常用范式是通过模仿学习实现,但这种方法难以有效解决所有corner case问题,主要因其数据驱动的特性。
若在数据集中加入少量corner case样本,模型可能将其视为噪声而无法充分学习;若增加corner case样本比例,又会影响常规操作性能。此外,真值数据本身存在噪声,在某些场景下人类驾驶数据并非完全最优解,因为规划问题本身不存在绝对固定的最优解。因此,模仿学习方法存在固有局限性,端到端数据驱动算法的能力目前仍有限制。
关于端到端算法的现有范式,综述中总结了以下几种:模仿学习可分为行为克隆(论文中较常见)和逆优化控制(论文中较少见);强化学习方法在论文中也不常见。此外,评估方法可分为开环和闭环两种:闭环评估中,自车与环境存在交互,执行动作会影响他车,信息随时间推移动态变化;而开环评估则使用固定场景数据。
当前面临的挑战包括可解释性问题、安全保证以及因果混淆现象。以因果混淆为例:当车辆在中间车道直行,因红灯停车后绿灯起步时,模型可能并未学习到“绿灯起步”这一因果关系,而是误将旁边车道车辆起步作为启动信号。
在起步阶段,若周围无其他车辆且信号灯为绿灯时,系统可能出现沙瓶效应。这属于因果混淆的典型案例,在传统算法中构成显著挑战。此外,该系统还需解决输入模态多样性、多任务学习及知识蒸馏等技术难题。
接下来,我们将探讨当前经典的端到端自动驾驶算法的实现方式。
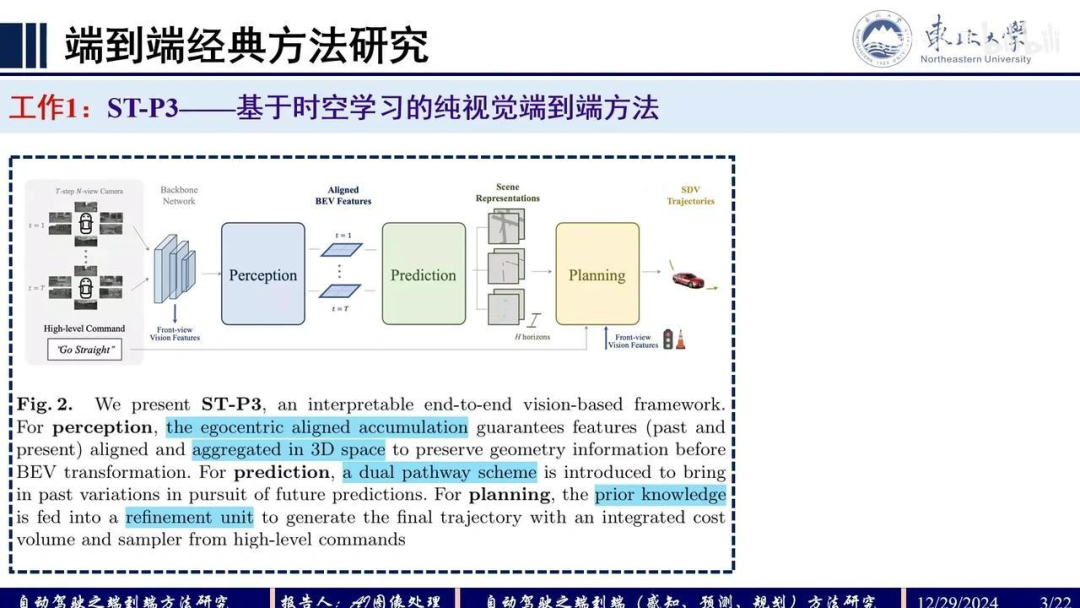
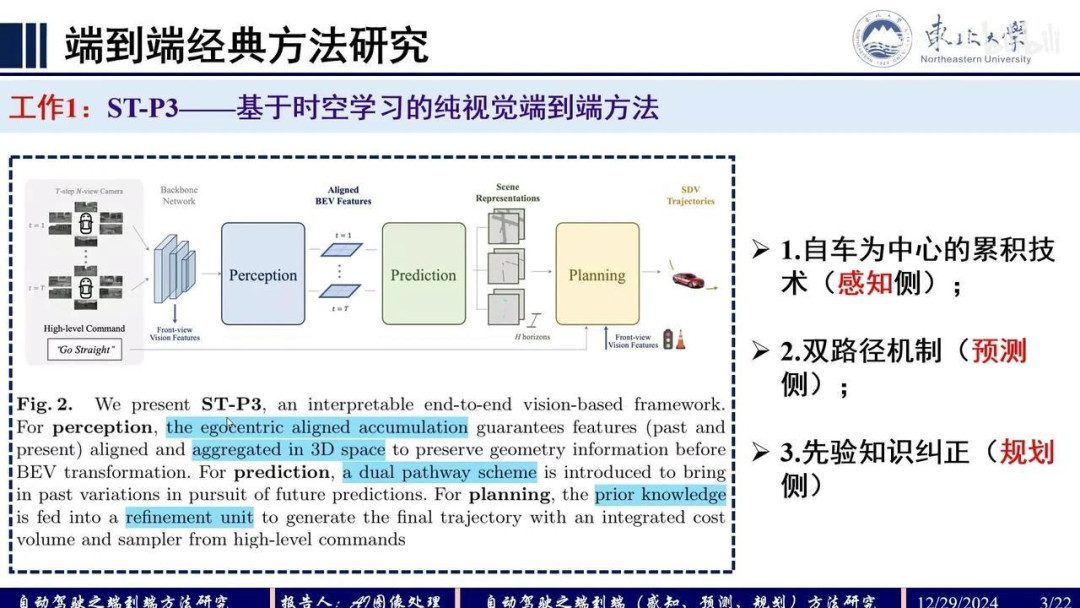
首先介绍的是ST-P3算法,这是一篇较早关于端到端自动驾驶算法的论文。该算法基于时空学习,专注于端到端自动驾驶的实现。其整体框架如下:输入为环视相机图像,明确设计了三个核心模块——感知、预测和规划,最终输出自动驾驶车辆的轨迹。
该论文的创新点主要体现在感知、预测和规划三个方面:
感知模块:采用了一种以自车为中心的累积对齐技术。
预测模块:通过双路预测机制实现。
规划模块:引入先验信息对生成的轨迹进行优化。

我们来看具体的细节。
