 EfficientVLA:免训练加速和压缩VLA模型
EfficientVLA:免训练加速和压缩VLA模型




点击下方卡片,关注“具身智能之心”公众号
作者丨Yantai Yang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
出发点&写在前面
VLA模型,特别是基于扩散的架构,在具身智能领域展现出很大潜力,但其固有的和推理时的大量冗余导致了极高的计算和内存需求,严重阻碍了实际应用。现有加速方法往往针对孤立的低效问题,这种零散的解决方案通常无法全面解决整个VLA流程中各种计算和内存瓶颈,从而限制了实际部署。我们引入EfficientVLA,一个结构化的免训练推理加速框架,通过协同利用多方面的冗余来系统地消除这些障碍。EfficientVLA协同集成了三种针对性策略:(1)通过层间冗余分析,从语言模块中剪除功能上无关紧要的层;(2)通过任务感知策略优化视觉处理路径,选择紧凑、多样的视觉token集,平衡任务关键性和信息覆盖;(3)通过策略性缓存和重用关键中间特征,缓解基于迭代扩散的动作Head内的时间计算冗余。将方法应用于标准VLA模型CogACT,实现了1.93倍的推理加速,将FLOPs降低到28.9%,而在SIMPLER基准测试中成功率仅下降0.6%。
背景介绍
基于整合视觉和语言的多模态理解模型的进展,VLA模型实现了变革性的具身智能。如OpenVLA、CogACT、π0和RT-2,直接将多模态输入转化为可执行动作,利用大规模数据集成功解决复杂的机器人操作和推理任务。许多前沿VLA将用于场景和指令解析的视觉-语言模型(VLM)与扩散模型结合,以处理多模态动作分布。然而,这些基于扩散的VLA架构在推理时的巨大计算和内存开销,成为其实际部署的关键障碍,尤其是在资源受限的机器人平台上进行实时交互时。
基于扩散的VLA架构通常包括用于提取特征的视觉编码器、用于多模态推理的大型语言模型(LLM)核心,以及用于通过多个去噪步骤预测最终动作的基于扩散的动作解码器。尽管这种模块化设计是其强大能力的基础,但它本质上导致了巨大的计算和推理速度及计算效率(FLOPs)问题。表1:基线VLA模型(CogACT,左)与我们提出的EfficientVLA(右)的模块推理特性比较。EfficientVLA在整体上显示出显著改进。
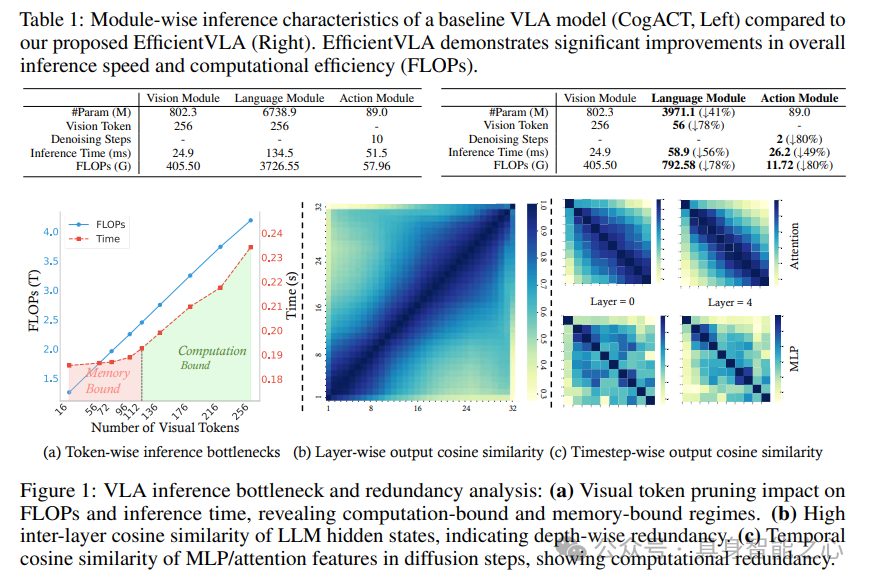
