 自动驾驶轨迹预测综述剖析
自动驾驶轨迹预测综述剖析




作者 | 莫铭棋Mio 编辑 | 具身智能之心
原文链接:https://zhuanlan.zhihu.com/p/30519437101
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『轨迹预测』技术交流群
本文只做学术分享,如有侵权,联系删文
今天拜读一篇比较新的关于轨迹预测方面的文献综述《Motion Forecasting for Autonomous Vehicles: A Survey》,希望对入门这一方向的研究人员起到帮助。原文链接:
Motion Forecasting for Autonomous Vehicles: A Survey
arxiv.org/abs/2502.08664
1 引言
准确预测众多交通参与者(agent)的未来行为对自动驾驶决策来说十分重要。
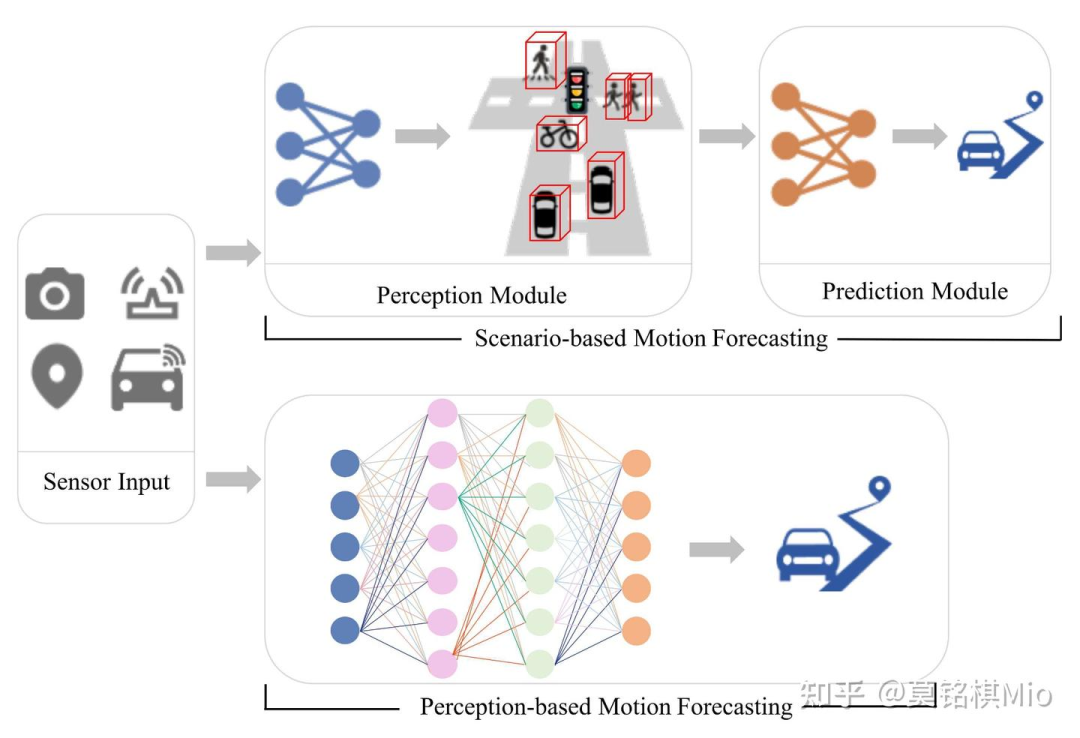
因此,作者将轨迹预测分为了scenario-based和perception-based两种类型。
scenario-based类:根据周围agent的历史状态以及环境信息(如HDmap)来预测agent的未来状态,这种方法是一种结构化的方法,摒弃掉如图像、点云等传感器数据,更集中于分析交通环境以及agent之间的交互。
perception-based类:顾名思义,直接用来自于传感器的感知数据,直接预测agent未来的轨迹,这种方法能更好地利用原始数据,以理解更复杂的场景。