首先,在感知模块中,右上角的公式表示输入图像信息CHW。对特征进行提取后,结合预测的深度信息DK,采用类似LSS范式的方法,通过图像特征和深度特征进行插值,得到微点云的空间表示,即BEV空间。这里生成的是一个UdVDD1维度的微点云信息。
该方法的创新点在于考虑了RO角和PG角不为零的情况。传统BEV算法假设地面平坦,即RO角为零。而该方法对3D微点云信息进行对齐处理后再投影到BEV空间。此外,还进行了时序融合,为每个时序特征赋予权重,类似于注意力机制的操作,并在特征通道上增加了自车维度。
在预测模块,采用双路结构。第一路输入为X1到ST时刻的感知特征,通过GRU进行递归处理;第二路考虑到感知特征预测的不稳定性,引入高斯噪声进行前向迭代,同时利用当前T时刻特征作为hidden state进行递归更新。将两路预测输出融合,得到T+10、T+20时刻的状态特征。
基于预测模块的表征,进行解码操作。主要通过实例分割实现,涉及agent信息和地图信息。其中agent信息包括行人检测、中心点定位和位移预测等。
在构建地图信息时,通过分割头生成高清地图。预测模块的前向传播逻辑较为简单。规划阶段的创新点在于:利用前视相机获取红绿灯信息,并对预测轨迹进行优化(Refinement)。具体流程为:选定最终轨迹后,将红绿灯编码输入GRU网络进行解码,输出最终的预测轨迹。
优化过程包含两大组成部分:
自车预测轨迹的代价函数(Cost Function):
考虑与前车的距离
车道分隔线的距离
横向和纵向加速度信息
轨迹终点与目标点之间的距离(Progress Cost)
预测轨迹与真实轨迹之间的L2距离
ST-P3的规划方法综合考虑了上述因素。
接下来我们讨论第二个工作UniAD。
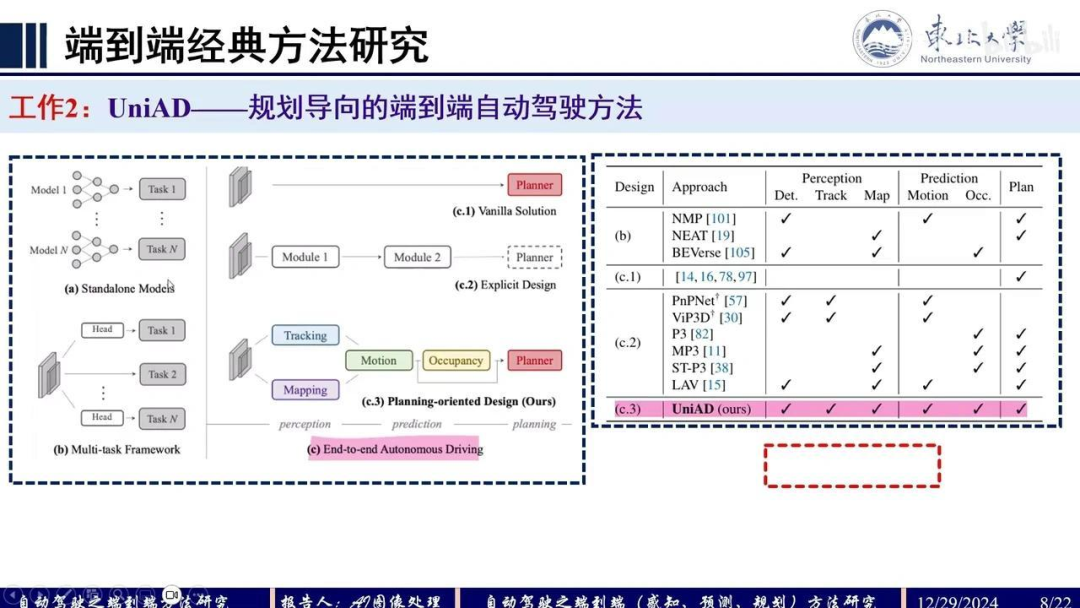
首先,这是Introduction部分的一张图,对比了ABC三种范式的优缺点。模块堆叠方法存在误差累积和信息损失的问题。多任务框架在同时训练Task1和Task2时会产生负迁移效应,即任务间存在相互影响。右侧展示了端到端自动驾驶的三种范式:
原始方法直接通过特征回归轨迹(Planning),但可解释性差且优化困难;
显式模块化设计方法,如ST-P3仅使用了Map、Occ和Plan三个模块;
