



点击下方卡片,关注“自动驾驶之心”公众号
GAIA-2
论文标题:GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
论文链接:https://arxiv.org/abs/2503.20523
项目主页:https://wayve.ai/thinking/gaia-2/
星球链接:https://t.zsxq.com/i1P7b

核心创新点:
1. 可控多摄像头一致性的高分辨率视频生成
采用潜在扩散模型(Latent Diffusion Model)架构,支持同时生成5个视角的高分辨率视频(448×960),确保跨摄像头视角的时空一致性(spatiotemporal coherence)。通过时空分解Transformer(Space-Time Factorized Transformer)与相机参数编码,解决了多视图同步生成的难题,满足自动驾驶系统对多传感器输入的需求。
2. 细粒度结构化条件控制机制
引入多模态条件接口,支持对以下元素的精准控制:
车辆动力学(如速度、曲率);
动态代理状态(3D边界框的位置、朝向、类别);
环境元数据(天气、时间、地理区域、车道类型、交通信号);
外部语义嵌入(CLIP文本/图像嵌入、专有驾驶场景嵌入)。
通过自适应层归一化(Adaptive Layer Norm)和交叉注意力(Cross-Attention)实现多条件融合,生成场景的多样性与可控性显著提升。
3. 高效连续潜在空间建模
相比前代模型GAIA-1的离散潜在空间,GAIA-2采用连续潜在空间,结合32×空间压缩率与64通道高语义维度,在压缩效率(总压缩率384×)与重建质量间取得平衡。通过流匹配(Flow Matching)训练框架与双模态时间分布策略(Bimodal Logit-Normal Distribution),优化了潜在状态的预测稳定性与生成质量。
4. 灵活推理模式与编辑能力
支持四种生成模式:
从零生成(From-Scratch Generation);
自回归长时预测(Autoregressive Rollout);
时空修复(Spatial-Temporal Inpainting);
场景语义编辑(Real-Scene Editing)(如修改天气、道路布局)。
通过分类器无关指导(Classifier-Free Guidance)与选择性空间噪声注入,实现复杂场景的精细化控制。
5. 大规模异构数据驱动训练
基于覆盖英、美、德三国的25万小时驾驶数据(5-6摄像头、多车辆平台),涵盖多样地理环境与边缘案例。通过地理隔离验证策略(Geographically Held-Out Validation)与联合概率分布平衡,确保模型泛化能力,生成内容覆盖典型场景与安全关键事件(如紧急制动、危险变道)。
6. 跨模态潜在嵌入集成
支持与外部模型的深度集成,例如:
CLIP嵌入实现零样本语义控制;
专有驾驶场景嵌入编码高抽象场景语义(如超车、路口转向)。