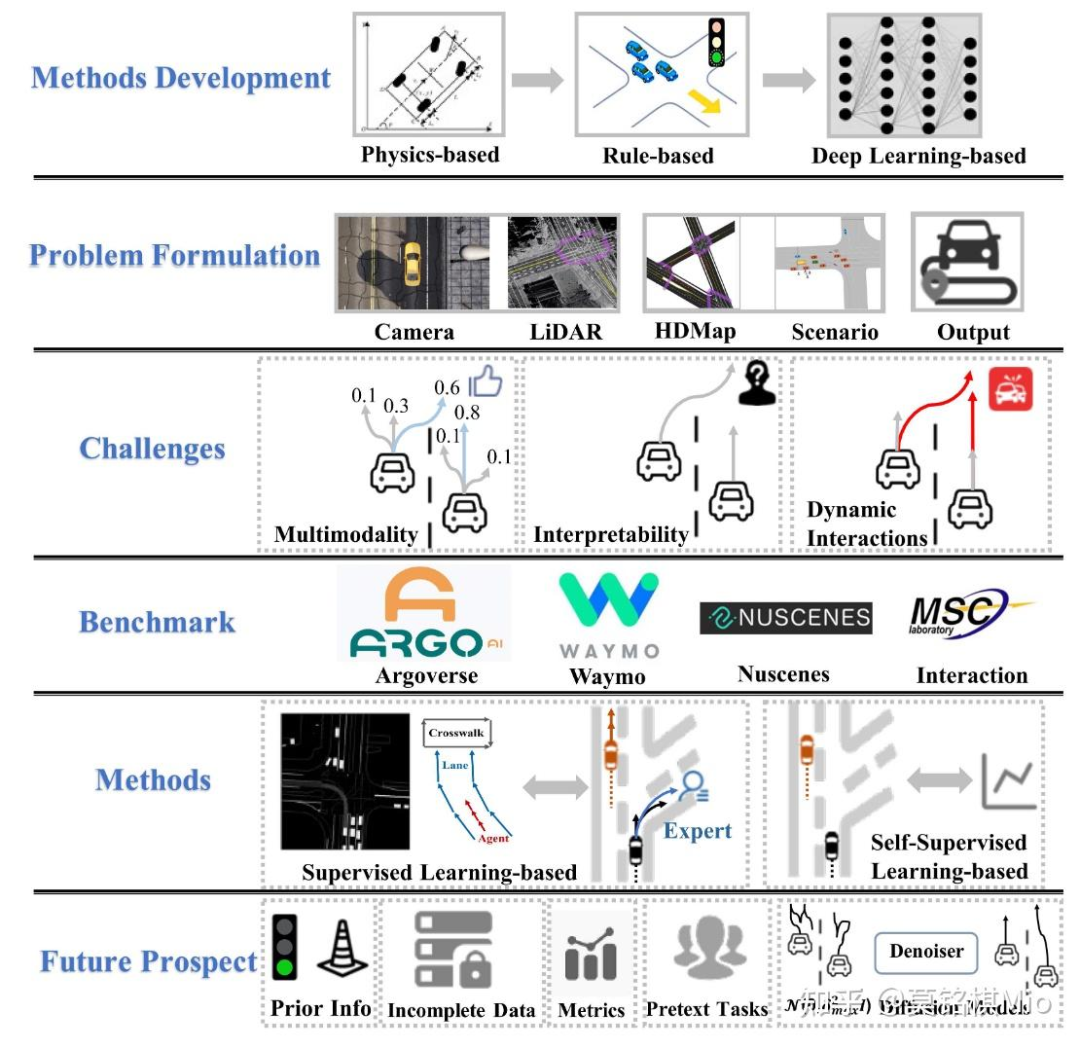
从发展历史来看,作者总结了三个阶段,即physics-based models, rule-based models, and deep learning-based models.
其中physics-based models通过物理规则来预测短期的轨迹,通过车辆位置、加速度,航向角等信息来估计未来的行动,但是这种方法忽视了环境因素以及agent之间的交互,无法适应复杂环境。
rule-based models基于交通规则以及人类的先验知识,以一种固定的方式预测轨迹,这种方式符合直觉,且计算复杂度低。然而,这种方法缺乏泛化能力,难以应对复杂场景下的非线性交互。
deep learning-based models是目前最主流的轨迹预测方法,也是这篇文章所讨论的重点,在这类方法的早期阶段, supervised learning,如RNN-based networks、Graph-based networks、Transformer-based networks,在分析时空数据的复杂性上的表现十分优秀,但这类算法需要大量高精度的标注数据,而self-superviesed learning方法,却能够通过数据增强等手段,缓解高质量数据不足的问题。
2 问题表述
2.1 输入类型
轨迹预测的输入能够分为三种类型,即Scenario Representation、Bird’s Eye View (BEV) representation以及raw perception data.
