



点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享理想团队最新的工作!DriveAction: 面向VLA模型的人类化驾驶决策基准!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『VLA』技术交流群
论文作者 | Yuhan Hao等
编辑 | 自动驾驶之心
背景与挑战
当前自动驾驶领域的Vision-Language-Action (VLA) 模型虽取得进展,但现有评测基准存在三大局限:
场景多样性不足:依赖开源数据集(如nuScenes、Waymo),覆盖场景单一,关键场景(匝道汇入、施工区、行人交互)代表性弱。
动作标注可靠性低:多数基准缺失动作级标注,或依赖人工事后标注,无法真实反映实时驾驶意图。
评估逻辑偏离人类决策:主流评估采用前向链式逻辑(感知→预测→规划→动作),未建立以目标动作为核心的依赖关系。
核心创新
1. 用户贡献的广覆盖驾驶场景
数据来源:量产自动驾驶车辆用户主动采集的真实驾驶数据,覆盖中国148个城市(Table 1对比)。

场景分类:7大类场景(Table 2),包括:
匝道汇入/分离(On/Off Ramp)
效率导向变道(Efficiency Lane Change)
弱势道路使用者避让(Bypass VRU)
复杂路口转向(Intersection)等

数据规模:2,610个驾驶场景生成16,185个QA对。
2. 人类驾驶偏好对齐的真值标注