UniAD的创新点在于引入了五个代理任务(Head Task),通过增加任务数量提升性能。

该系统采用全Transformer框架,以规划为导向,构建端到端自动驾驶系统。
首先,在Backbone部分与BVFormer相同,获取BEV特征。Transformer部分则借鉴MOTR框架。MapFormer将Segformer的2D版本扩展至3D,用于实例分割:前景包括分割线、边界线和人行道,背景则为可行区域。
MotionFormer通过三种交互进行预测:Agent之间的交互、Agent与地图的交互,以及Agent与目标点的交互。输出包括预测轨迹、特征及每条轨迹的评分。OccFormer利用MotionFormer的Agent级特征作为KV,BEV特征作为Q,计算实例级的占用情况。其中,Agent级特征与场景级特征通过矩阵运算得到最终结果。
Planner的输入包括:自车运动轨迹特征(来自MotionFormer)、位置编码、OccFormer的输出以及BEV特征。规划时需考虑未来占用情况,确保选择可行区域。具体实现细节如下:
MapFormer部分基于MOTR框架,TrackFormer输出的NA代表动态变化的Agent数量。
主要负责预测Agent的数量。TrackFormer部分涉及N×256维度的QA模块,用于表征Agent的特征,即EBTQA(Agent的特征表示)。PA和QM模块分别对应NM×256的维度。
关于TrackFormer,其框架与MOTR类似。在t=1时刻,初始化的detect query作为输入,此时track query为空。输入到decoder后,输出的预测框完全由detect query生成。经过detect decoder的特征更新后,进行特征交互,生成track query。该query与下一帧的detect query共同输入decoder,输出t=2时刻的预测框。特征在decoder后进一步进行时序交互,实现迭代推进。TrackFormer的核心思想在于track query与detect query的协同更新。
MapFormer部分主要完成实例分割,通过前景与背景的分割头实现。
MotionFormer的框架如下:左侧为MotionFormer模块。
