



作者 | 迪西 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/30308476969
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
本文只做学术分享,如有侵权,联系删文

研究背景
研究问题:这篇文章要解决的问题是如何利用强化学习(RL)来提升多模态大型语言模型(MLLMs)的推理能力。尽管直接使用RL训练难以激活复杂的推理能力,如提问和反思,但本文提出了一种新的方法来解决这个问题。
研究难点:该问题的研究难点包括:缺乏大规模、高质量的多模态推理数据,以及直接RL训练在优化复杂推理过程时面临的挑战。
相关工作:该问题的研究相关工作有:OpenAI O1通过复杂的Chain-of-Thought(CoT)训练展示了强大的推理能力;其他研究尝试手动构建包含逐步推理过程的监督微调(SFT)数据集,但这些方法生成的“伪CoT”推理缺乏人类思维的自然认知过程。
研究方法
这篇论文提出了Vision-R1,一种结合冷启动初始化和RL训练的多模态推理MLLM。具体来说,
冷启动初始化:首先,利用现有的MLLM和DeepSeek-R1通过模态桥接和数据过滤构建一个无人工注释的高质量多模态CoT数据集。具体步骤如下:
使用MLLM生成“伪CoT”推理文本,明确包含视觉描述和结构化步骤级推理过程。
将富化的推理文本反馈到MLLM中,获得包含必要视觉信息的描述。
将文本描述传递给纯文本推理LLM DeepSeek-R1,提取高质量的CoT推理。
通过基于规则的数据过滤,最终获得一个包含200K多模态人类样复杂CoT推理样本的数据集,作为Vision-R1的冷启动初始化数据。
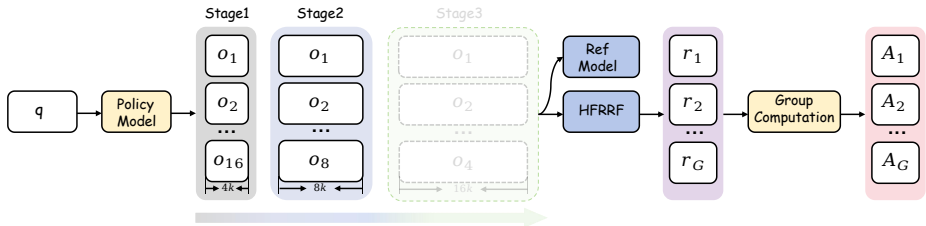
渐进式思维抑制训练(PTST):为了缓解冷启动初始化后过度思考的问题,提出了PTST策略,并结合Group Relative Policy Optimization(GRPO)和硬格式结果奖励函数来逐步精炼模型的推理能力。具体步骤如下:
在早期训练阶段,通过PTST压缩模型的推理长度,引导其进行正确的推理。
随着训练的进行,逐步放宽这些约束,使Vision-R1能够自动学习使用更长的CoT来解决日益复杂的问题。
公式解释:
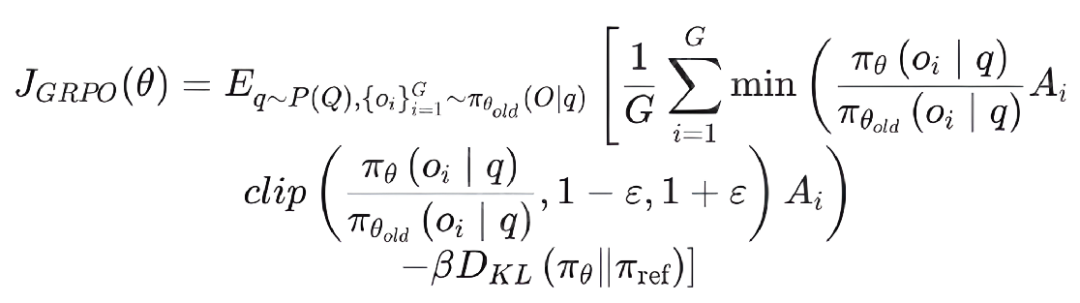
其中,Ai表示第i个样本的训练阶段优势估计,πθold表示具有输出长度约束的策略模型,ε和β分别是PPO剪辑超参数和Kullback-Leibler(KL)惩罚系数。
