



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文均出自『自动驾驶之心知识星球』,自动驾驶最前沿每日更新!

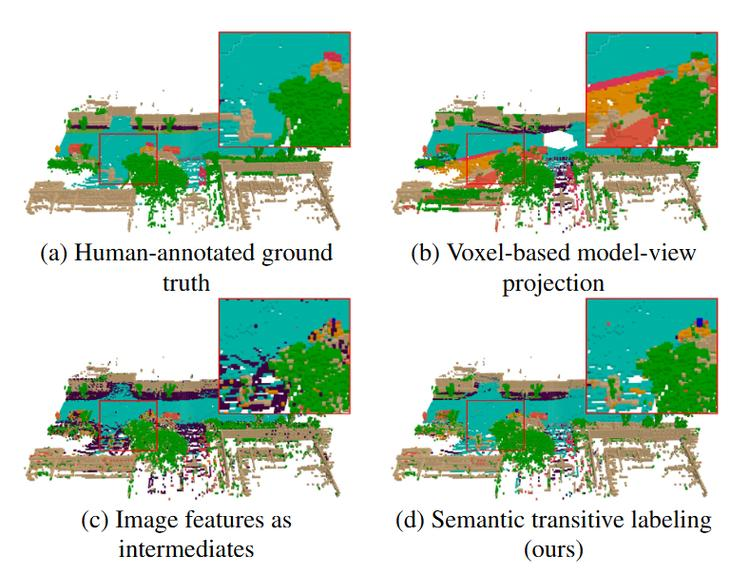
LOcc:一个有效且具有良好泛化能力的开放词汇占用(OVO)预测框架
可以生成更准确的伪标签真值,从而减少了劳动密集型的人工标注。Occ3D-nuScenes数据集上的表现 consistently 超过了当前最先进的零样本占用预测方法。
题目:Language Driven Occupancy Prediction
作者单位:浙江大学,菜鸟
开源地址:https://github.com/pkqbajng/LOcc
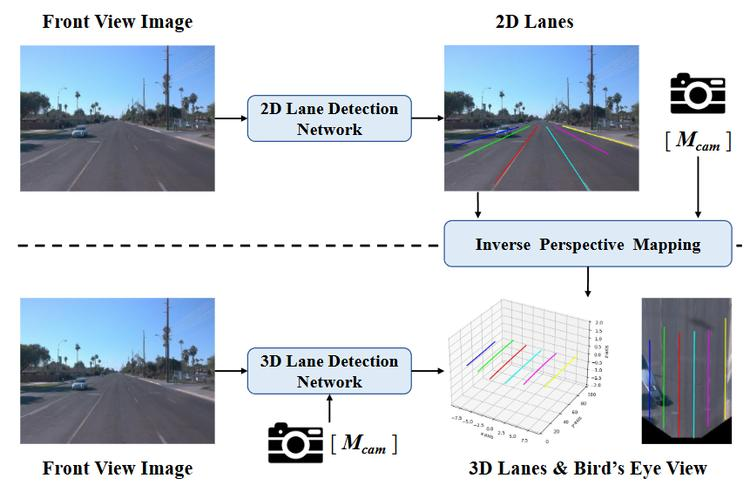
基于深度学习的单目视觉车道检测研究综述
对现有方法进行了全面概述,涵盖了逐渐成熟的2D车道检测方法和正在发展的3D车道检测方法。还介绍了一些车道检测的扩展工作,包括多任务感知、视频车道检测、在线高精(HD)地图构建和车道拓扑推理,以为读者提供车道检测演进的全面路线图。
题目:Monocular Lane Detection Based on Deep Learning: A Survey
作者单位:中科院大学,西安交大,鹏城实验室等
开源地址:https://github.com/Core9724/Awesome-Lane-Detection
自动驾驶软硬一体演进趋势研究报告
尽管软硬一体已经成了行业内很多领先玩家的重要战略,但是目前仍没有对软硬一体给出有效的定义,本报告尝试给出一个对于软硬一体讨论范畴的定义。