标注方式:直接记录用户实时操作(如方向盘转角、踏板深度),离散化为高层动作标签。
质量保障:人工验证排除错误/不合理/非法行为(如误加速、无故急刹、压实线)。
设计优势:匹配端到端大模型输出粒度,体现人类决策的离散性特征(对比Table 1的Label列)。
3. 动作驱动的树状评估框架
框架设计(figure 1):
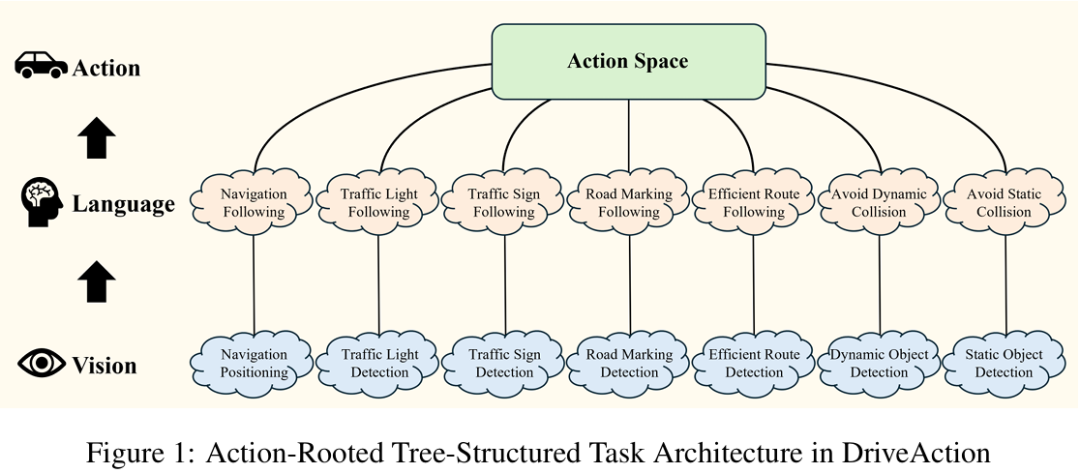
根节点:动作空间(如变道、路口转向)
中间层:语言任务(如导航跟随、交通灯理解)
叶节点:视觉任务(如车道线检测、标志识别)
场景信息注入:
连续3帧视觉输入(支持时序推理)
车载导航指令(提供路径规划目标)
自车/目标车速(量化驾驶状态)
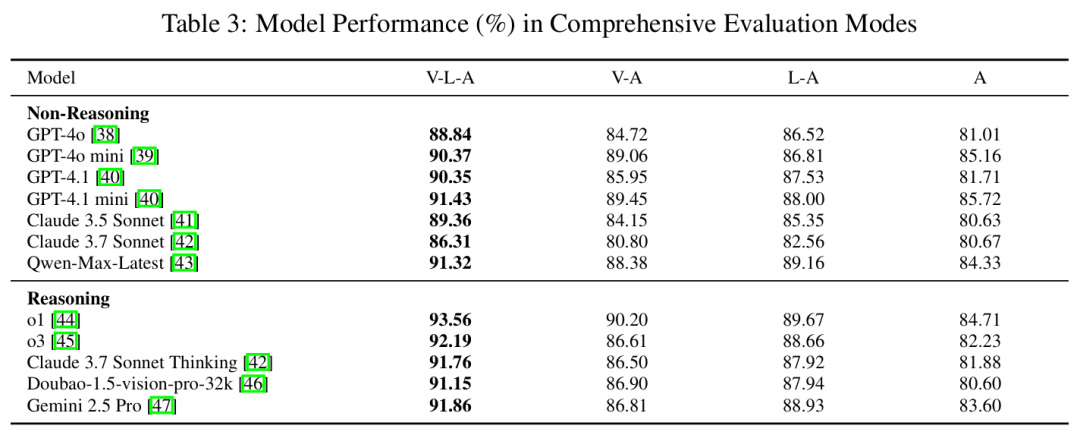
灵活评估模式(Table 3):
关键实验结果
多模态必要性验证
双模态依赖性:移除视觉输入平均精度下降3.3%,移除语言输入下降4.1%,同时移除下降8.0%(Table 3)。
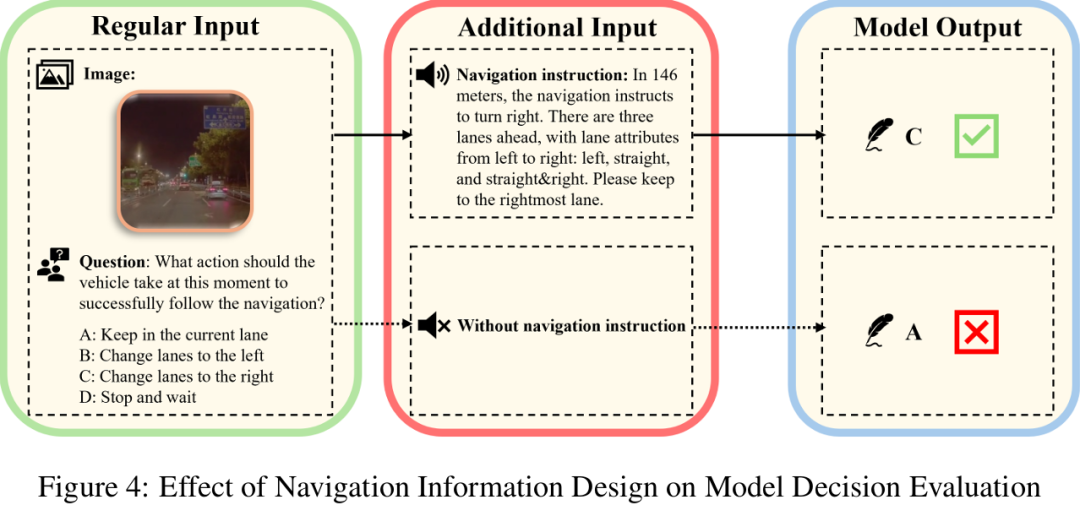
典型案例:缺失导航信息时,模型在匝道前错误选择直行而非变道(figure 4)。
任务特异性表现
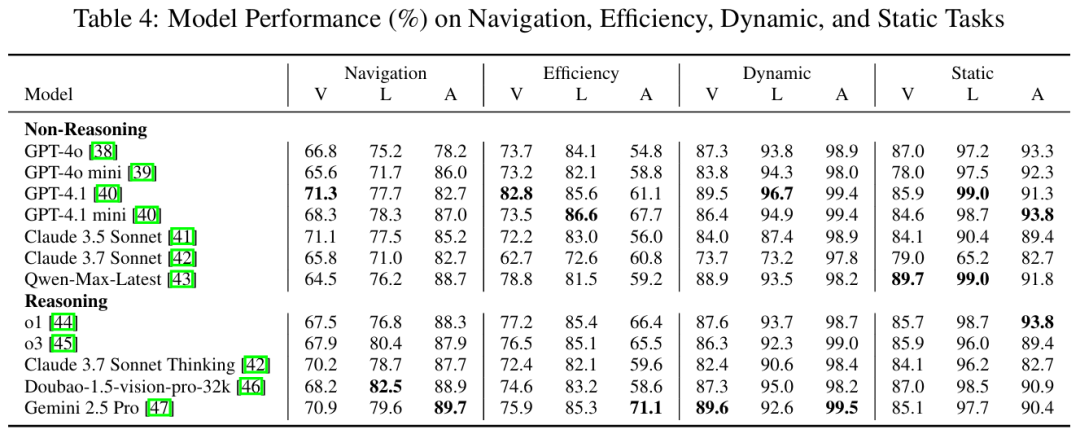
导航任务瓶颈:模型在车道定位(Navigation Position)任务准确率仅66.8-71.3%(Table 4)。
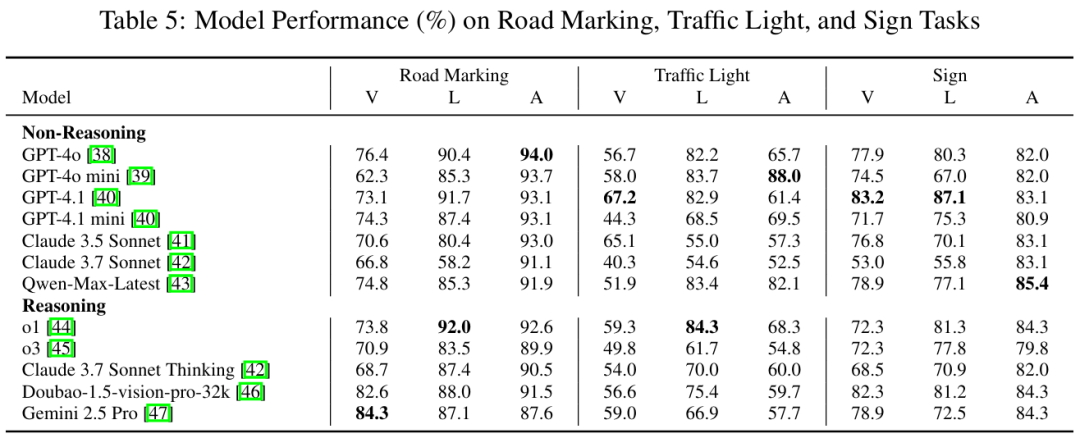