raw perception data指的是来自于传感器的原始数据,如三维点云以及二维图像
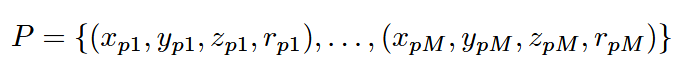
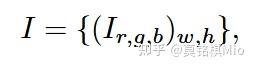
Scenario Representation包括两部分High Definition (HD) Map 以及 过去 时间段内 SAs的状态。
其中HD Map的数据格式如下
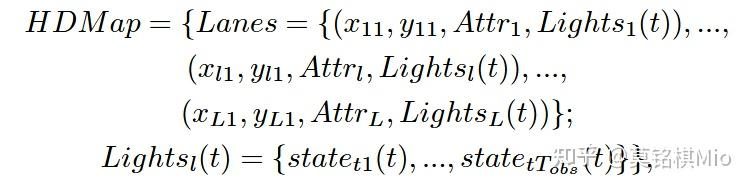
(x,y)为坐标,Attr为路段的特性,如是否为交叉口,是否有限速等,Light代表了信号灯信息(红黄绿)。
对于SAs的过去信息,则为:
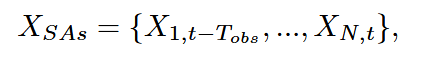
其中X代表了N个SA在 过去 时间内的状态,包含位置,速度,朝向等信息。
BEV representation 是将原始感知数据转化为2D网格数据,简化处理复杂空间关系的流程。
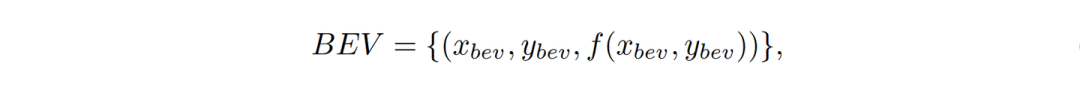
其中 和 是 BEV平面的二维坐标,f( )代表了从原始数据中提取的特征,如是否占用,速度,或者如道路标记、可驾驶区域等语义信息。
2.2 输出类型
1)Marginal Trajectory Prediction:TA的轨迹不会影响到其他agent,将每个TA的轨迹分布视作独立的,如下:
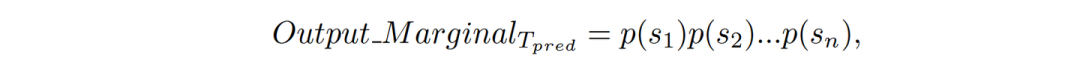
2)联合多智能体预测:考虑这一场景下所有TA的未来轨迹的交互作用,将其视为一个整体进行预测,其目标函数如下:
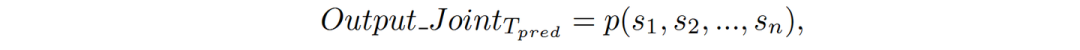
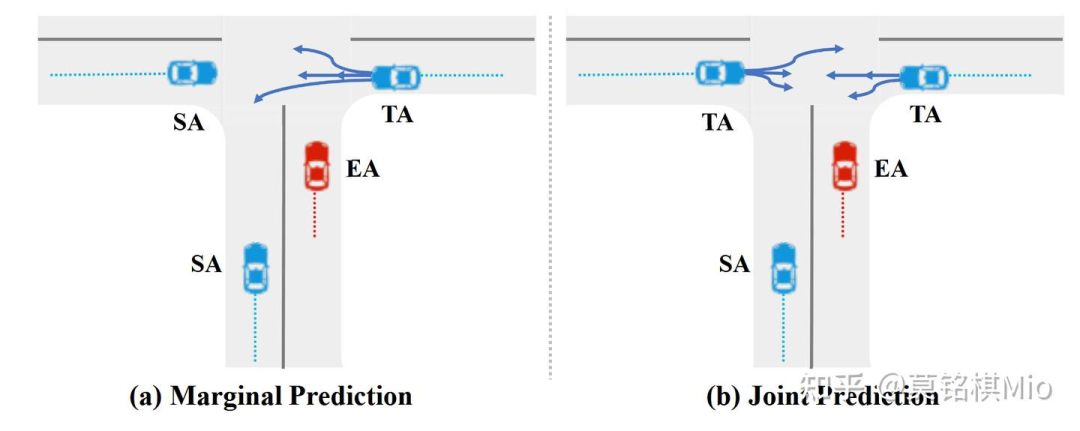
目前主流的预测输出都是后者。
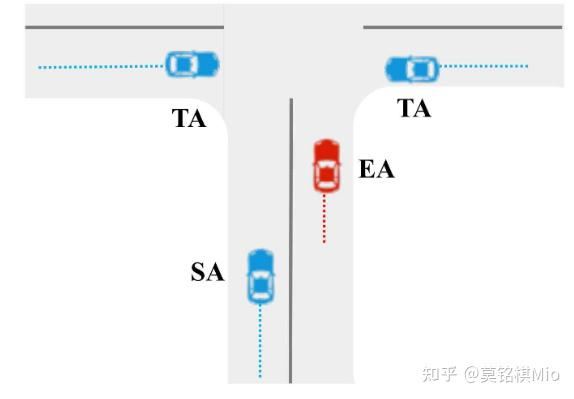
3 目前的挑战
在自动驾驶领域,对交通参与者(TAs)的运动预测对于自动驾驶汽车(EA)的下一步行动具有很强的辅助作用。然而,由于交通环境的复杂性和灵活性,准确预测TAs的运动仍然是一个具有挑战性的任务。
高精地图信息的融合
为了推动自动驾驶领域的发展,研究人员利用更详细的特征,并通过构建高精地图(HDMaps)实现了车辆行为预测的厘米级精度。这些高精地图提供了丰富的上下文信息,例如车道边界、交通标志和道路几何形状,这些信息对于做出精确可靠的预测至关重要。然而,高精地图数据格式和内容缺乏统一标准,这给数据对齐和关联带来了重大挑战。如何在车辆行为预测中建立高精地图与交通参与者轨迹之间的数据对齐和关联,并有效整合这些信息,是一个巨大的挑战。
