



作者 | CalebDu 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/693279132
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
毕业一年了,一直在从事大模型推理相关的工作。工作中最常拿来比较的LLM推理框架就是vLLM,最近抽出时间详细的研究了一下vLLM的架构,希望能对vLLM有一个更详细和全面的认识。
1. 架构总览
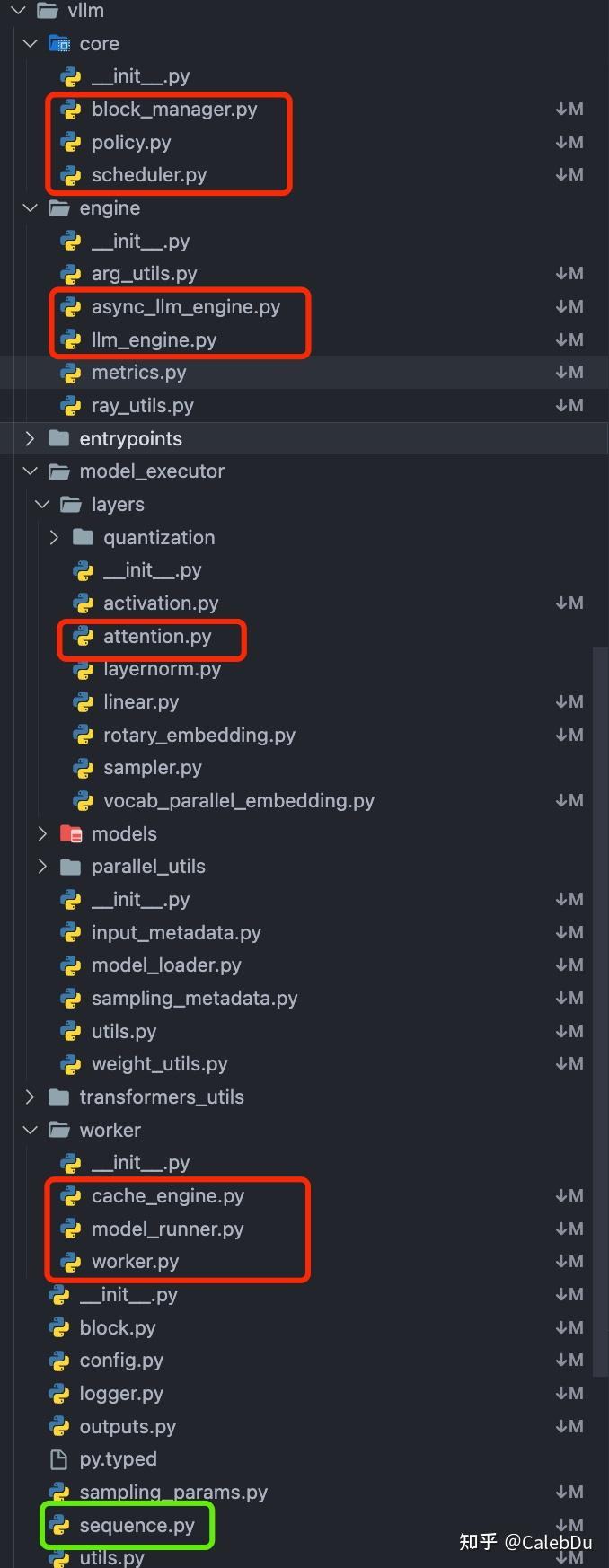
如图标出的文件是vLLM python侧的工程目录中核心的组件,按照层次间的依赖关系,可以大致拆解为如下结构:
LLM 类为顶层用户应用, LLM 类控制 LLM Engine类 负责总管推理全流程,LLM Engine中包含 Scheduler 类和 Worker类。Scheduler 负责调度不同request,保证vLLM中的Cache Block资源足够现有的请求完成执行,否则对现有的request进行抢占。Scheduler 类 控制 Block Manager 来管理 Phyical Token Block。Worker 负责模型载入、模型执行,对于分布式推理,则通过创建多个worker在执行完整模型的一部分(Tensor Parallel)。其中Cache Engine 管理CPU/GPU上完整的KV Cache Tensor,执行Scheduler 调度的request的block数据搬运。Model Runner 拥有实际执行的Model 实例,并负责进行数据的pre-process/ post-process 及sampling。

