



作者 | 薄紫彤 编辑 | 自动驾驶之心
原文链接:https://www.zhihu.com/question/635887335/answer/65505352072
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
在人工智能领域,扩散模型(Diffusion Models,简称DMs)凭借其强大的生成能力,在图像、文本以及轨迹规划等任务中展现了巨大的潜力。然而,当扩散模型应用于决策规划领域时,其低效的迭代采样成为了一个主要瓶颈。许多现有方法,如 Diffuser 和 Decision Diffuser (DD),在生成高质量轨迹的同时,由于复杂的建模过程,其决策频率往往低于 1Hz。这种性能远不能满足机器人控制、游戏 AI 等实际场景对实时响应的要求。
为解决上述问题,DiffuserLite 应运而生。它通过引入一种创新性的 渐进式精细规划(Progressive Refinement Planning, PRP) 方法,在减少冗余信息建模的同时,实现了更高效的轨迹生成。令人印象深刻的是,DiffuserLite 的决策频率达到了 122Hz,比主流框架快 112 倍以上,并在多个基准任务中实现了 State-of-the-Art(SOTA) 性能。本文将深入讲解 DiffuserLite 的核心原理与技术亮点,剖析其在实际应用中的潜力,并探讨这一框架可能带来的广泛影响。
问题
在决策规划领域,DiffuserLite 所面临的任务可以描述为一个基于离线强化学习(Offline Reinforcement Learning)的优化问题,其核心目标是生成一条满足目标属性的轨迹。
系统的状态由离散时间动力学方程控制,公式如下:
= f(,)
其中:
表示系统在时间 t 的状态。
为在时间 t 的动作。
表示系统的动态模型。
轨迹 x 可以表示为状态序列或状态-动作对序列,其中T是规划的时间范围。
Diffusion Planning 的目标是找到一条最符合目标 的轨迹:
其中:
d 是一个度量轨迹属性与目标属性之间距离的函数。
C是一个评价器(Critic)。
在离线强化学习的背景下,轨迹的属性通常被定义为其累积奖励:
核心在于从离线数据中生成符合目标属性的轨迹,并从中提取执行动作
扩散模型
扩散模型被引入来解决轨迹生成问题。其通过对轨迹分布的建模,能够生成满足目标条件的长时序轨迹。与传统的逐步生成方法不同,扩散规划直接生成完整轨迹,避免了步进式方法中常见的累积误差。现有扩散规划方法的一个主要瓶颈在于高复杂度的采样过程,这需要多次前向传播和复杂的去噪处理,导致决策频率极低。

DiffuserLite
DiffuserLite 是一种高效轻量级的扩散规划框架,旨在解决现有扩散规划方法中因冗余信息建模而导致的低效率问题。它通过引入 渐进式精细规划(Progressive Refinement Planning, PRP) 方法,减少了不必要的计算。此外,DiffuserLite 使用 DiT(Transformer 变体) 替代传统的 UNet 模型。DiffuserLite 的规划过程分为以下几个阶段:
初始粗略规划:在较大的时间间隔内多次生成关键状态点,忽略中间冗余细节。
评价:使用评价器(Critic)选择最优轨迹。
逐步精细化:在每一层细化关键状态点之间的轨迹(执行多次),利用评价器选择最有轨迹。
快速执行:通过简化的模型架构和条件采样技术,快速生成动作决策。
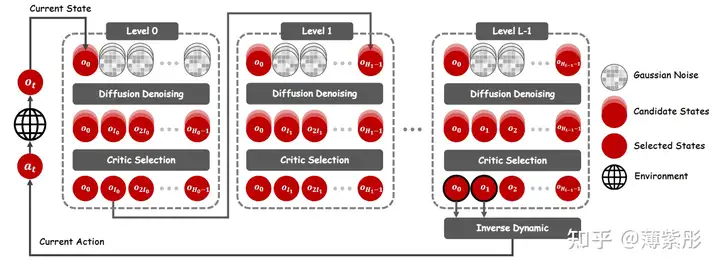
渐进式精细
规划渐进式精细规划(PRP) 是 DiffuserLite 的核心创新之一,用于在生成轨迹时逐步减少冗余建模,提升效率和准确性。PRP 的核心理念是将轨迹生成过程分解为多个逐层优化的阶段,从最初的粗略规划逐步细化,直到生成精确的完整轨迹。在扩散规划中,完整轨迹的生成通常涉及大量冗余信息,尤其是远端状态的细节对于当前决策的影响微乎其微。例如,在长时间跨度的轨迹规划中,远端的状态可能由于环境噪声或动态变化而无法准确到达,因此建模这些细节不仅无益,反而增加了计算负担。冗余信息导致模型需要处理更高维度、更复杂的概率分布,这显著降低了推理速度。PRP
粗略规划:
初始阶段仅生成关键点(Key Points),间隔较大的状态点被视为轨迹的主要参考,而中间状态被忽略。逐层精细化:
从关键点轨迹出发,逐层填补两点之间的细节,逐步将轨迹分辨率提高到所需的精度。示例:优化终结:
最后一层完成全轨迹的生成,生成的轨迹既包括整体的长远性,又有足够的局部细节。
例如:对于规划范围为 128 的轨迹,第一层只生成 [0,32,64,96,128] 这几个点。第二层生成[0, 8, 16, 24, 32],第三层生成[0,1,2,3,4,5,6,7,8]。相比于传统的one-shot方法,能够快速生成出理想的轨迹。

训练

将完整轨迹按层次划分为子轨迹,每层生成的轨迹采用扩散模型拟合其概率分布,优化目标为最小化噪声预测误差。为指导模型生成目标轨迹,DiffuserLite 使用了无分类器指导(CFG)。
Critic设计
Critic 是 DiffuserLite 中的关键部分。Critic的两个核心作用:
提供生成条件:在扩散模型训练过程中,Critic 评估轨迹的属性 C(x),并作为条件输入指导模型生成目标轨迹。
选择最优轨迹:在推理阶段,Critic 用于从候选轨迹中选择最优轨迹。
在稀疏奖励任务中,直接使用累积奖励可能不够有效,因此可以加入最终状态的值函数 :
在特定任务(如机器人控制或行为定制)中,可以将其设计为目标任务的特定指标,例如轨迹平滑性、目标对齐度、或者状态变化的能量消耗。
实验
1.实验目的
实验的主要目的是验证 DiffuserLite 在多种任务中的性能,包括:
效率:决策频率是否显著提升。
准确性:生成轨迹是否符合任务目标。
任务适应性:是否能够处理长时序、稀疏奖励等复杂任务。
