



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享阿里&西交最新的在线高精地图Benchmark—MapDR!整合交通规则,让自动驾驶真正”在线化“!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Xinyuan Chang等
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
遵守交通规则行驶是实现自动驾驶系统的必要条件,车道级交通规则通常包含在高精地图中,为自动驾驶系统提供了准确、可靠的规则指导。受限于高精地图的更新频率低、更新成本高的局限,当前自动驾驶系统朝向 “在线感知建图” 的方向发展。而目前的在线建图方法主要关注于车道线、道路拓扑等道路结构的感知,忽视了对于包含更多语义信息的交通规则的理解,这一局限使自动驾驶系统仍然需要依赖离线地图获取交通规则,限制了自动驾驶系统的“在线化”趋势。
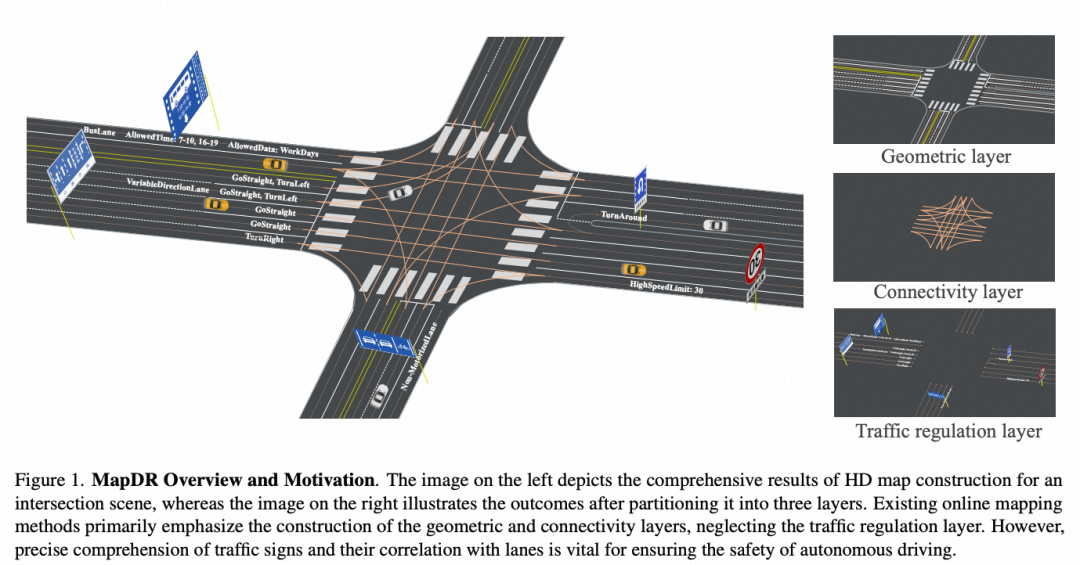
交通标牌是道路上的“视觉语言”,在指示交通规则中发挥了关键作用。由人类驾驶过程的启发,从交通标志中理解交通规则需要完成两个任务,首先理解交通标志牌中指示的车道级交通规则内容,同时要明确规则作用于具体哪一条车道(关联到具体的车道中心线)。同时完成上述两个任务,才能为自动驾驶系统提供准确的车道级交通规则作为指导。现有的相关工作往往关注于二者其一,缺乏对此项任务的全面研究。
为了填补当前研究的空白,本文组织了 MapDR 数据集,包含了超过 10,000 个真实驾驶场景以及18,000 条结构化车道级驾驶规则,并且提出了 Integrating traffic regulations into online HD maps 任务以及评测指标。同时,本文提出了一个模块化方法 VLE-MEE 和一个端到端方法RuleVLM,为此项任务提供了有效的 Baseline。数据集以及方法细节请见下文~