发现(表1)表明,语言模块和迭代扩散Head是整体延迟和计算负载的主要贡献者。此外,如图1(a)所示,虽然视觉token修剪在计算受限场景中最初减少了推理时间,但随着系统被LLM的内存限制所束缚,其效果迅速减弱。
先前的VLA加速工作主要集中在孤立的调整上,整体增益最小。这些零散的方法往往失败,因为它们忽略了VLA的集成性质,孤立优化一个模块只会转移瓶颈。未解决的其他地方的低效限制了收益,例如LLM的内存需求或动作Head的计算强度。TinyVLA和DeeR-VLA等方法关注专门的模型架构,而不是适用于预训练VLA的广泛适用的推理加速框架。其他方法,如Mole-VLA,解决了LLM层冗余,但需要昂贵的再训练,并且忽略了其他流程阶段。同样,VLA-Cache缓存静态视觉token,但由于LLM的大量内存占用和动作Head的计算需求,加速有限。因此,这些现有方法未能提供真正全面的解决方案来应对VLA低效的复杂局面。
为了开发更有效的加速策略,这里系统地分析了每个VLA模块内的推理特性和多方面的冗余。在许多基于扩散的VLA中,扩散动作Head作为一个独立模块运行,由从VLM提取的特征引导。这种分离可能未充分利用VLM的全部推理能力来生成动作,质疑其整个规模的必要性。如图1(b)所示,语言模块表现出相当大的深度方向表示冗余,层间隐藏状态相似度高。视觉处理路径通过处理多余的token加剧了这个问题,这些token由于视觉相似性而具有低任务相关性或高信息重叠,这给计算资源带来压力,并加剧了LLM的内存受限状况。如图1(c)所示,迭代扩散动作Head显示出显著的时间冗余。其相邻去噪步骤中间特征的高相似度意味着广泛且近乎静态的重复计算。
受此启发,这里引入EfficientVLA,一个结构化的、免训练的基于扩散的VLA加速框架,系统地针对这些问题。EfficientVLA使用基于相似度的重要性度量来针对语言模块的主要内存瓶颈及其观察到的深度方向冗余(图1(b)),采用基于相似度的重要性度量来剪除功能上无关紧要的层,从而在不重新训练的情况下减少模型深度和内存需求。为了在达到LLM内存限制之前管理来自视觉输入的初始计算负载(图1(a)),视觉token修剪策略通过首先选择关键的任务对齐token,然后扩充这个集合以确保表示多样性,同时保持高任务相关性,来解决任务相关和固有的图像冗余。最后,EfficientVLA通过缓存和重用中间注意力和MLP输出,解决计算密集型动作生成器中的时间冗余(由跨时间步的高特征相似度突出显示,图1(c)),从而减少冗余计算。这种协同的、结构化的方法比孤立的优化更全面地缓解了GPU计算和内存瓶颈。