实验设计
数据集和基准测试:为了获得冷启动数据集,使用了多模态视觉问答(VQA)数据集LLaVA-CoT(100K)和Mulberry数据集(260K),生成Vision-R1-cold(200K)。在GRPO过程中,混合了We-Math、MathVision、Polymath、SceMQA和Geometry3K等数学数据集,总共约10K条数据。评估推理能力的基准测试包括MM-Math、MathVista和MathVerse等多个多模态数学基准测试。
实现细节:使用128个NVIDIA H800 80G GPU部署开源MLLM Qwen-2.5-VL-72B和推理LLM DeepSeek-R1,处理VQA数据集约需2天。Vision-R1-7B的冷启动初始化采用Qwen-2.5-VL-7B-Instruct,在32个NVIDIA H800 80G GPU上进行2个epoch的监督微调,约需10小时。随后在64个NVIDIA H800 80G GPU上进行GRPO训练,采用两阶段的PTST策略。
结果与分析
数学推理能力:Vision-R1-7B在多个数学推理基准测试中表现出色,甚至在某些任务上超过了参数超过其10倍的现有最先进模型。例如,在MathVista基准测试中,Vision-R1-7B取得了73.5%的准确率,仅比领先的推理模型OpenAI O1低0.4%。
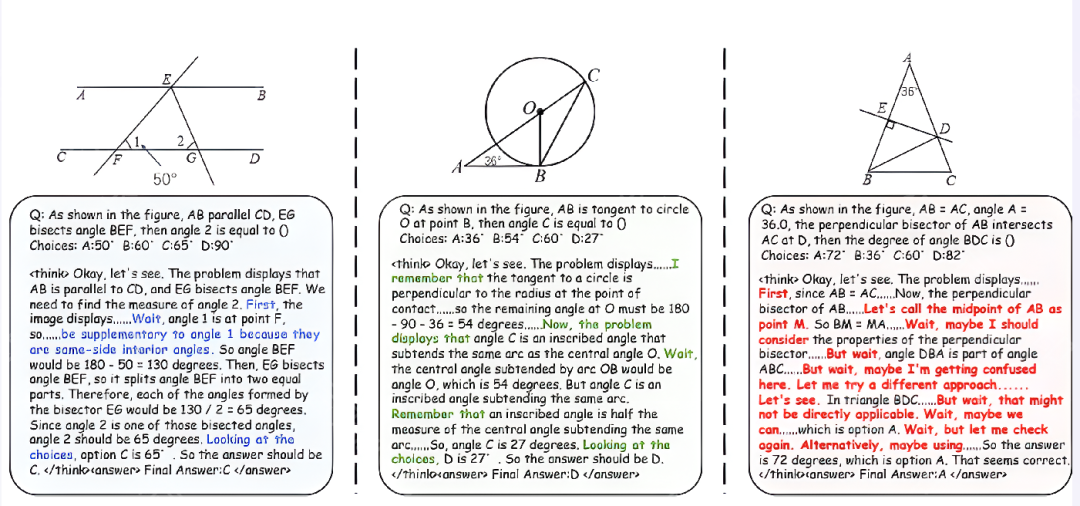
冷启动数据集质量:Vision-R1-cold数据集包含更高比例的人类样认知过程,如提问、反思和检查。与之前的Mulberry和LLaVA-CoT数据集相比,Vision-R1-cold数据集在这些指标上表现更好。

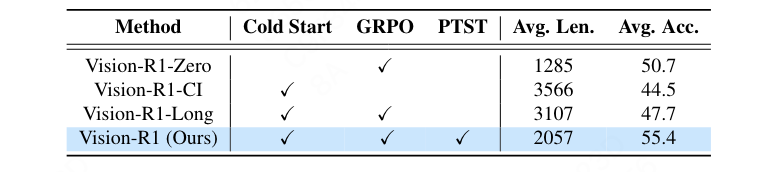
消融研究:比较了不同的RL训练策略,结果表明直接应用RL训练的效果不佳,而Vision-R1在平衡CoT复杂性和准确性方面表现出色。
总体结论
本文探讨了如何利用RL训练来激励MLLMs的推理能力,并提出了Vision-R1。通过结合冷启动初始化和RL训练,Vision-R1实现了强大的数学推理能力,达到了与现有最先进的MLLMs相当的性能。本文的贡献包括首次探索将RL应用于MLLMs以提高推理能力,构建了一个高质量的多模态CoT数据集,并提出了一种有效的PTST策略来解决冷启动初始化后的过度思考问题。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









