



点击下方卡片,关注“具身智能之心”公众号
作者丨Yu Shang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

研究背景与核心问题
在具身智能领域,世界模型作为强大的模拟器,能生成逼真的机器人视频并缓解数据稀缺问题,但现有模型在物理感知上存在显著局限。尤其在涉及接触的机器人场景中,因缺乏对3D几何和运动动力学的建模能力,生成的视频常出现不真实的物体变形或运动不连续等问题,这在布料等可变形物体的操作任务中尤为突出。
根源在于现有模型过度依赖视觉令牌拟合,缺乏物理知识 awareness。此前整合物理知识的尝试分为三类:物理先验正则化(局限于人类运动或刚体动力学等窄域)、基于物理模拟器的知识蒸馏(级联 pipeline 计算复杂)、材料场建模(限于物体级建模,难用于场景级生成)。因此,如何在统一、高效的框架中整合物理知识,成为亟待解决的核心问题。
核心方法
问题定义
聚焦机器人操作场景,学习具身世界模型 作为动力学函数,基于过去的观测 和机器人动作 预测下一个视觉观测 ,公式为:
其中 为视频帧, 为k维连续动作控制向量。
机器人数据处理 pipeline
为构建含物理先验的多模态具身数据集,基于AGIBOT-World数据集设计了四步处理流程(figure 1):
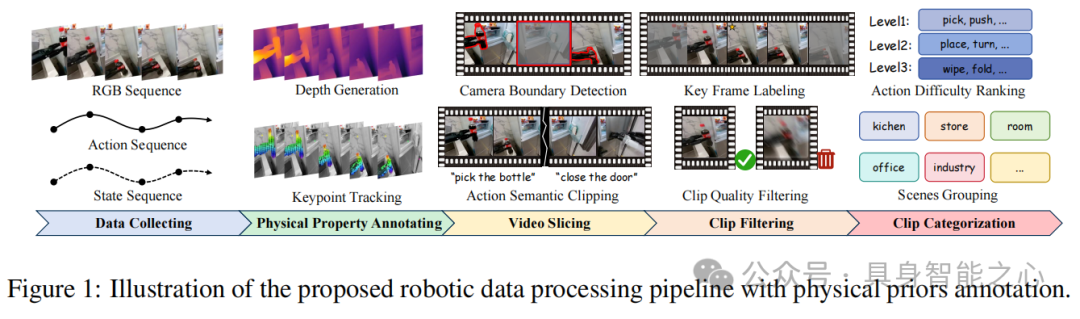
物理属性标注:用Video Depth Anything生成深度图序列,通过SpatialTracker进行关键点轨迹追踪,提取时间深度一致性和关键点运动轨迹这两种基础物理先验。
视频切片:结合TransNetV2的相机边界检测和Intern-VL生成的动作语义,将视频切分为属性归一化、运动一致、无相机跳跃且单动作语义的片段。
片段过滤:用FlowNet过滤运动模糊或模式混乱的片段,借助Intern-VL标记关键帧并过滤与关键帧无明确关联的片段,确保训练数据有效性。
片段分类:按动作难度(如pick、push为Level1;place、turn为Level2等)和场景(厨房、办公室等)分类,支持从易到难的课程学习策略。
RoboScape模型架构
基于自回归Transformer框架,实现帧级动作可控的机器人视频生成,核心是通过两个物理感知辅助任务整合物理知识(figure 2):
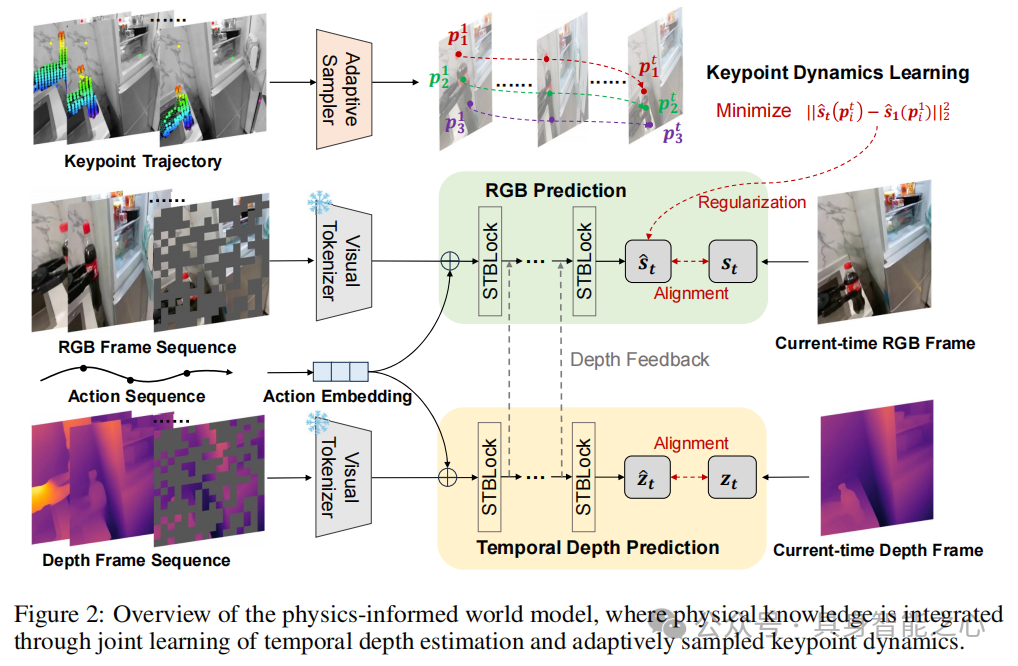
时间深度预测