主要贡献如下:
提出了系统分析,确定了当代基于扩散的视觉-语言-动作(VLA)架构中的关键计算和内存受限瓶颈,以及多方面的冗余,从而激发了结构化加速的需求。
提出了EfficientVLA,这是一种新颖的免训练、结构化推理加速框架,它基于信息影响协同修剪语言模块中的冗余层,并通过考虑VLA任务相关性和固有图像特征多样性,策略性地选择紧凑的、以任务为中心的视觉token子集。
框架通过利用基于扩散的动作Head中的时间冗余,引入了迭代去噪过程中中间注意力和MLP计算的缓存机制,进一步提高了效率。
通过在SIMPLER环境中的CogACT上进行的广泛实验证明了EfficientVLA的有效性,实现了1.93倍的推理加速,并将FLOPs降低到28.9%,同时仅导致0.6%的最小精度下降。这将促进大规模VLA在现实世界中资源受限的机器人平台上的应用。
EfficientVLA方法
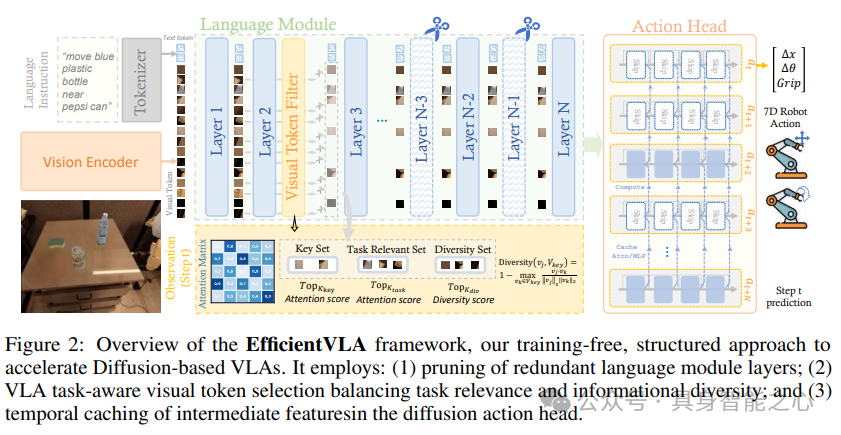
VLA模型
视觉-语言-动作(VLA)模型是一类多模态系统,旨在架起感知、语言理解与机器人动作之间的桥梁。这类模型通常通过一系列专用模块处理图像观测与自然语言指令,以生成可执行的动作序列。基础VLA模型的初始阶段采用视觉模块,包含强大的预训练编码器DINOv2和SigLIP,将原始视觉输入 转换为一组丰富的特征嵌入 。这些视觉特征 与token化的语言指令共同输入语言模型主干,该LLM执行多模态融合与context推理,导出面向任务的表示或条件信号 ,其封装了对场景及指令目标的理解。最终,基于扩散的动作Head将从 提取的认知特征作为输入,预测7自由度(DoF)机械臂的最终动作空间。
视觉-语言模型修剪
1)层冗余分析
VLA模型中的语言模块(通常为多层Transformer解码器)是多模态推理的核心,但也引入了巨大的计算开销。Transformer中每个层 通过残差变换更新输入隐藏状态 :
其中 是带参数 的层特定函数, 为隐藏维度, 为序列长度。如图1(b)所示,实证分析表明该语言模块存在显著的深度方向表示冗余——许多层(尤其是较深层)的输入 与输出 状态间余弦相似度极高,意味着这些层的有效变换 极小,功能上非关键,是修剪以提升推理效率的理想候选。
2)重要性驱动的非连续层修剪
为解决语言模块的深度冗余,首先量化各层的功能重要性,以识别对隐藏状态变换贡献最小的层。重要性分数 定义为:
其中 和 分别为层 中样本 的位置 处的输入与输出隐藏状态向量。高余弦相似度对应低重要性分数,表明功能冗余。基于分数对层排序后,选择重要性最低的前 层进行非连续修剪。