该设计扩展了生成场景的语义连贯性,并为下游规划模块提供兼容接口。
ADS-Edit
论文标题:ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
论文链接:https://arxiv.org/abs/2503.20756
星球链接:https://t.zsxq.com/OtKim
核心创新点:
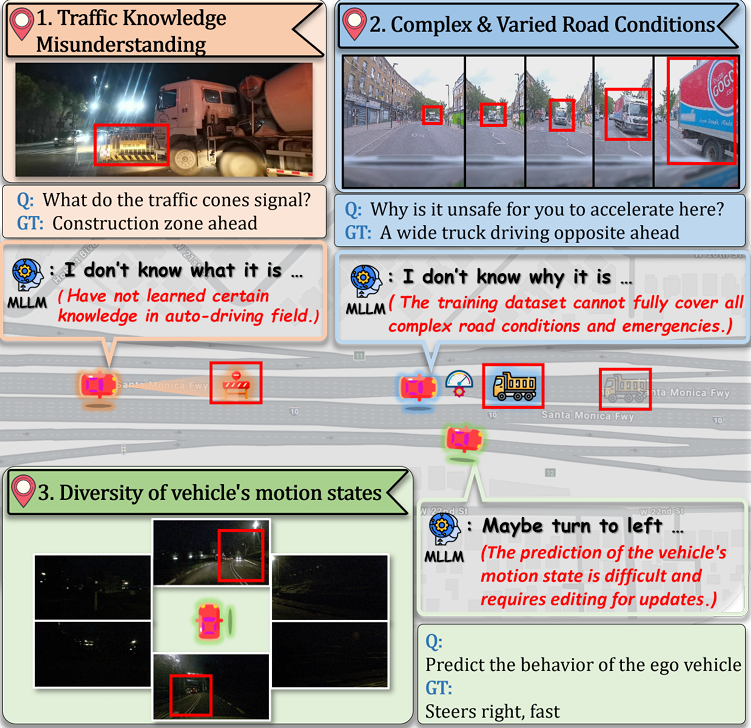
1. 多模态知识编辑框架
首次提出面向自动驾驶系统的结构化知识编辑范式,集成摄像头、激光雷达、雷达等多传感器数据的语义关联与动态修正机制,支持感知-决策闭环中的知识一致性验证。
2. 时空对齐的增量式标注
开发基于时空约束的半自动标注算法(ST-IAA),实现多模态数据在时序维度(0.1s级同步精度)和空间维度(厘米级配准误差)的精准对齐,支持动态场景的增量式知识更新。
3. 长尾场景覆盖增强
构建包含21类罕见场景(极端天气、异形障碍物等)的多模态知识图谱,通过对抗生成与物理仿真融合技术,将边缘案例的覆盖率提升至89.7%(基准数据集对比)。
4. 可解释性编辑评估体系
提出知识编辑质量的三维评估指标(KE3:一致性、完备性、可迁移性),集成基于因果推理的错误溯源模块,使模型修正过程的可解释性提升42.6%(消融实验数据)。
SaViD
论文标题:SaViD: Spectravista Aesthetic Vision Integration for Robust and Discerning 3D Object Detection in Challenging Environments
论文链接:https://arxiv.org/abs/2503.20614
论文代码:https://github.com/sanjay-810/SAVID
星球链接:https://t.zsxq.com/2J4YF
核心创新点:
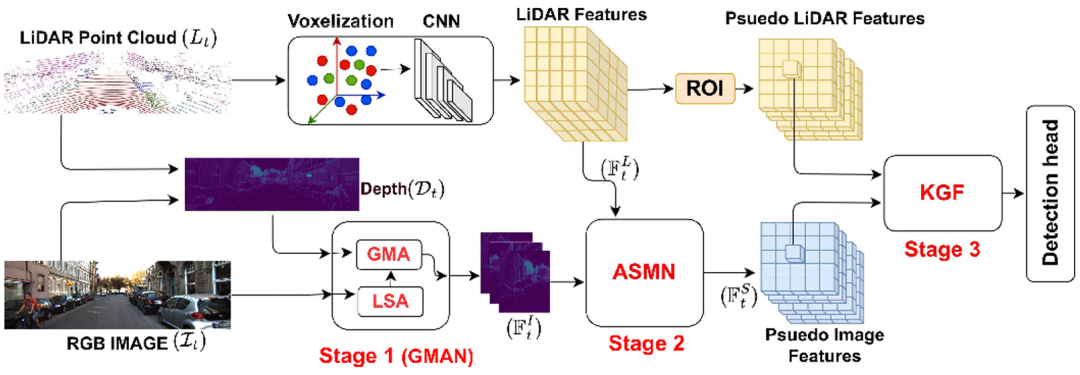
1. GMAN(全局记忆注意力网络)
提出结合局部-全局注意力的视觉Transformer架构,首次将LiDAR生成的深度图(Dt)作为全局查询(Global Query),通过频域FFT-iFFT层增强图像特征提取。其Global Memory Attention (GMA)模块通过跨模态注意力机制(LiDAR点云与图像特征交互)实现远距离场景的全局上下文建模,并引入LSTM进行时序特征累积。
2. ASMN(注意力稀疏记忆网络)
设计单阶段稀疏融合机制,通过稀疏注意力(Sparse Attention)与LSTM耦合,解决LiDAR体素特征(FLt)与图像特征(FIt)的跨模态对齐问题。首次将LiDAR体素特征作为全局查询,与图像特征的键值对进行动态关联,生成跨模态对应图(Correspondence Map),提升稀疏点云与高分辨率图像的融合鲁棒性。