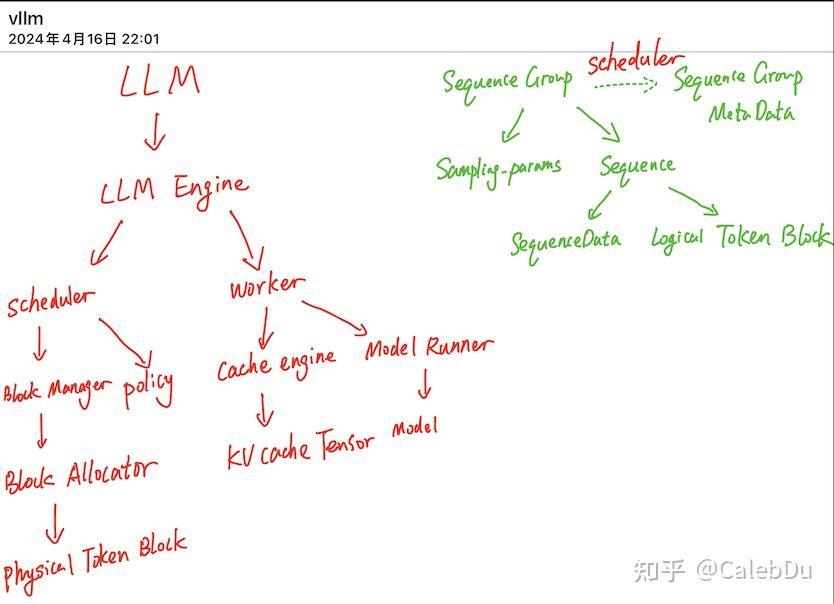
【更新】vLLM 代码进行了重构,和我之前看的code base有一些差异
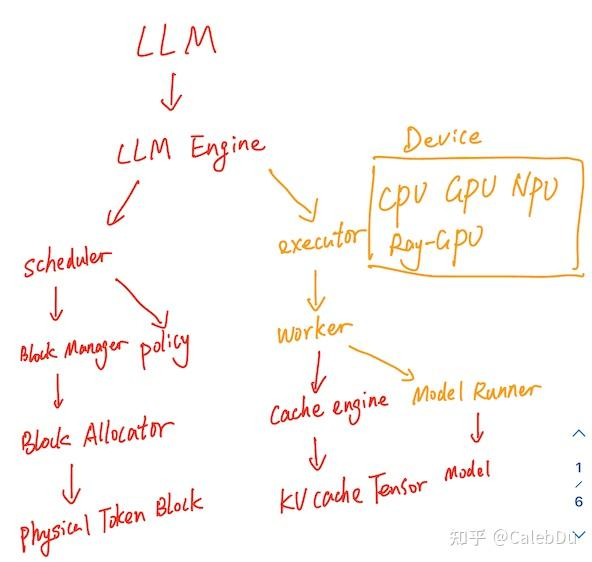
整体的架构与之前的改动不大,在Worker之上新增了Executor类的抽象,用于管理不同后端的device如 CPU、GPU、NPU、分布式GPU后端,根据不同的device 派生了特定的Executor、Worker、Model Runner。
并新增了Speculative Decoding、FP8、lora、CPU Page Attention kernel、不同的后端的Attention、prefill decoding混合推理等新特性的支持。
2. Scheduler
Scheduler 的调度行为发生在每一个LLM Engine执行step 推理的最初。负责准备这一次step执行推理的SentenceGroup。Scheduler 负责管理3个队列 running waiting swapped,waitting 队伍内的元素为首次prompt phase或preempt recompute,swapped队伍中的元素从running中被抢占换出的,都处于decode phase。每当LLM Engine 添加一个新的request,Scheduler会把新的request创建的SentenceGroup 入队waiting。