论文链接:https://arxiv.org/abs/2410.23780v2
项目主页:https://xuanmaixue.github.io/Driving-by-the-Rules.github.io/
Integrating traffic regulations into online HD maps
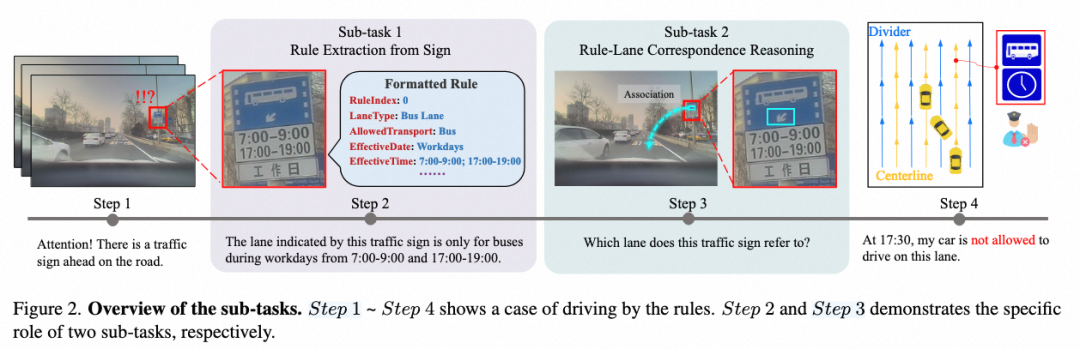
本文所提出任务关注于将交通标志中的车道级交通规则整合至在线构建的高精地图中,需要完成两个子任务:
从交通标志中抽取车道级交通规则
建立交通规则与车道中心线之间的关联关系
如下图所示,本文将车道级交通规则定义为多个 key : value 构成的结构化表达,以便于整合至自动驾驶系统中服务于规控等下游步骤。现实场景中一个标志牌中可能包含多条车道级交通规则,同时每条交通规则也可能与多条车道中心线相关联,这也是解决此任务中的难点。
Dataset & Benchmark
MapDR Dataset

MapDR 数据均高德地图的真实采集数据,关注于来自于北京、上海、广州三座城市的常见交通标志牌以及道路信息。数据集包含了超过 10,000 个行车场景,其中超过 18,000 条驾驶规则。

其中每个场景(一个 Clip)包含:
Raw Data
30+ 帧连续前景图像
关注交通标志的位姿(每个场景仅关注于一个标牌)
以标牌为中心 100m * 100m 范围内的矢量化地图(包含矢量线型)
相机内参以及每一帧对应的相机位姿
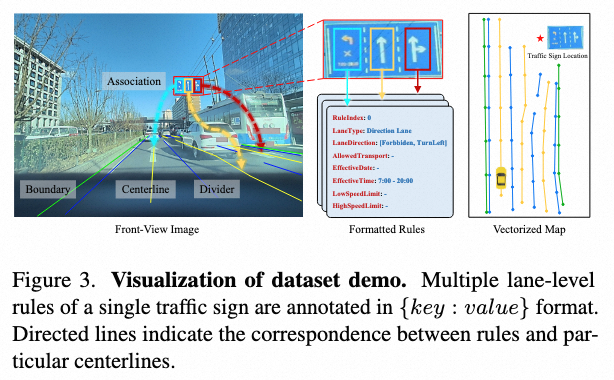
Annotation
标牌中包含的若干条车道级交通规则以及对应的车道中心线
每条交通规则对应的标牌内区域(以位姿表示)
数据表示如下图所示:


Evaluation Metric & Benchmark
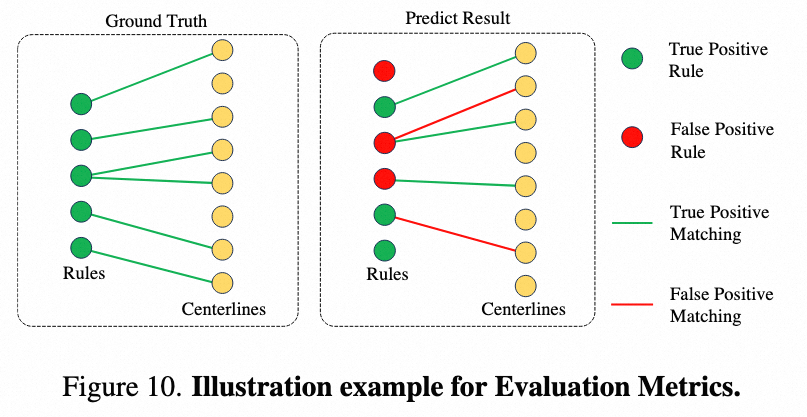