为增强3D几何一致性,在RGB预测主干上增加时间深度预测分支,采用双分支协同自回归Transformer(DCT)。每个分支含堆叠的时空Transformer(ST-Transformer)块, temporal 注意力层用因果注意力保证生成因果性,空间注意力层用双向注意力实现全上下文建模。
在时刻 ,模型基于历史潜在令牌、动作嵌入 和位置嵌入 ,通过RGB分支 和深度分支 分别预测:
其中 为带广播的元素加法。通过跨分支交互,将深度分支的中间特征 投影后与RGB特征融合: ,使RGB生成保持精确几何结构。损失函数为令牌的交叉熵损失:
自适应关键点动态学习
为建模物体变形和运动模式,通过自监督追踪接触驱动的关键点动态,隐式编码材料属性(如刚性、弹性)。具体而言,用SpatialTracker在初始帧密集采样 个关键点并追踪其时间轨迹,基于运动幅度 自适应选择 top-K 活跃关键点。
通过损失强制采样关键点视觉令牌的时间一致性:
同时引入关键点引导的注意力机制,计算时空注意力图(A),增强关键点轨迹区域的令牌学习,注意力增强的训练目标为:
其中 在关键点轨迹区域取 (超参数),其他区域取1。
联合训练目标
整合上述损失,总目标为:
其中 为平衡各损失项的系数。
实验验证
实验设置
数据集:采用AgiBotWorldBeta数据集的50,000个视频片段,涵盖147项任务和72项技能,动作序列由末端位置、姿态和 effector位置拼接而成。
基线:对比4种先进模型,包括具身世界模型IRASim、iVideoGPT,以及通用世界模型Genie、CogVideoX。
实现细节:预处理为16帧片段(2Hz采样),约650万训练片段,用32张NVIDIA A800 GPU训练5个epoch(约24小时),超参数 , , , 。
视频质量评估
从外观保真度(LPIPS、PSNR)、几何一致性(AbsRel、δ1、δ2)、动作可控性(∆PSNR)三个维度评估(table 1):
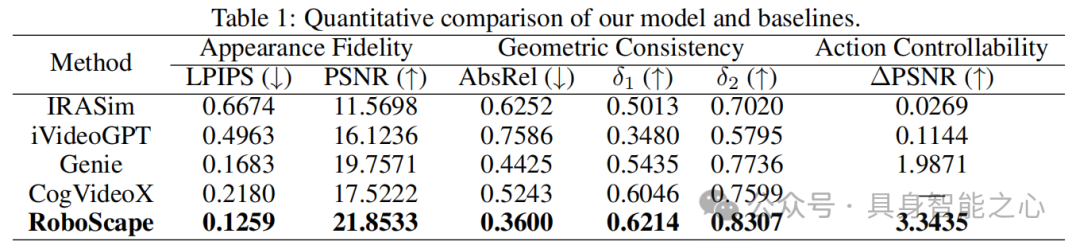
外观保真度:在LPIPS(越低越好)和PSNR(越高越好)上均优于所有基线,LPIPS达0.1259,PSNR达21.8533,说明生成视频的视觉真实性更强。
几何一致性:AbsRel(越低越好)为0.3600,δ1、δ2(越高越好)分别达0.6214、0.8307,体现出更优的3D几何稳定性。
动作可控性:∆PSNR达3.3435,显著高于基线,表明能更好地遵循动作指令生成视频。

