



点击下方卡片,关注“自动驾驶之心”公众号
AutoVLA
论文标题:AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
论文链接:https://arxiv.org/abs/2506.13757
项目主页:https://autovla.github.io/

核心创新点:
1. 统一的自回归模型架构
创新点 :首次将视觉-语言模型(VLM)与物理动作标记(Physical Action Tokens)直接集成,构建端到端的自回归规划策略框架,避免中间表示破坏端到端优化范式。
技术细节 :通过预训练的VLM主干(如Qwen2.5-VL)直接学习动作序列生成,联合优化高阶场景推理(Scene Reasoning)与低阶轨迹规划(Trajectory Planning)。
2. 双模式自适应推理机制
创新点 :提出“快思考”(Fast Thinking)与“慢思考”(Slow Thinking)的双推理模式,自适应切换以应对不同复杂度场景。
快思考 :直接生成轨迹(Direct Trajectory Generation),适用于简单场景。
慢思考 :基于链式思维(Chain-of-Thought, CoT)的复杂推理,用于处理长尾或交互密集场景。
实现方式 :通过监督微调(Supervised Fine-Tuning, SFT)联合训练轨迹数据与CoT推理数据,赋予模型“双过程能力”(Dual-Process Capability)。
3. 强化微调策略(RFT)与Group Relative Policy Optimization (GRPO)
创新点 :引入强化微调 (Reinforcement Fine-Tuning, RFT),通过惩罚冗余推理和对齐奖励函数优化策略,提升性能与效率。
技术细节 :
设计组相对策略优化 (GRPO)算法,计算组内相对优势(Relative Advantage)以指导策略更新。
目标函数包含策略梯度项(Policy Gradient)与KL散度正则化项,平衡探索与利用。
4. 物理动作标记化与可行动性约束
创新点 :提出物理感知动作标记化 (Physical Action Tokenization),将动作空间(如加速度、转向角)离散化为可学习的标记,确保生成轨迹的物理可行性。
优势 :避免传统方法依赖下游规划器生成轨迹的复杂性,直接输出符合动力学约束的动作序列。
5. 高质量推理数据集与自动化标注
创新点 :构建大规模、多模态的驾驶推理数据集 ,覆盖nuScenes、CARLA等真实与仿真场景。
技术实现 :
使用Qwen2.5-VL-72B模型自动生成高精度CoT标注(场景描述、关键物体识别、意图推理、动作决策)。
支持知识蒸馏(Knowledge Distillation),将大模型能力迁移至轻量化模型。
6. 实验验证与泛化能力
成果 :在nuPlan、Waymo、CARLA等真实与仿真数据集的开环/闭环测试中,AutoVLA在规划性能(如碰撞率、轨迹平滑度)与推理效率(减少冗余计算)上均达到SOTA。
核心优势 :通过自适应推理 (Adaptive Reasoning)显著降低简单场景的推理延迟,同时保持复杂场景的高精度规划。
X-Scene
论文标题:X-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability
论文链接:https://arxiv.org/abs/2506.13558
项目主页:https://x-scene.github.io/
核心创新点:
1. 多粒度可控生成框架 (Multi-Granular Controllability)
双模控制机制:
高层语义引导:用户自然语言提示经LLM(如GPT-4o)增强为结构化场景描述 ,包含场景风格、对象属性及空间关系(场景图 )。
底层几何约束:支持用户直接输入布局图或通过文本驱动布局生成模块(Scene-Graph-to-Layout Diffusion)自动生成精确的3D包围框与车道线。
RAG增强泛化:基于FAISS构建场景描述记忆库 ,实现少样本检索与上下文感知的场景生成(式1)。