总体任务可以视为一个二分图匹配任务,如上图所示。其中抽取车道级交通规则视作对于图中 Rule Node 的预测,Rule 和 Centerline 之间的关联关系可以视作图中 Edge 的预测。评测时两个子任务分别关注于 Rule Node 和 Edge 的 Precision 和 Recall,总体任务关注于最小子图(由一个Rule Node、一个 Centerline Node 和 一条 Edge 组成)的 Precision 和 Recall
示例如下(R.E. 指规则抽取,C.R.指关联关系推理):
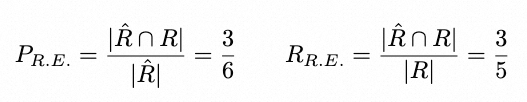
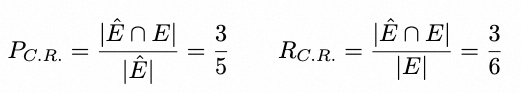
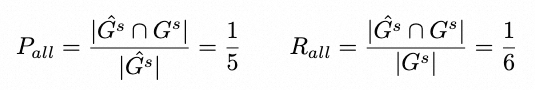
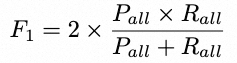
最终方法的评价指标以 F1 Score 为标准
Approach
Modular Approach
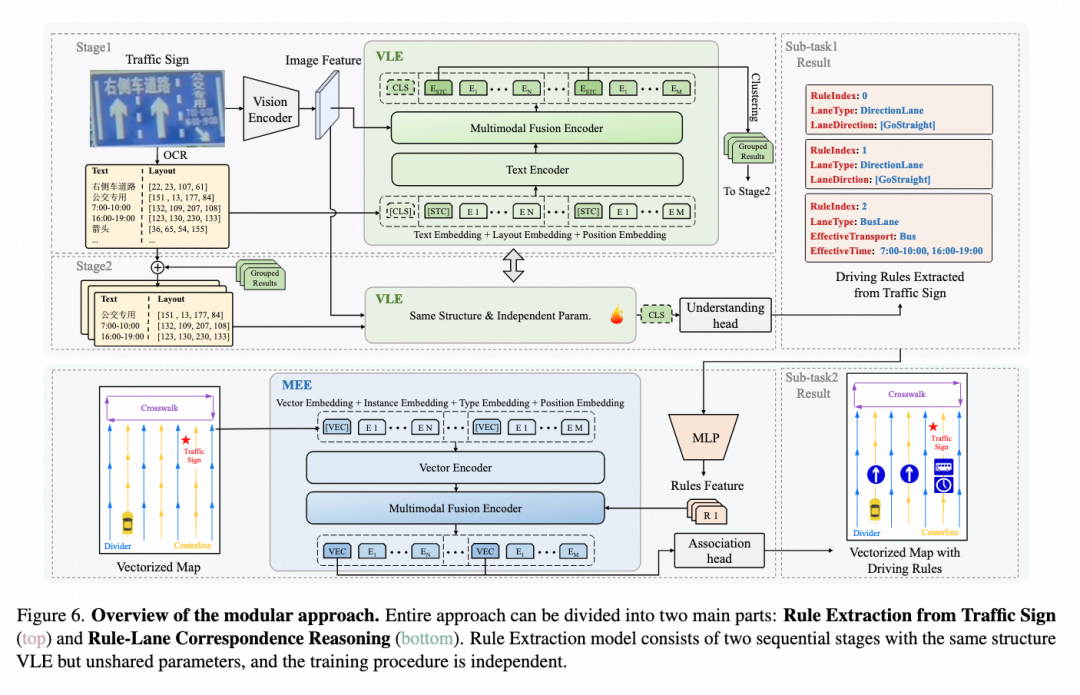
模块化方法由三个级联模块构成:
Grouping:融合标牌图像信息和 OCR 信息完成标牌上元素的车道级区域分组
Understanding:依次融合单个分组的 OCR 和标牌图像信息,使用融合后的信息进行分类以预测交通规则中每个 key 对应的 value
Association:对矢量地图进行特征编码并且与交通规则特征进行信息融合,通过二分类完成判定每条车道中心线是否与交通规则关联
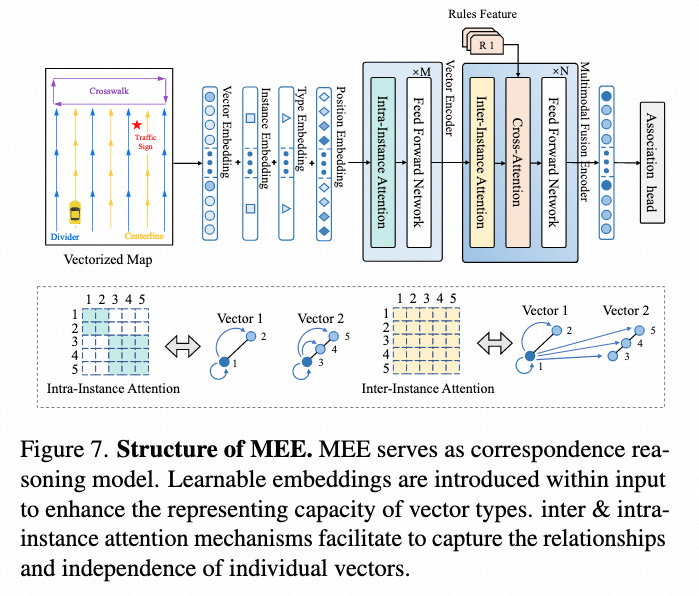
其中 MEE 模型专门用于对矢量地图进行特征编码,将每个矢量点进行 tokenize,使用 learnable query 配合 Intra & Inter Instance Attention 进行矢量特征的聚合,融合后每个 query 对应一条矢量的特征信息。通过 CrossAttention 进行矢量特征和交通规则特征的融合,使用融合后的 feature token 进行分类以判定中心线与规则的关联关系。