任务相关性与多样性驱动的视觉token修剪
VLA模型处理的视觉token流常存在显著冗余,表现为两类:(i)与任务目标相关性低的token;(ii)因视觉相似性导致的信息重复token。为此,我们提出免训练的任务感知修剪方法,从初始token集 中提炼出大小为 的紧凑子集 ,通过以下步骤实现:
1)量化任务相关性
利用选定VLM层的交叉注意力分数量化每个视觉token 的任务相关性。设 为视觉token 对第 个注意力头中第 个上下文token的注意力,则原始相关性分数 为:
经归一化后得到标准化分数 。
2)关键任务相关token选择
选取 个相关性最高的token构成核心集 :
剩余候选token集为 。
3)平衡相关性与多样性的增强选择
为达到目标token数 ,从 中选取 个token:
任务驱动增强:按比例 选取 个高相关性token,构成 ;
多样性驱动增强:对剩余
个token,通过余弦距离计算与
的相异度:
选取相异度最高的token构成
;
最终修剪集: 。
动作预测中的中间特征缓存
基于扩散的VLA模型生成动作序列时,需通过 个时间步的迭代去噪,重复的自注意力与MLP计算带来巨大计算开销。如图1(c)所示,动作生成过程中的中间特征具有强时间连贯性,为此我们提出静态缓存机制:
设定缓存间隔 ,在初始时间步 计算并存储特征 和 ;
后续时间步中,仅当
时重新计算并更新缓存,其余时间步直接重用缓存特征:
该策略每 个时间步仅执行1次完整计算,大幅减少动作生成的计算开销。
实验对比分析
实验设置
1)仿真实现细节
采用SIMPLER环境评估VLA模型,该基准专为桌面操作设计,支持两种配置:
视觉匹配(VM):最小化仿真与真实环境差异,侧重外观保真度;
变体聚合(VA):引入光照、背景等变化,挑战模型泛化能力。
测试任务包括:拾取可乐罐、移近目标、开关抽屉、打开顶层抽屉放置苹果,采用成功率作为评估指标。
2)基线模型
以CogACT为基准,其集成DINOv2和SigLIP视觉编码器、Llama2-7B语言模块及扩散动作Head。对比方法包括:随机保留112个视觉token的Random Dropping、专注视觉token修剪的FastV,以及利用时间冗余缓存token的VLA-Cache。
3)实现细节