3. KGF(KNN连通图融合)
提出无参数的基于KNN的图融合技术,通过余弦相似度计算LiDAR伪点云(FLt)与图像特征(FSt)的局部邻域关联,采用通道加权策略(Channel-weighted Sum)实现多模态特征的空间对齐。该方法无需可学习参数,通过几何约束增强远距离目标的定位精度。
Reason-RFT
论文标题:Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning
论文链接:https://arxiv.org/abs/2503.20752
星球链接:https://t.zsxq.com/Svye4
核心创新点:
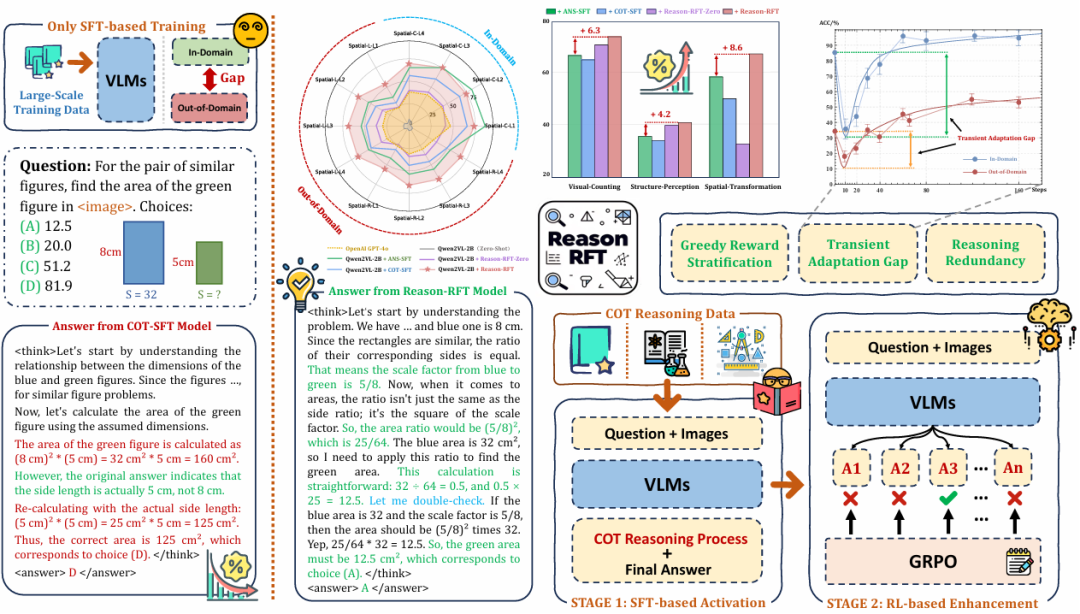
1. 两阶段强化微调框架
SFT + GRPO协同优化 :
首创性结合监督微调(Supervised Fine-Tuning, SFT)与组相对策略优化(Group Relative Policy Optimization, GRPO),形成两阶段训练范式。阶段1(SFT激活推理潜力) :通过高质量领域特定数据集(含Chain-of-Thought推理链)激活模型基础推理能力。
阶段2(GRPO强化推理极限) :引入GRPO算法,通过动态奖励机制(格式奖励+准确性奖励)推动模型突破推理边界,增强跨任务泛化性。
2. 多维度奖励机制设计
混合奖励函数 :
格式奖励(Format Reward) :强制模型生成结构化推理过程(如
<summary>和<caption>标记),确保逻辑可解释性。准确性奖励(Accuracy Reward) :结合精确匹配与部分匹配奖励(Partial Matching),动态平衡推理严谨性与灵活性。
部分匹配机制 :允许对部分正确步骤赋权,缓解传统强化学习对完全正确路径的过度依赖。
3. 领域自适应数据集构建
跨模态任务覆盖 :重构涵盖视觉计数(Visual Counting)、结构感知(Structure Perception)、空间变换(Spatial Transformation)的标准化数据集(60K训练集+6K测试集)。
严格数据筛选 :通过去遮挡、冗余动作消除、多步位移合并等策略,确保数据唯一性与解空间清晰性。
4. 性能与效率突破
跨域泛化优势 :在OOD(Out-of-Domain)场景中表现稳定,显著超越传统SFT及纯RL方法(如CoT-SFT)。
数据效率 :仅需20%训练数据即可达到SFT基线95%性能,支持少样本学习场景。
多任务统一性 :在几何理解、空间推理等任务中实现统一建模,降低领域迁移成本。
最后欢迎大家加入知识星球,硬核资料在星球置顶链接,加入即可获取:
行业招聘信息&独家内推;
自驾学习视频&资料;
前沿技术每日更新;




















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