不同车辆之间的动态交互
道路环境对车辆行为的影响是静态的,而自动驾驶汽车(SAs)与交通参与者之间的交互是动态且不确定的,这给捕捉这种复杂的相互作用带来了重大挑战。例如,车辆在交叉路口右转的决策涉及与右转车道的静态环境的交互。然而,SAs与TAs之间动态且多变的交互增加了复杂性,使得对这些交互模式的分析和解释变得更加困难。
车辆行为的多模态性(不确定性)
在自动驾驶中,理解交通参与者和自动驾驶汽车的行为至关重要,因为它们具有固有的多模态性,即单一历史轨迹可能导致多种潜在的未来轨迹。将交通参与者的轨迹与道路信息相结合,可以为驾驶员的驾驶风格提供有价值的见解,尤其是他们对特定路段的熟悉程度。对交通参与者历史运动模式的深入分析能够识别出各种可能的未来行为。因此,自动驾驶系统中的有效运动预测模块应该能够识别所有这些潜在的未来行为。这种能力对于确保系统的可靠和安全运行至关重要。
缺乏可解释性
许多现有的运动预测模型采用数据驱动的方法来学习轨迹分布。尽管这些方法可以通过利用大型数据集实现高水平的准确性,但它们往往会导致交通参与者决策过程缺乏可解释性。这种“黑箱”性质使得人们难以理解或解释模型为何会预测某些行为,而这对于自动驾驶系统的安全性和可信度至关重要。此外,过度依赖纯数据驱动的技术可能导致模型过度拟合特定场景或数据中存在的偏差,从而降低模型在多样化和动态的真实世界环境中的泛化能力和鲁棒性。因此,迫切需要开发不仅能够准确预测运动,还能清晰揭示影响这些预测的潜在因素的方法。
4 训练和验证
4.1数据
除表格之外,笔者注意到作者没有写highD等数据集。
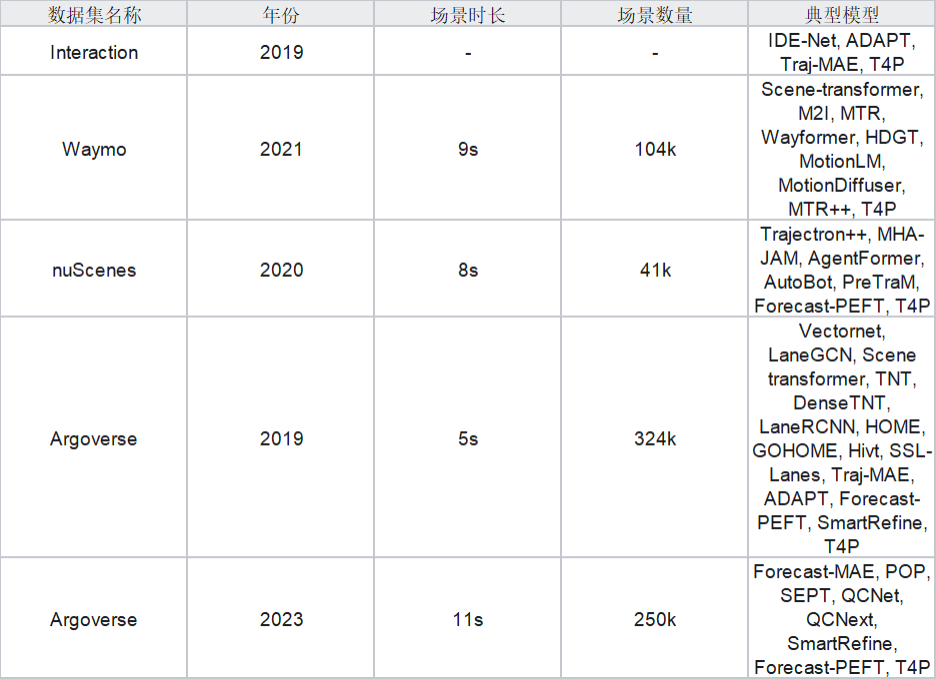
说明:
场景时长 (s):表示每个场景的总时长,包括观察窗口和预测窗口。
场景数量:表示数据集中包含的总场景数。
典型模型:列出在该数据集上应用的代表性模型或方法。
4.2评估指标
为了在自动驾驶运动预测中获得定量结果,标准化的评估设置和常用的评估指标至关重要。这些评估指标可以从以下三个层面进行总结:
4.2.1 几何级评估指标
几何测量是评估预测轨迹与真实轨迹相似度的关键指标,能够有效反映预测的准确性。
1.最小平均位移误差(minADE)
用于衡量所有未来时间步的平均 L2 距离。minADE 用于评估多模态轨迹预测,通过计算最佳预测轨迹与真实轨迹之间的平均 L2 距离来衡量误差。对于每个目标的K条预测轨迹,公式为:
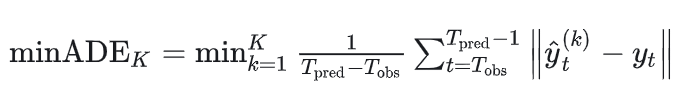

2.最小最终位移误差(minFDE)