交通灯识别挑战:部分模型在Traffic Light Detection任务准确率低至40.3%(Table 5)。
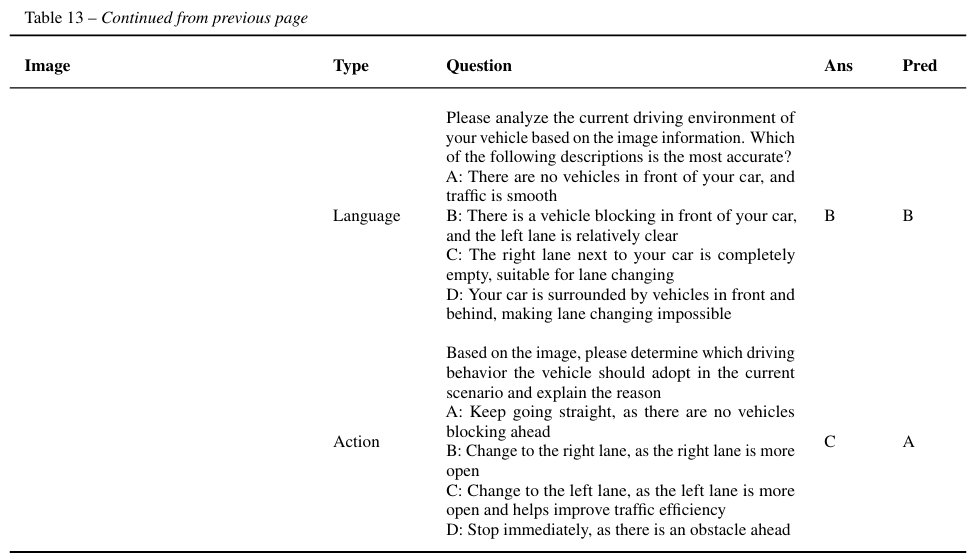
效率决策保守性:面对慢车阻挡时,模型倾向保持车道而非高效变道(附录Table 13案例)。
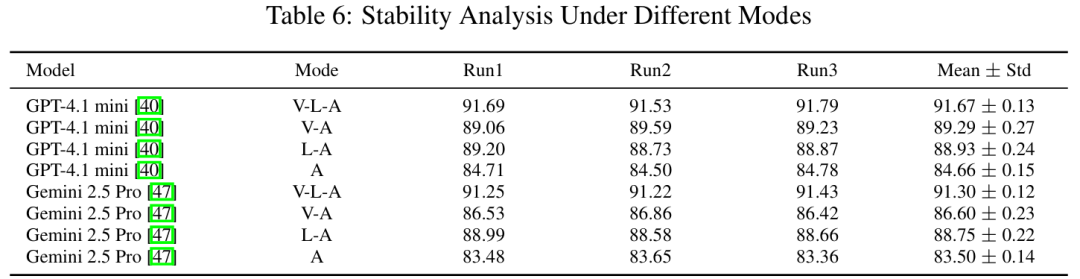
模型稳定性
最佳稳定性:GPT-4.1 mini和Gemini 2.5 Pro在重复实验中标准差<0.3(Table 6)。
推理模型优势:在V-L-A模式下,o1模型精度达93.56%(Table 3),但该优势在信息缺失时减弱。
未来展望
驾驶风格个性化:分析模型决策偏好(保守型/主动型),为用户推荐适配模型。
长尾场景扩展:增强极端天气、夜间低光照等场景覆盖。
多模态依赖解耦:深入探究视觉/语言信号在复杂决策中的权重分配机制。
实时性优化:树状框架的动态任务组合机制可进一步压缩推理延迟。
核心价值:DriveAction通过
动作驱动的评估范式,为VLA模型提供了紧贴人类驾驶逻辑的评测标尺。其树状框架设计(figure 1)和场景信息注入机制(如连续帧+导航指令)为自动驾驶的可解释性研究开辟了新路径。
参考
[1] DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1890
1890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