Scheduler 每一次调度保证这一次step的数据全部是prompt(prefill) phase或全部是decode(auto-regressive) phase。核心的函数为_scheduler():函数中存在3个临时队列 scheduled、new running、 preempt
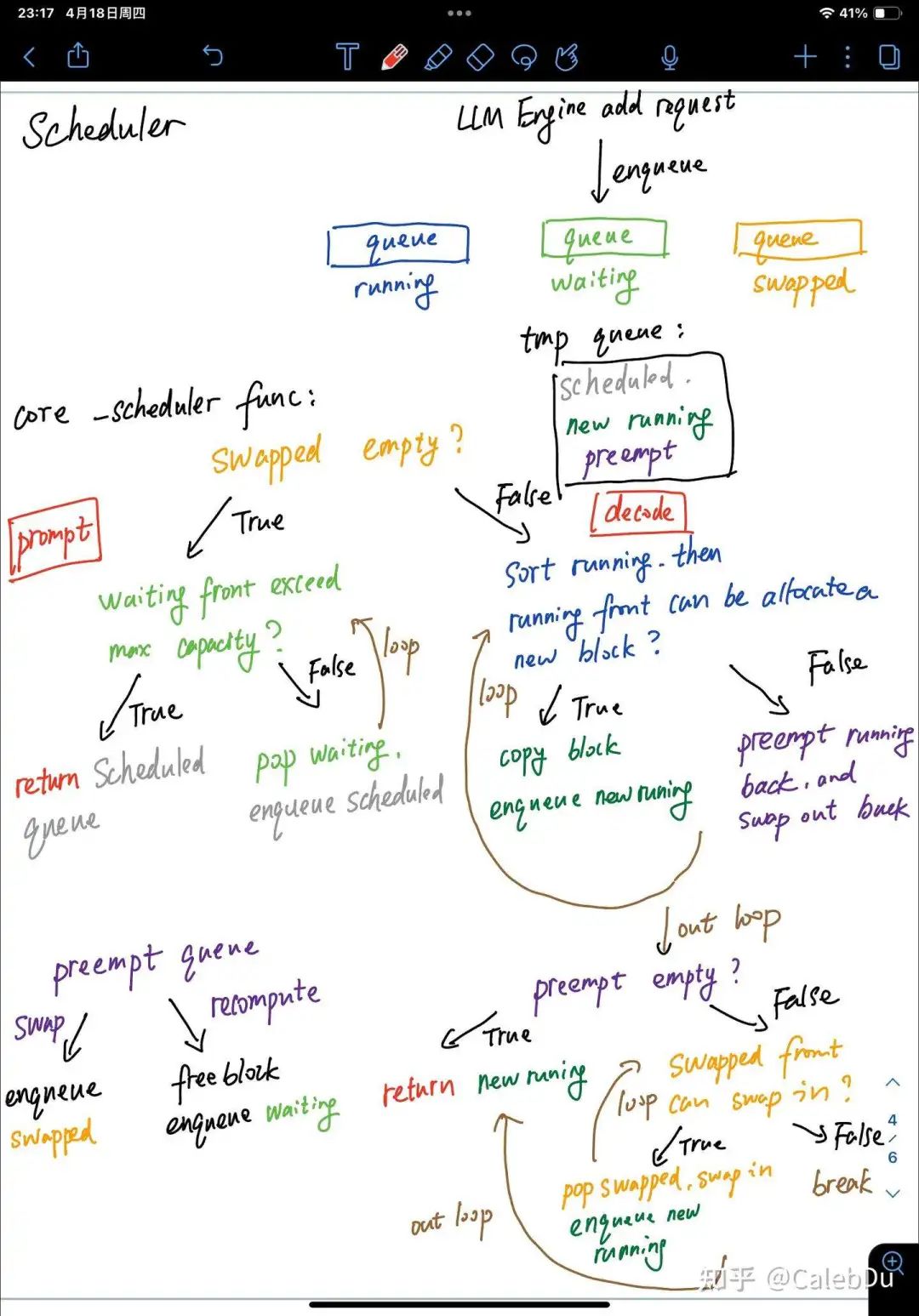
【prompt phase】(调度waiting)首先判断swapped队列是否为空,若为空则表示没有更早的未完成的request,则把waiting队列中的元素出队加入scheduled队列,直至超过block分配上限或vLLM系统最大seq 上限。_scheduler()返回scheduled队列
【decoding phase】:
如swapped不为空,则优先处理之前换出的请求。(调度running)首先对running中的请求依照FCFS的policy进行排序,decoding phase SentenceGroup 中的所有的Sentence由于sampling可能会产生不同的output token,需要对每个Sentence分配不同的新的slot存储新的token。若现有的free block不能满足为所有的Sentence,则running 队尾的sentence 被抢占出队加入preempt队列[recompute mode 则加入waitting 队列并释放block, swap mode 则加入swapped队列 并swap-out block],直至能够为running 队首的所有的sentence分配block,并将队首的元素出队加入new running。