该系统由三个交互模块组成:Agent、Map和Ego。这三个交互模块相对容易理解,而较难理解的是位置编码的生成方式。具体来说,位置编码分为Agent级别和场景级别两种。
对于Agent级别的位置编码,首先对所有Agent在数据集中进行聚类,通常聚为六类,然后以各类的中心点作为Anchor的位置编码。
对于Map的位置编码,需考虑全局场景信息。具体方法是将局部视角下的Agent坐标通过旋转矩阵和平移矩阵投影到全局坐标系下进行转换,从而得到场景级的位置编码。其中,表示当前时刻初始化的位置编码,表示上一层预测轨迹的终点作为位置编码。这些编码经过MLP处理后相加,作为后续三个交互模块的位置编码。
在交互过程中,Agent与Agent之间先进行自注意力计算,再进行交叉注意力计算。交叉注意力是与BEV特征进行的。Agent之间通过自注意力机制评估各Agent Query的重要性。Agent与Map之间进行交叉注意力计算,而Agent与Ego之间则采用可变性注意力机制。
最终,将三个模块的输出、、拼接后通过MLP生成当前时刻的运动特征表征,再经过另一个MLP进行评分,同时解码出相对轨迹。此时Motion Former输出的表征将用于后续处理,即。
在OCC模块中,首先对BEV特征进行表征。通过自注意力机制处理后,结合Agent级特征和运动预测输出的BEV特征进行交叉注意力计算。将得到的Qx特征相加,获得t时刻的DB表征。随后,将场景级密集表征与Agent级表征进行矩阵乘法运算,预测未来时刻的占用情况。
未来时刻的BEV表征通过迭代输出的特征块获得,经解码器处理后得到场景级占用情况。再与实例信息进行矩阵运算,最终输出实例级别的未来占用预测。这就是OCC Former的核心机制。
在规划模块中,首先整合转向灯信号和自车Agent特征。Transformer模块会融合自车轨迹表征,并在Motion Former中进行交互更新。将更新后的自车表征、轨迹表征以及规划查询(Planning Query)通过MLP和MaxPool处理,生成规划token。