FDE 用于衡量所有未来时间步的终点 L2 距离。minFDE 用于评估多模态轨迹预测,通过计算最佳预测轨迹与真实轨迹在最终时间步的误差来衡量。对于每个目标的 条预测轨迹,公式为:
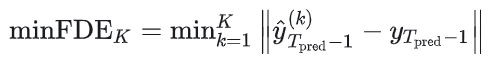

3.漏检率(MR)
指所有预测轨迹的终点误差超过 2.0 米的场景数量。
4.2.2 概率级评估指标
负对数似然(NLL)的不同版本可以用于概率测量,通过比较生成轨迹的分布与真实轨迹的分布来评估不确定性,尤其是对于多模态输出分布。例如,对于拉普拉斯分布的 NLL:
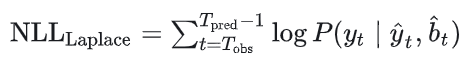

4.2.3 任务级评估指标
任务级评估指标用于评估轨迹预测对下游规划模块的影响。例如,基于规划信息的准确率指标(如 piADE 和 piFDE)可以表示为:
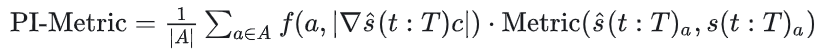

5 模型架构
无论是SL还是SSL,模型结构都离不开Encoder和Decoder
5.1 监督学习架构(SL)

监督学习的发展较早,在一开始,其对map信息和agent信息的利用还是将其转化为栅格数据,再利用CNN等手段来分析其中的时空关系(Rasterized-based Encoder),但是这种方法会损失环境中的拓扑关系。更进一步的研究将map信息和agent信息进行向量化,采用(Graph-based Encoder)提取向量特征,这种方法能够提取到agent之间的交互特征。此外,Attention-based Encoder利用transformer架构来解决多模态预测的问题。此外,也有研究将感知层和预测层直接相连,将感知信息直接编码,提取轨迹信息,用于预测轨迹。
至于解码方面,共有两种方式,分别为Anchor-Conditioned Decoding和Anchor-Free Decoding。nchor-Conditioned Decoding
Anchor-Conditioned Decoding(基于锚点的解码)
基于锚点的解码方法通常将数据集中的先验知识作为网络输入的一部分,通过条件概率生成多模态轨迹。这种方法依赖于预定义的锚点(anchors),最终输出的轨迹会被限制在这些锚点定义的集合内。其有效性高度依赖于锚点的质量和相关性。基于锚点的解码方法进一步细分为以下几种:
Goal-based Decoder(基于目标的解码器):基于目标的解码器假设轨迹的终点包含了大部分不确定性,因此首先预测交通参与者的终点目标,然后基于该目标生成完整的轨迹。终点目标通常是通过对预定义的稀疏锚点进行分类和回归得到的。