2. 实验设置
数据集与环境
DiffuserLite 在以下标准基准任务中进行评估:
Gym-MuJoCo:机器人运动控制任务。
任务包括 HalfCheetah、Walker2D 等,主要关注连续控制性能。
FrankaKitchen:复杂任务完成环境。
包含多个子任务组合,如打开微波炉、关门等,考验轨迹规划能力。
Antmaze:长时序导航任务。
需要在稀疏奖励场景中生成可行的轨迹,特别测试远端轨迹规划能力。
评估指标
决策频率(Hz):每秒生成的决策次数。
任务成功率:轨迹是否成功达到目标状态。
奖励累计值:生成轨迹的累计奖励。
3. 实验结果
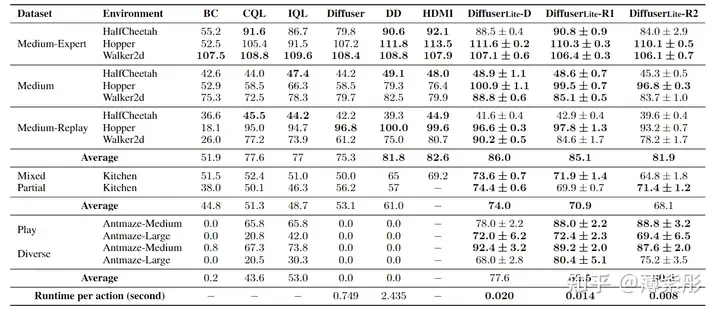
性能比较
DiffuserLite 与主流方法(如 Diffuser、Decision Diffuser)进行了全面对比。结果如下:
决策频率:
DiffuserLite 的频率达到了 122 Hz,显著高于 Diffuser(约 1 Hz)和 Decision Diffuser(约 0.8 Hz)。
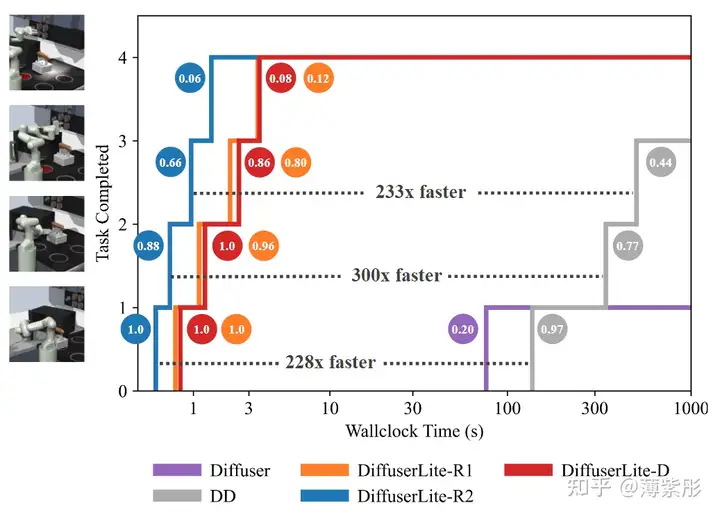
任务成功率:
在 FrankaKitchen 任务中,DiffuserLite 的成功率达到了 85%,比基准方法高出约 10%。
累积奖励:
在 Gym-MuJoCo 任务中,DiffuserLite 的累计奖励接近理论最优值,展现了优异的控制性能。
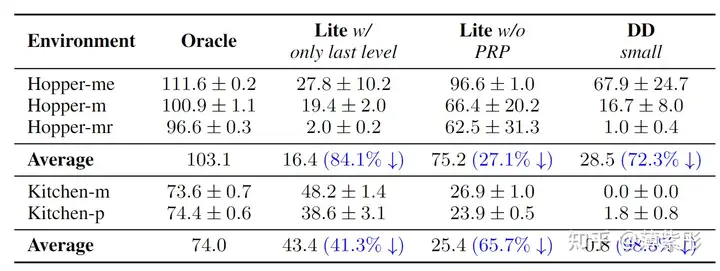
消融实验
为了验证各组件的贡献,进行了以下消融实验:
无 PRP(渐进式精细规划):
不使用 PRP,直接生成完整轨迹。结果显示效率和准确性显著下降。
替换模型架构:
用传统的 UNet 替换 DiT(Diffusion Transformer),推理速度降低约 30%。
移除 Critic 指导:
不使用 Critic 提供的轨迹属性条件,任务成功率降低了 15%。
总结
DiffuserLite 在扩散规划领域实现了一项重要突破,通过引入 渐进式精细规划(PRP) 和灵活的 Critic 和属性设计,显著提升了轨迹生成的效率和适应性。实验结果表明:
高效性:DiffuserLite 的决策频率达到了 122Hz,是现有方法的百倍以上,能够满足实时任务需求。
准确性:在 Gym-MuJoCo、FrankaKitchen、Antmaze 等复杂任务中,DiffuserLite 均展现了优异的任务成功率和轨迹规划能力。
适应性:通过 PRP 和 Critic 的结合,DiffuserLite 能够有效处理长时序和稀疏奖励任务,展现了极强的任务扩展性。
整体来看,DiffuserLite 解决了扩散规划的实时性问题。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