该规划token作为查询向量,与BEV特征作为键值对进行匹配,生成初始轨迹。通过碰撞优化(基于OCC模块的输出)最终输出优化后的轨迹表征。这就是Planning Former的主要流程。
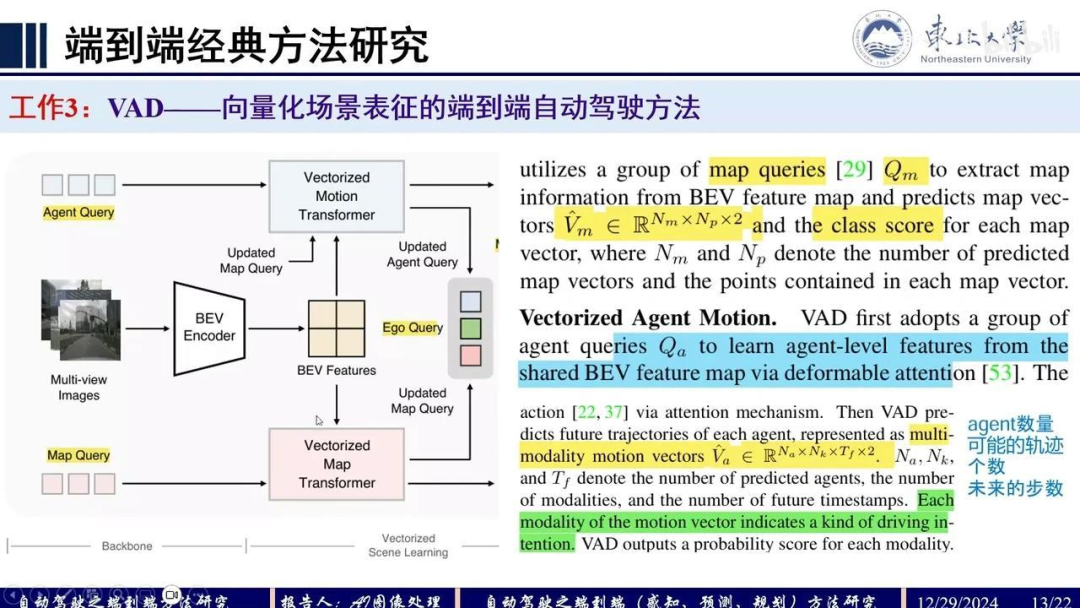
VAD(Vectorized Autonomous Driving)采用矢量化表征方法,其前身MapTR和MapTRv2将栅格化表征转换为矢量化形式。这种方法能更好地表达地图元素的结构信息,保持其几何特性。矢量化表征在表达结构化信息方面具有显著优势。
其计算速度较快,因此他们尝试将矢量表征应用于短程纵向规划。该矢量表征与传统的感知方法类似,包含运动矢量(motion vector)和地图矢量(map vector)。具体实现方式为:通过输入地图查询(map query),经地图变换器(map transformer)处理后预测地图矢量;通过智能体查询(agent query)预测运动矢量。随后将自车查询与这两个更新后的查询进行交互,输出自车查询结果。更新后的自车查询再与车辆状态信息及指令信息结合,进行规划决策。
在规划过程中引入了矢量化的规划约束,主要包括三个约束条件。本文创新点集中在这两部分:约束条件和矢量表征。具体细节如下:
在感知部分,地图查询(Map Query)采用数百个256维的查询向量,预测得到NM×NP×2维的地图矢量及其类别分数。其中,2表示坐标点维度,NP表示每个矢量的点数,NM表示地图上的矢量总数。
在智能体部分,通过类似于地图查询的QA机制,采用可变形注意力(deformable attention)学习智能体级别的表征。具体流程为:首先通过可变形注意力与共享的鸟瞰图(BEV)特征进行交互,再利用该表征预测运动矢量。这里预测的是智能体数量及其可能的轨迹模态(K表示轨迹条数)。
这表明了每个轨迹的驾驶意图(Driving Intention)。TF代表未来的时间戳,R则表示未来轨迹点的坐标情况。通过这种Query机制,我们可以预测出相应维度的向量(Vector)。这一部分最终关联到自车的状态。
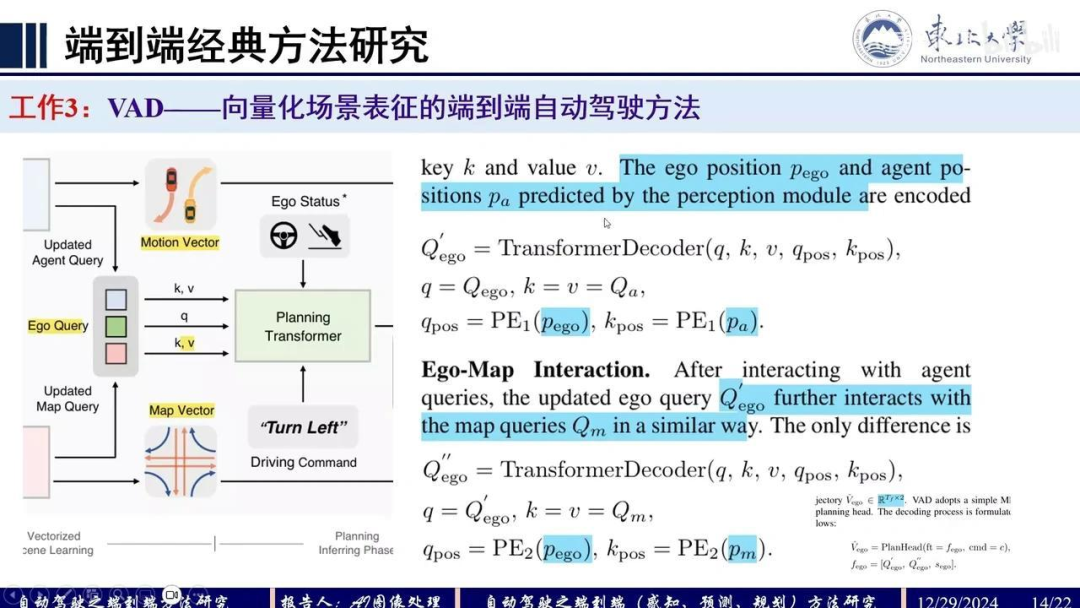