2. 几何-外观联合生成与对齐 (Joint Geometry-Appearance Fidelity)
三平面形变注意力机制 (Triplane Deformable Attention):
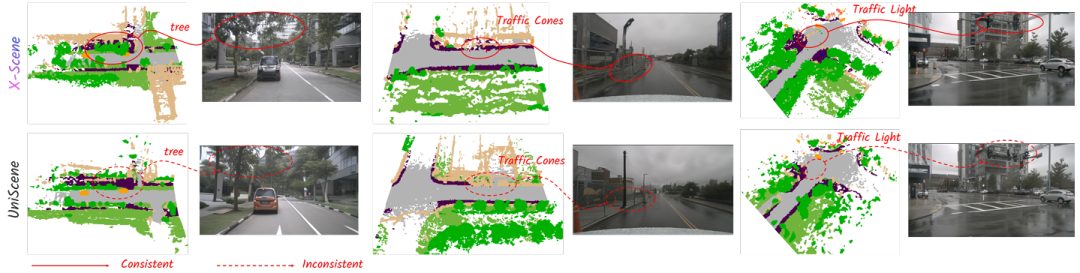
提出新型三平面编码器(式2),通过可学习偏移 聚合多平面特征,解决降采样几何信息丢失问题,提升3D语义占据(Semantic Occupancy)重建精度(表1:mIoU 92.4%,较UniScene +19.5%)。
3D感知图像生成:
级联生成流程:3D占据栅格 → 渲染语义/深度图 → 引导多视角图像扩散模型。
引入对象位置嵌入 强化几何对齐,确保2D图像与3D结构一致性(图5)。
3. 一致性感知的大场景外推 (Consistency-Aware Large-Scale Extrapolation)
三平面外推算法 (Triplane Extrapolation):
将3D场景扩展分解为三正交平面外推,通过重叠掩码 同步参考区域与新区域去噪过程(式3),保障空间连续性(图3a)。
视觉连贯图像外推:
融合参考图像 与相机位姿嵌入 微调扩散模型,解决跨视角外观不一致问题(图3b)。
大规模场景重建:生成结果可转换为3D高斯表达(3DGS),支持自由视角渲染与仿真应用(图4,9)。
4. 性能优势 (Quantitative Superiority)
占据生成:17类设定下FID³ᴰ=258.8(较UniScene↓51.2%),F-Score=0.785(表2)。
图像生成:448×800分辨率下BEV分割mIoU=69.06%(道路类),NDS=34.48(表3)。
下游任务:生成数据训练3D检测器mAP=28.2%(较MagicDrive↑15.9%),语义占据预测IoU=37.1%(表4,5)。
RelTopo
论文标题:RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
论文链接:https://arxiv.org/abs/2506.13553
核心创新点:
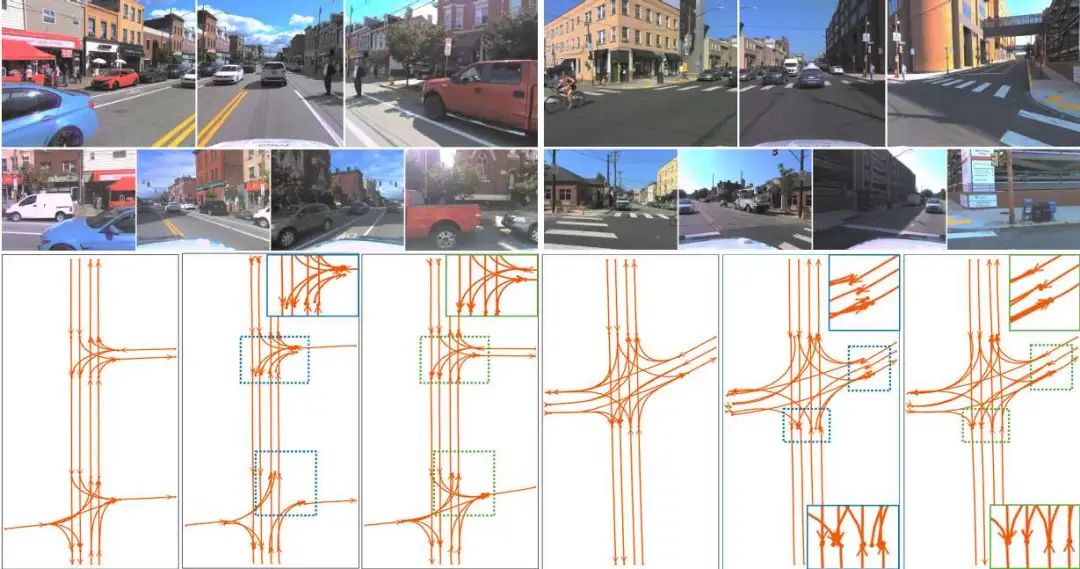
1. 关系感知的车道检测器
几何偏差自注意力(Geometry-Biased Self-Attention, GBSA)
将车道间的几何关系(如最小端点距离、角度差异)编码为注意力偏置,通过正弦嵌入和MLP生成高维几何关系特征,显式建模车道间的平行性、连通性等空间结构。曲线引导交叉注意力(Curve-Guided Cross-Attention, CGCA)
基于Bézier曲线参数化车道,通过采样曲线上点作为参考位置,利用共享车道查询动态生成偏移量和权重,聚合长程上下文信息,解决稀疏控制点的特征提取难题。
2. 几何增强的L2L拓扑推理模块
多模态关系嵌入
融合车道特征(MLP生成的前驱/后继嵌入)与几何距离特征(端点到起点距离的MLP编码),构建高维L2L关系嵌入(GL2L),降低对微小感知误差的敏感性。端到端优化
直接通过MLP预测拓扑关系,避免传统方法依赖后处理(如TopoLogic的几何距离拓扑后修正)。
3. 跨视图L2T拓扑推理模块
BEV-FV特征对齐融合
将BEV车道投影至前视图(FV)图像空间,提取对应FV特征并与BEV车道查询融合,结合位置编码(PE)对齐空间关系,解决BEV车道与FV交通元素(如红绿灯、标志)的空间表征差异问题。双视角关系嵌入
通过广播拼接生成L2T关系嵌入(GL2T),联合BEV和FV信息实现鲁棒的车道-交通元素关系推理。
4. 对比学习策略
InfoNCE损失优化
引入对比学习,增强模型区分正负样本对(连通/非连通)的能力。通过硬负样本挖掘(Top-n hardest negatives)和对称损失函数(Symmetric InfoNCE Loss),提升拓扑关系嵌入的判别性。
本文均出自自动驾驶之心知识星球,全栈技术社区,一键直达~
最后一天!618新人加入大额优惠~


















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