Heatmap-based Decoder(基于热图的解码器):基于热图的解码器将轨迹预测的输出格式定义为概率热图,通过全卷积模型生成热图来表示交通参与者未来位置的可能性分布。
Intention-based Decoder(基于意图的解码器): 基于意图的解码器通过手动定义交通参与者的意图(如左转、换道等),并为每种意图学习独立的运动预测器。
Anchor-Free Decoding(无锚点的解码)
与基于锚点的解码方法不同,无锚点的解码方法不依赖于预定义的锚点,而是直接从解码器输出预测轨迹。这种方法避免了锚点带来的空间先验信息限制,但可能导致模型倾向于学习高频模式,而对低频模式的学习不足,从而在长期预测任务中精度下降。为了解决这一问题,提出了一种可学习锚点的解码范式,结合了基于锚点和无锚点方法的优点。
5.2 自监督学习架构(SSL)
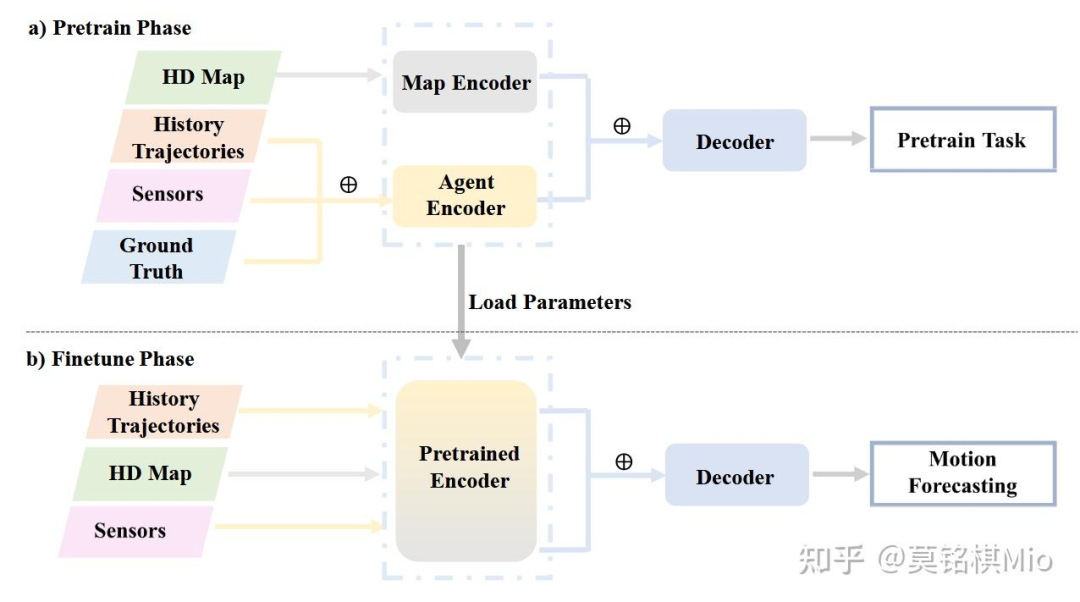
在文章的第5.2节“Self-Supervised Learning-based Architecture”中,作者详细介绍了自监督学习在自动驾驶车辆运动预测中的应用。自监督学习利用大规模未标记数据来学习更全面的特征表示,从而提高模型在下游任务中的泛化能力和鲁棒性。以下是该节内容的总结:
5.2.1 初步探索
VectorNet:首次在自动驾驶运动预测中引入自监督学习,通过图神经网络完成地图信息的图补全任务,为后续自监督方法奠定了基础。
PreTraM:针对轨迹数据有限的问题,提出通过对比学习生成额外的栅格化地图补丁,用于训练鲁棒的地图编码器。同时,采用预训练策略增强地图和轨迹编码器的学习能力。
SSL-Lanes:提出一系列针对单一输入模态(如车道掩蔽)的预训练任务,包括交叉口距离计算、操作分类等,通过复杂特征提取提升模型性能,无需额外数据。
5.2.2 数据增强
Azevedo et al. (2022):开发了一种利用高精地图生成潜在轨迹的方法,通过合成速度和图节点的连通性生成轨迹,以增强有限的运动数据。该方法需要复杂建模,且在处理非标注数据时面临挑战。
Li et al. (2023):提出一种生成伪轨迹的策略,通过预训练阶段生成符合车道结构的合成轨迹,缩小合成数据与真实数据之间的域差距。
Wagner et al. (2023):采用双阶段训练方法,预训练阶段使用基础地图数据学习相似视图的嵌入,微调阶段使用标注的交通参与者历史数据提升运动预测精度。
5.2.3 MAE(Masked AutoEncoder)方法
Traj-MAE:首次提出用于自监督轨迹预测的掩码自编码器,分别对轨迹和地图输入设计独立的掩码-重建任务,探索多种掩码策略(如社交和时间掩码),但未充分强调预训练阶段中交通参与者与道路之间的空间关系。