我们通过初始化的自车Query与先前的Motion Vector和Map Vector进行交互。交互过程采用纯Transformer Decoder架构,其中需要位置编码。位置编码来源于感知模块输出的自车和Agent坐标信息。
完成自车与Agent的交互后,再与Map进行交互。该结构与前述类似,但MLP编码部分采用了独立的新MLP。获得自车Vector后,进行预测,输出未来2024年12月29日时刻的确定性轨迹坐标点。
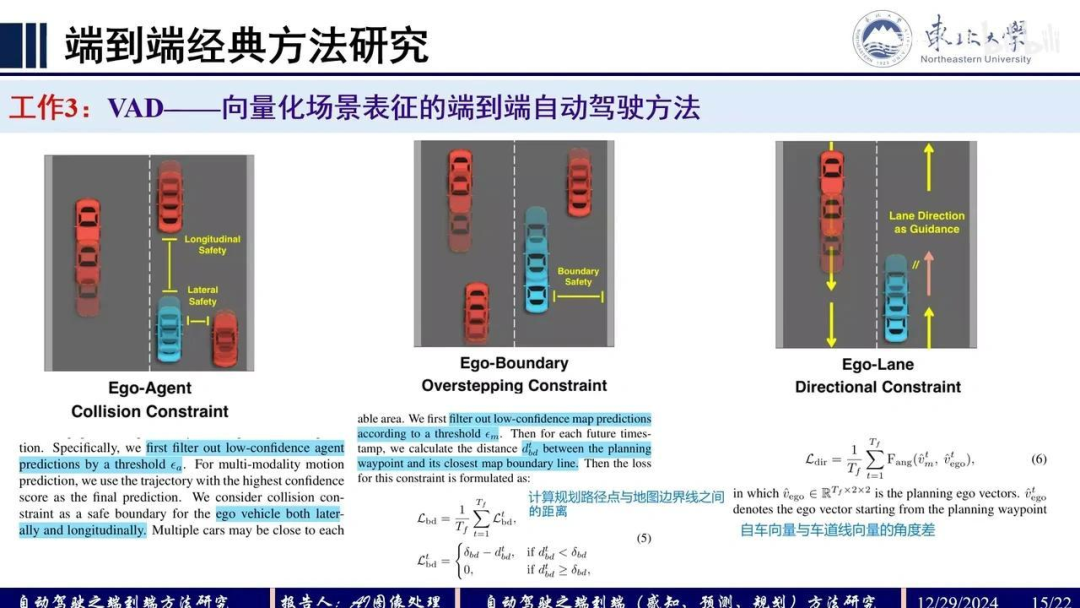
最优轨迹的输出需要考虑多个约束条件。该系统引入了三个主要约束:
自车与他车之间的碰撞约束,涉及横向和纵向距离;
自车与边界之间的距离约束,通过判断规划路径点与地图边界线之间的距离来实现;
自车方向约束,通过计算自车向量与车道线向量之间的角度差来确保行驶方向正确。
这些约束条件通过量化处理,并在规划过程中加入基于成本的抑制机制。
整个思想如下。他们的第二篇工作认为规划是一个不确定性任务,确定性方法无法处理掉头等情况。如图所示,作为红车,当前车处于此状态时,可以选择跟车或向右变道。若输出确定性轨迹,当存在两条真实轨迹(GT)时,模型会学习到中间状态的轨迹,容易导致碰撞。而本文采用概率化表征方法,将规划流视为概率分布,从而选择最优轨迹而非模糊折中方案。类似情况下,车辆可选择直行或向左变道,但确定性方法会学习中间表征导致碰撞风险。概率表征则能选择最优轨迹避免此类情况。
具体实现借鉴了类似GPT的ARP思想:首先初始化动作空间(action space),并将其离散化。连续的动作空间(如加速到10km/h、20km/h等)难以直接表征,故离散化为10、20、30等离散值。规划词汇表(planning vocabulary)可理解为字典,类似ARP中将字词存入字典供解码器选择。本文收集了4096种可能动作,如直行、加速至20km/h、刹车、左转、右转等,编码后生成planning token。通过场景token与planning token交互,结合自车状态和导航信息,预测动作分布并选择最优轨迹。
每个分布对应不同的运动概率,系统会选择概率最高的标准轨迹作为规划结果。这是该方法的核心思想。