消融实验(table 2)显示,移除时间深度学习或关键点动态学习均会导致性能下降:深度学习主要保障运动物体的几何一致性,关键点学习对视觉保真度和动作可控性至关重要(figure 4)。

下游应用验证
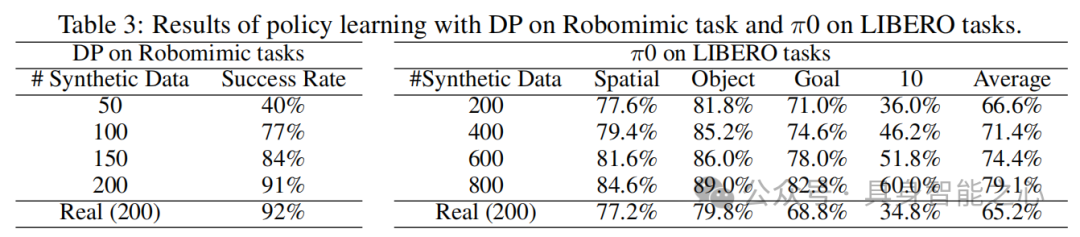
机器人政策训练:在Robomimic Lift任务中,仅用生成数据训练的Diffusion Policy(DP)性能接近真实数据训练结果,且成功率随合成数据量增加而提升;在LIBERO任务中,π0模型用生成数据训练后,性能超过真实数据训练的基线(table 3),表明生成数据对复杂操作任务的有效性。
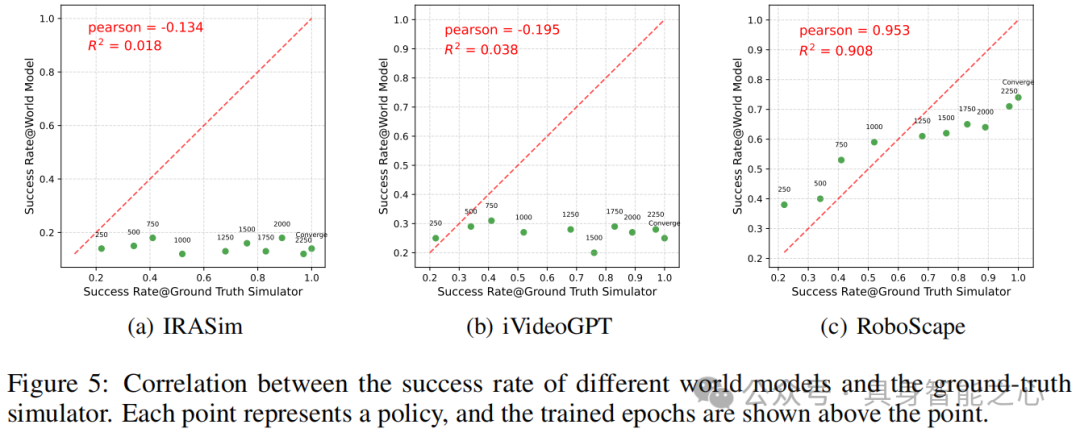
机器人政策评估:作为政策评估器时,与真实模拟器的Pearson相关系数达0.953,显著高于IRASim(-0.134)和iVideoGPT(-0.195)(figure 5),说明能可靠评估政策质量。
结论与展望
RoboScape通过多任务联合训练框架,将物理知识高效整合到视频生成中,无需级联外部物理引擎。时间深度预测使模型学习场景3D几何结构,动态关键点学习实现物体变形和运动模式的隐式建模,在视频生成质量、合成数据效用和政策评估有效性上均优于基线。
未来计划将生成式世界模型与真实机器人结合,进一步验证在实际场景中的表现。
参考
[1.]RoboScape: Physics-informed Embodied World Model


















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