Forecast-MAE:设计了一种新颖的掩码策略,通过掩码部分交通参与者的过去轨迹、其他参与者的未来轨迹以及随机掩码车道,使模型能够有效捕捉交通参与者的行为模式、道路环境特征及其相互作用。
5.2.4 辅助任务设计
POP:针对观测数据不足导致性能下降的问题,提出一种重建分支,通过掩码和重建头重建部分观测数据的缺失历史部分。
SEPT:整合三种自监督掩码-重建任务,分别针对场景输入中的交通参与者轨迹和道路网络,用于预训练场景编码器,使其能够捕捉轨迹的动力学特性、道路网络的空间结构以及道路与交通参与者之间的相互作用。
5.2.5 语言建模方法
STR:将运动预测和规划的所有组件(包括地图信息、其他道路使用者的过去轨迹、未来状态等)整合到一个序列中,使用因果Transformer(如GPT-2)作为核心,实现模型的可扩展性,并利用语言建模的最新进展。
AMP:采用定制的位置编码处理复杂的时空关系,包括相对空间位置编码、时间位置编码和旋转位置编码(RoPE),在以自我为中心的坐标系中统一输入和输出表示,并以GPT风格进行自回归预测。
MotionLM:包含场景编码器和轨迹解码器,场景编码器处理多模态输入(如道路图元素、交通灯状态、交通参与者及其近期历史特征),轨迹解码器自回归生成多个交通参与者的离散运动标记序列,通过最大似然目标训练,能够在推理时采样多样化的轨迹并聚合为一组代表性的联合模式。
6 结论与展望
文章指出,尽管运动预测领域在模型架构和数据利用方面取得了显著进展,但仍然面临以下挑战:
先验信息融合不足:当前模型对交通信号灯、交通标志等关键信息的利用有限,影响了对复杂交通场景的理解。
模型鲁棒性不足:大多数模型依赖完整观测数据,但在实际场景中,传感器的局限性和遮挡问题可能导致数据缺失,影响预测性能。
评估指标不一致:联合感知-预测模型与传统预测模型之间缺乏统一的评估标准,难以进行公平比较。
自监督学习潜力未充分发挥:自监督学习在运动预测中的应用仍有很大空间,需要探索更多新颖的预训练任务。
针对这些挑战,未来的研究方向包括:
更全面的先验信息融合:将交通信号灯、交通标志等信息纳入模型,提升决策能力。
提升模型鲁棒性:开发能够在不完整数据下稳健运行的模型,处理数据缺失和不确定性。
统一评估协议:开发考虑感知误差的评估标准,实现不同类型模型的公平比较。
探索新的预训练任务:利用自监督学习和扩散模型等新兴技术,提升模型的泛化能力和鲁棒性。
文章强调,尽管技术不断进步,但运动预测领域仍需进一步研究,以推动自动驾驶技术的发展和应用
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