针对左侧场景级分割部分,其动作空间采用五维连续表征。具体实现中,每个动作在规划词表中表示为一个路径点,通过将动作序列转化为路径点序列,便于后续编码处理。例如:加速至10公里/小时、加速至20公里/小时、左转、加速左转、加速右转、减速左转等不同运动状态都对应特定的路径点编码。
整个流程可以概括为:规划标记(planning token)直接与场景特征进行Transformer交互。其中,env代表场景级表征,ea表示对动作空间路径点的位置编码。位置编码函数τ的具体实现是将所有路径点与0到21维的特征拼接后进行编码,最终输出最优概率表征。
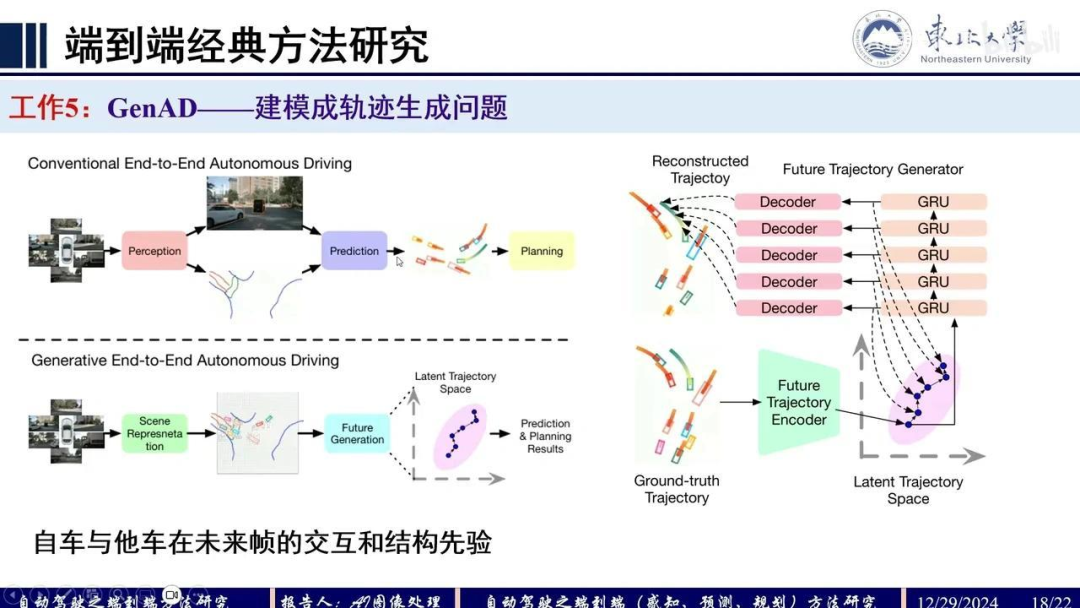
GenAD工作将自动驾驶建模为轨迹生成问题。不同于传统“感知-预测-规划”的级联方法,该方法考虑了自车与他车在未来帧中的交互,采用类似VAE的生成式建模思路:训练时学习轨迹分布,推理时采样分布并通过解码器生成路径点。关键点在于训练过程中如何构建有效的监督信号,这与VAE的训练思想一致。
将GT的track query trajectory通过编码器进行编码,得到latent space的轨迹表征。随后通过解码器重构当前轨迹,并将重构轨迹与原始真值轨迹进行监督训练。
在推理阶段,由于没有真值输入,直接利用学习得到的latent space表征作为输入,生成一个分布。通过采样该分布并解码,最终重构出轨迹。这是该方法的核心思想。
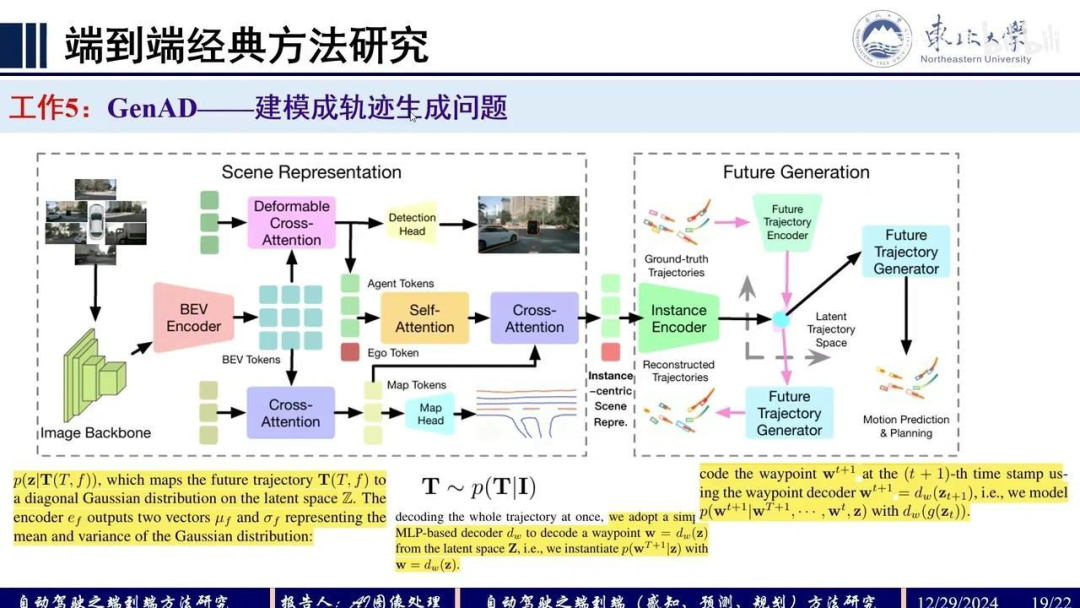
具体而言,左侧通过 token 之间的 cross attention 进行分割处理,输出以自车为中心的 BEV 场景表征,并输入到 InstanceGP Encoder 中。
在推理阶段,输出点分布采样后直接生成未来轨迹,通过 decoder 完成行为预测与规划。而在训练阶段,则利用 ground-truth 轨迹通过 encoder 编码得到分布,再经 decoder 解码生成重建轨迹,二者之间建立监督关系。
接下来,我们分析英伟达的研究成果。

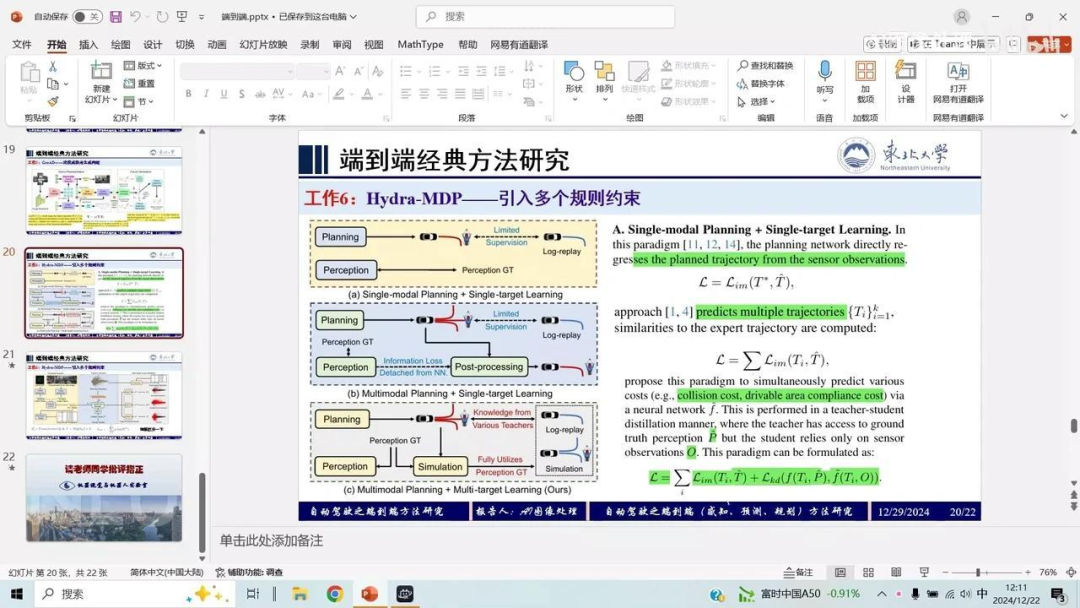