(调度swapped)再对swapped队列依照FCFS的policy进行排序,若preempt不为空,说明block资源紧张,_scheduler()直接返回 new running 和swap-out block索引。若preempt为空,block资源可能有富余,则尝试循环将swapped 队首的元素swap-in,若成功则加入new running,否则直接返回 new running 和swap-in 索引。
【Scheduler更新】commit:cc74b 的code base下,Scheduler 默认的调度逻辑(_schedule_default)基本不边,还是和上文描述的一致,保证本次调度的SetenceGroup全部是prompt phase或decode phase,只不过从完整的_scheduler() 函数对running waiting swapped 调度重构拆分为3个细粒度的函数_schedule_prefills、_schedule_running、_schedule_swapped。
此外Scheduler还新增了一种新的调度策略(_schedule_chunked_prefill),新的策略支持本次调度的SentenceGroup同时进行prompt phase和decode phase,能尽可能提高单次matmul的weight 搬运的利用率,提高request并行度以提高tps吞吐。该策略的主要流程是:先执行_schedule_running,保证running 队列中decode phase 的高优先级SentenceGroup 有足够的block给每个Sentence生成新的output token,否则preempt running队列中低优先级SentenceGroup。在执行_schedule_swapped,把满足free block资源的swapped SentenceGroup swap-in。最后执行_schedule_prefills,把waiting 队首的SentenceGroup调度直至超出block分配上限。把running、swapped、waiting 成功调度的请求组成新的running 队列输出。需要注意由于running队列中的SentenceGroup会处于prompt phase或decode phase,需要标记每个SentenceGroup所处的阶段,在执行Attention的时候会把prompt phase 和decode phase分开进行执行。
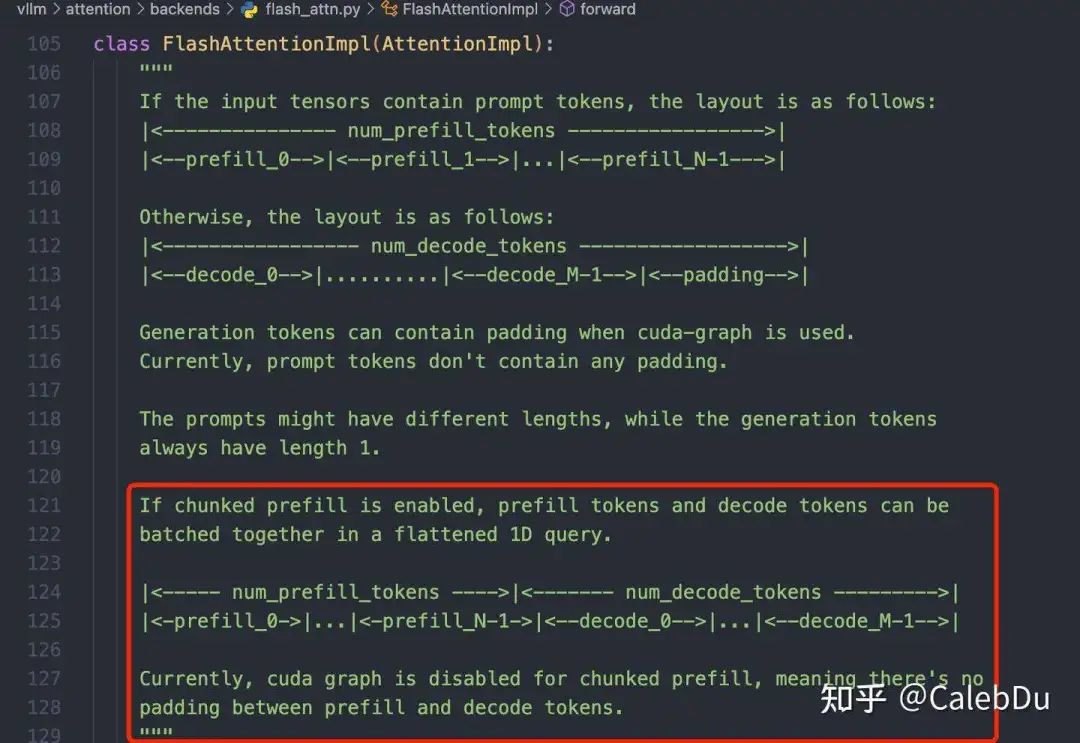
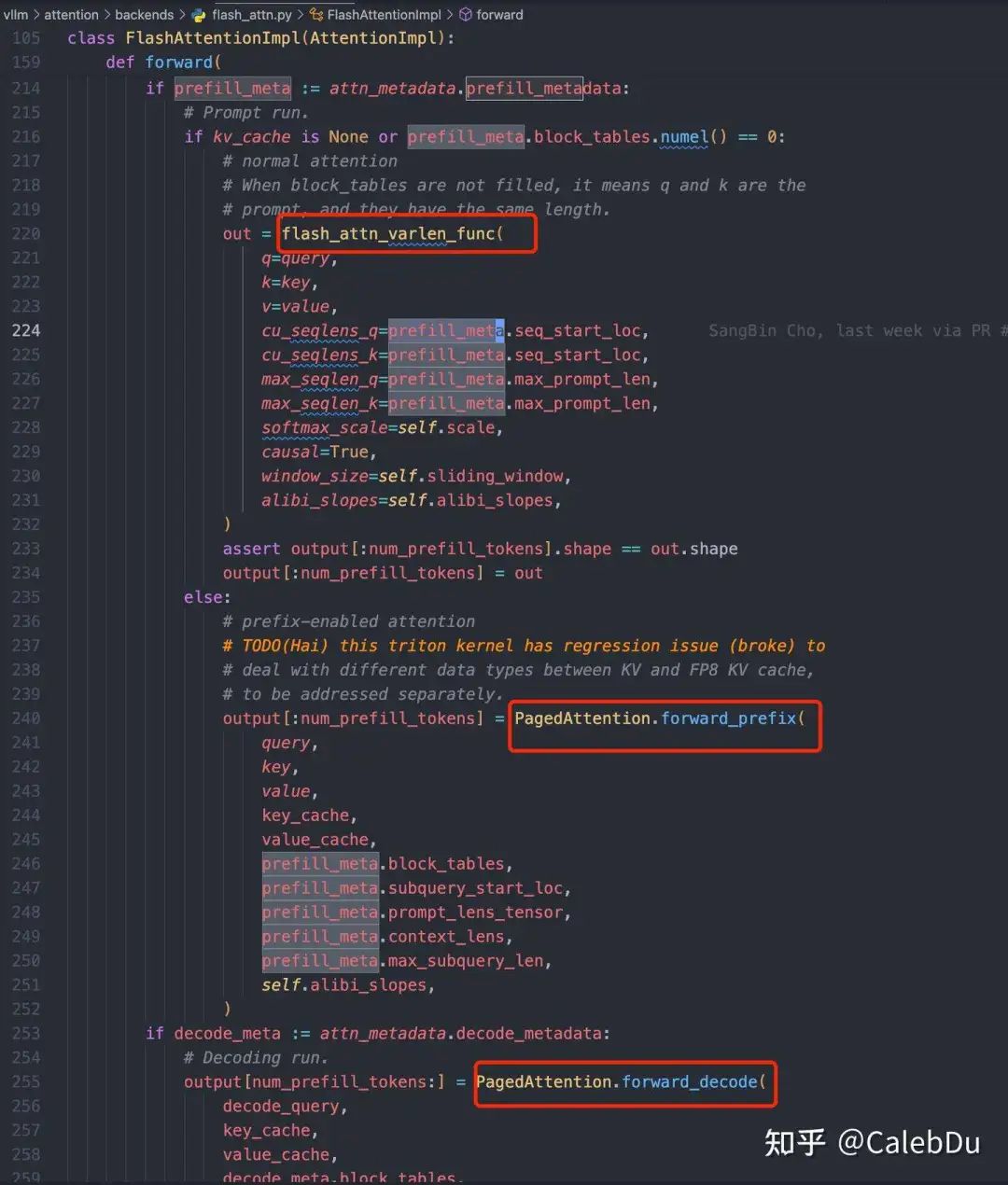
vLLM的代码库有几个礼拜没更新,发现很多地方已经重构了,尴尬。。。
之后再更新存储管理和page attention相关 kernel解析。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