End-to-End Approach
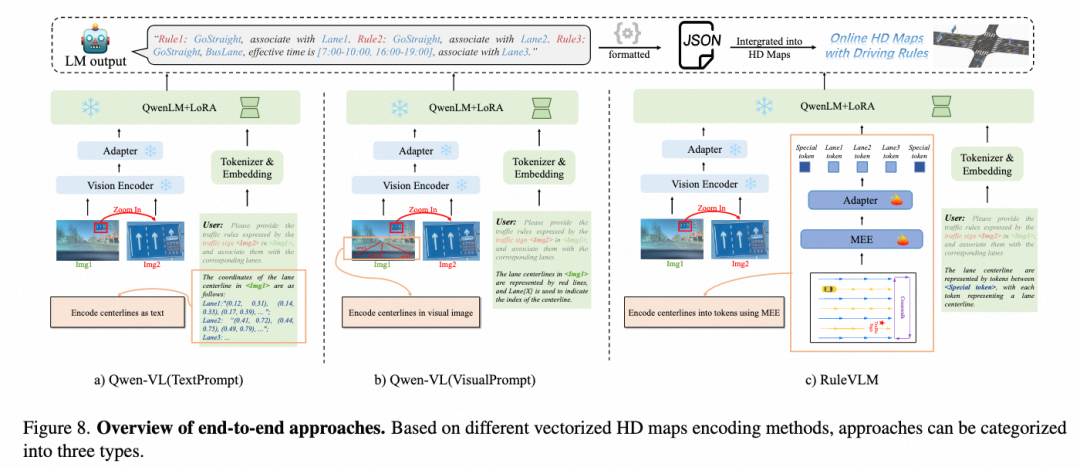
端到端方法在多模态大模型基础上进行了探索,以 Qwen-VL-Chat 7B 作为基础模型,如图所示分别以不同方式进行了LoRA SFT,令模型生成结构化文本形式的交通规则:
TextPrompt:输入完整前景图像 + 标牌图像,将矢量点坐标以文本形式进行输入。
VisualPrompt:输入包含矢量投影的完整前景图像 + 标牌图像
RuleVLM(best):输入完整前景图像 + 标牌图像,使用 MEE 对矢量进行特征抽取并且对齐至 LLM
Experiment
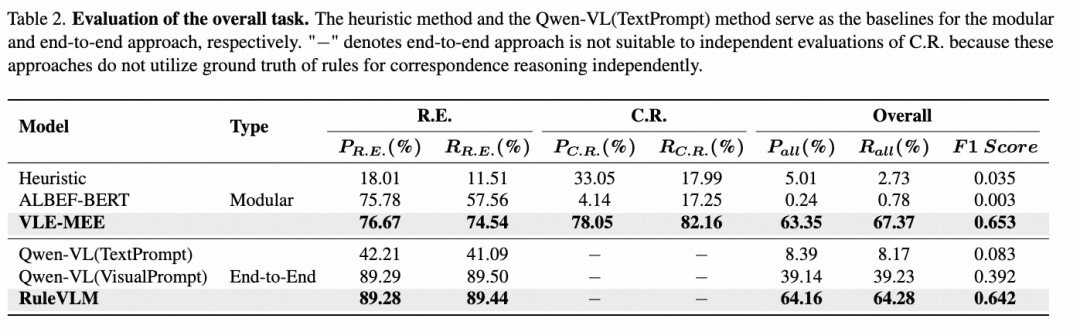
在 MapDR 数据集上进行的实验结果如上表所示,启发式方法(OCR 判定 + 最近车道线匹配)难以理解复杂的交通标志牌内容,同时也无法完成复杂场景下的车道-规则关联。VLE-MEE 和 RuleVLM 分别为模块化方法和端到端方法提供了有效的 Baseline.
结论
综上所述,本文的贡献如下:
首次提出了 Integrating traffic regulations into online HD maps 任务,以及用于基准测试的 MapDR 数据集和评测指标。
MapDR 包含 10,000+ clip,涵盖了不同的交通状况,并包括超过 18,000 条人工标注的车道级交通规则。所有数据都是真实采集,并且经过了细致的校验,助力于相关任务的研究。
提出了模块化(VLE-MEE)和端到端(RuleVLM)两种建模方法,为目标任务并和未来的研究提供有效的 Baseline 方法。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1919
1919



 到【灌水乐园】发言
到【灌水乐园】发言