在前人工作的基础上,本研究引入了更多约束条件进行训练。先前模型采用单模态规划方法,即直接通过感知信息回归预测轨迹。而本研究提出多模态规划方法,以解决轨迹预测的不稳定性问题。该方法通过预测多个候选轨迹并选择最优轨迹进行模型学习。
具体而言,单模型学习仅预测单一轨迹,而多模型学习则预测多个轨迹。本研究结合了多模态规划与多模型学习方法,并在多轨迹预测的模型学习损失基础上,增加了知识蒸馏损失。该蒸馏损失来源于多种基于规则的教师模型,这些教师模型的结果通过仿真获得。
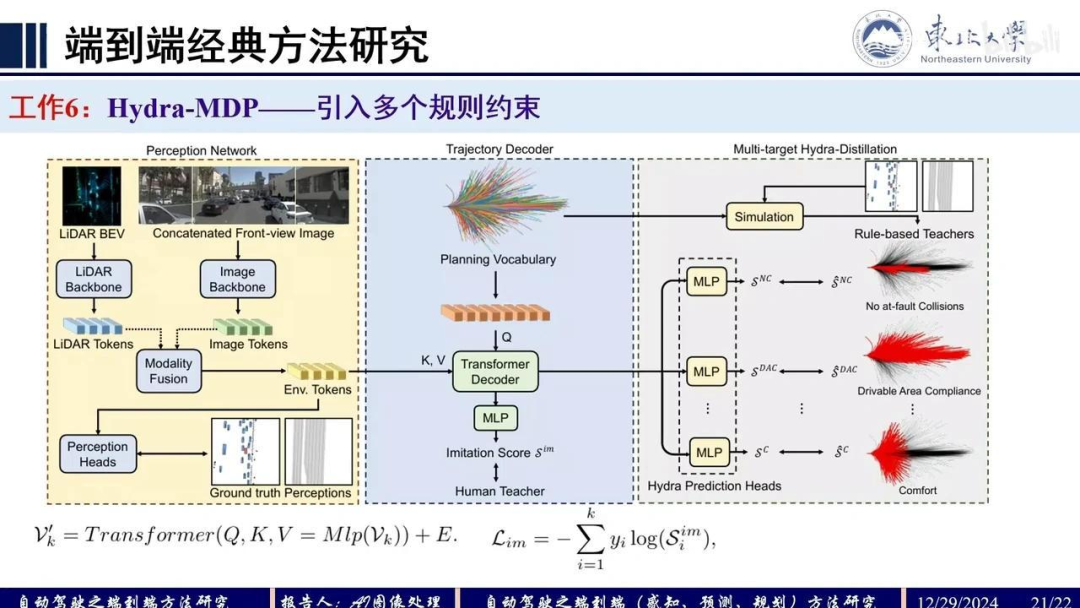
接下来,我们将模型的预测结果用于监督学习。该研究通过引入更多监督信息来提升模型性能。具体而言,其监督框架如下:
左侧模块采用TransFuser架构进行多模态融合,生成感知token。轨迹解码器(Trajectory Decoder)部分延续了VADV2中的规划词表(Planning Vocabulary)设计,通过Q向量与KV向量的交互进行编码,这与VADV2的处理方式基本一致。
额外监督信号来源于:将统计轨迹数据置于仿真环境中,生成基于规则的教师信号(Rule-based Teachers)。多层感知机(MLP)模块主要监督以下指标: 1. 无责任碰撞(No at-fault Collisions) 2. 可行驶区域合规性(Drivable Area Compliance) 3. 驾驶舒适性(Comfort)
这些监督指标均被纳入回归损失函数进行反向传播。其中,无责任碰撞特指非系统行为导致的碰撞事件。本文可视为VADV2研究框架的扩展。
当前端到端自动驾驶算法仍主要采用模仿学习框架,但存在以下局限性: 1. 作为纯数据驱动方法,其优化过程较为困难 2. 难以学习到最优真值(Ground Truth) 3. 对异常案例(Counter Case)的处理能力有限
这些方面仍有待进一步研究探索。关于端到端算法的讨论就到这里。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 4095
4095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