EfficientVLA中,语言模块采用PruneNet[39]配置,对所有Transformer块的MLP层应用25%稀疏度;视觉token修剪从第2层Transformer开始,取 、 ;动作Head缓存间隔设为5。实验在NVIDIA A40 GPU上进行,推理时间取单步平均值。
仿真环境结果
1)SIMPLER主要结果
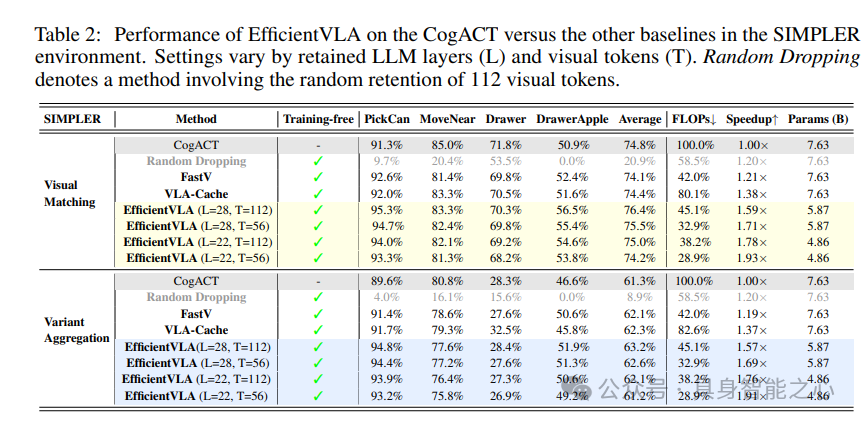
表2显示,EfficientVLA在保留22/28层、56/112视觉token的各配置下均表现优异。例如,修剪10层并保留112个token时,成功率和推理速度均超越CogACT与VLA-Cache;在拾取可乐罐任务中,剪除36%参数后成功率反从91.3%提升至94.0%,凸显VLA模型的参数冗余。相比之下,随机丢弃token至112个时平均成功率骤降至20.9%,验证了引导式选择的优越性。最优配置(22层+56token)实现FLOPs降低71.1%,平均成功率仅降0.6%。
2)效率分析
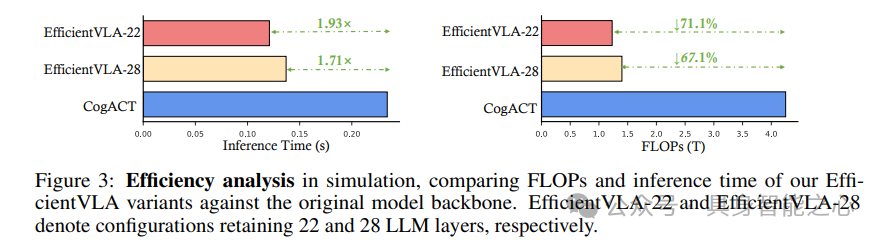
EfficientVLA实现1.93倍推理加速,FLOPs减少71.1%,显著优于VLA-Cache的1.38倍加速与19.9% FLOPs降低。这证实了VLA-Cache受限于LLM内存瓶颈,而结构化框架能更全面地平衡效率与性能(表2、图3)。
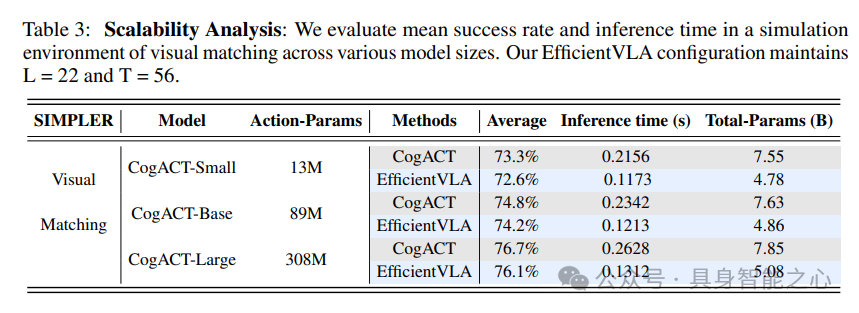
3)可扩展性评估
表3表明,模型规模越大,EfficientVLA的加速效果越显著。在CogACT-Large模型上,加速比达2.0倍,而成功率仅从76.7%微降至76.1%,验证了方法在不同规模模型中的鲁棒性。
消融研究
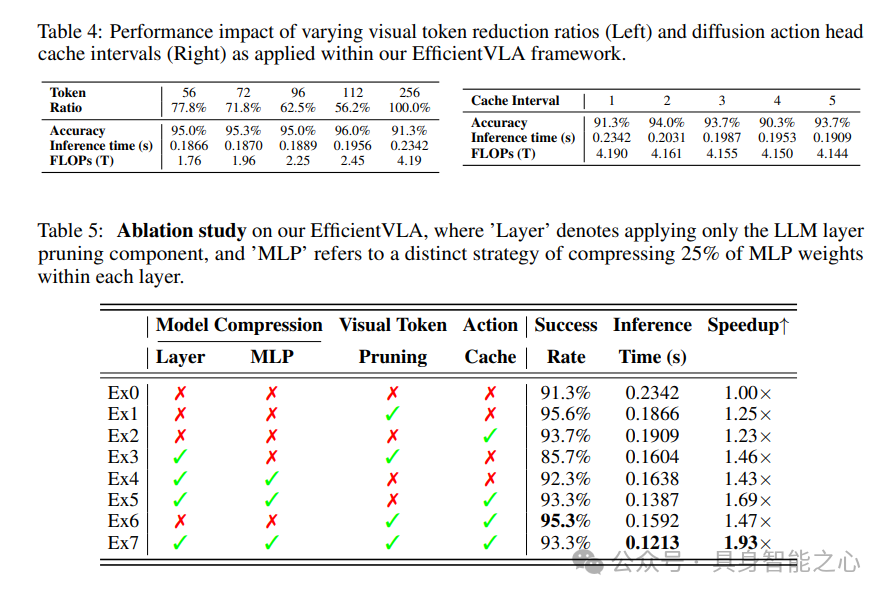
针对拾取可乐罐任务的消融实验(表5)显示:
单独优化视觉token(Ex1)仅实现1.25倍加速,但成功率提升至95.6%,暴露了纯token优化的局限性;
结合语言层修剪与MLP压缩(Ex4)实现1.43倍加速;
全组件集成(Ex7)达到1.93倍加速,且成功率较基线提升2%,验证了结构化框架的必要性。
参考
[1] EfficientVLA: Training-Free Acceleration and Compression for Vision-Language-Action Models


















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