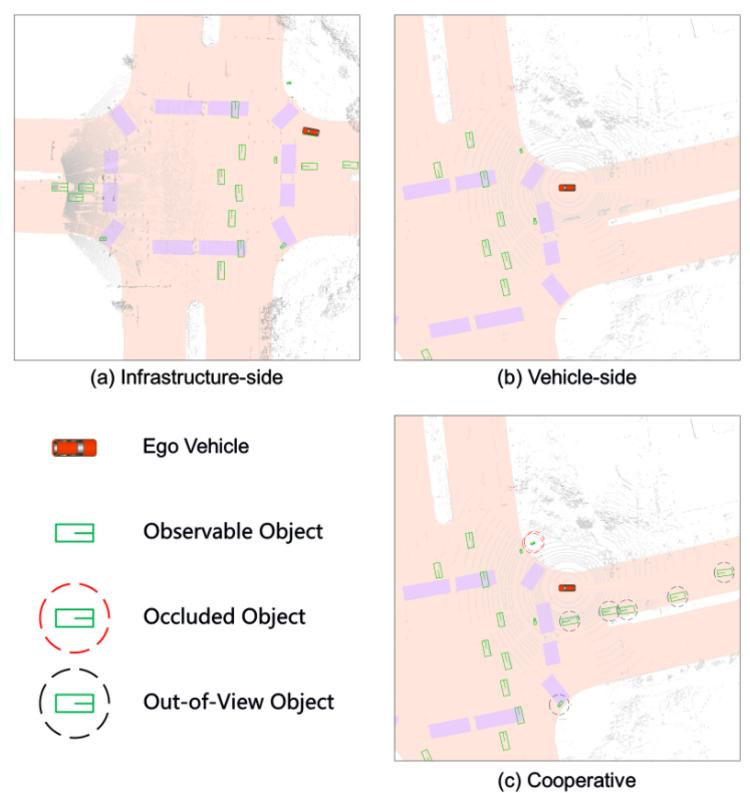
基于激光雷达的车辆基础设施端到端时间感知
LET-VIC通过利用车与一切(V2X)通信,融合车辆和基础设施传感器的空间和时间数据,增强了时间感知能力。在V2X-Seq-SPD数据集上的实验结果表明,LET-VIC显著优于基准模型,在不考虑通信延迟的情况下,mAP提高了至少13.7%,AMOTA提高了13.1%。
题目:LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
作者单位:北京科技大学,清华大学,香港大学
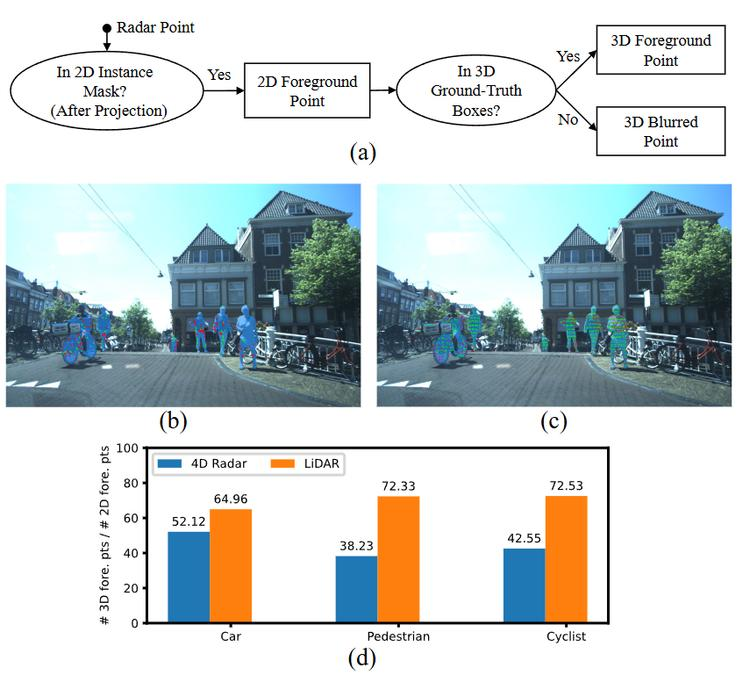
开始超越传统LiDAR? MSSF: 用于自动驾驶中3D目标检测的4D雷达和相机融合框架
与现有最先进的方法相比,MSSF在VoD和TJ4DRadSet数据集上分别实现了7.0%和4.0%的3D平均精度提升,甚至在VoD数据集上超过了传统的LiDAR方法。
题目:MSSF: A 4D Radar and Camera Fusion Framework With Multi-Stage Sampling for 3D Object Detection in Autonomous Driving
作者单位:中国科学技术大学
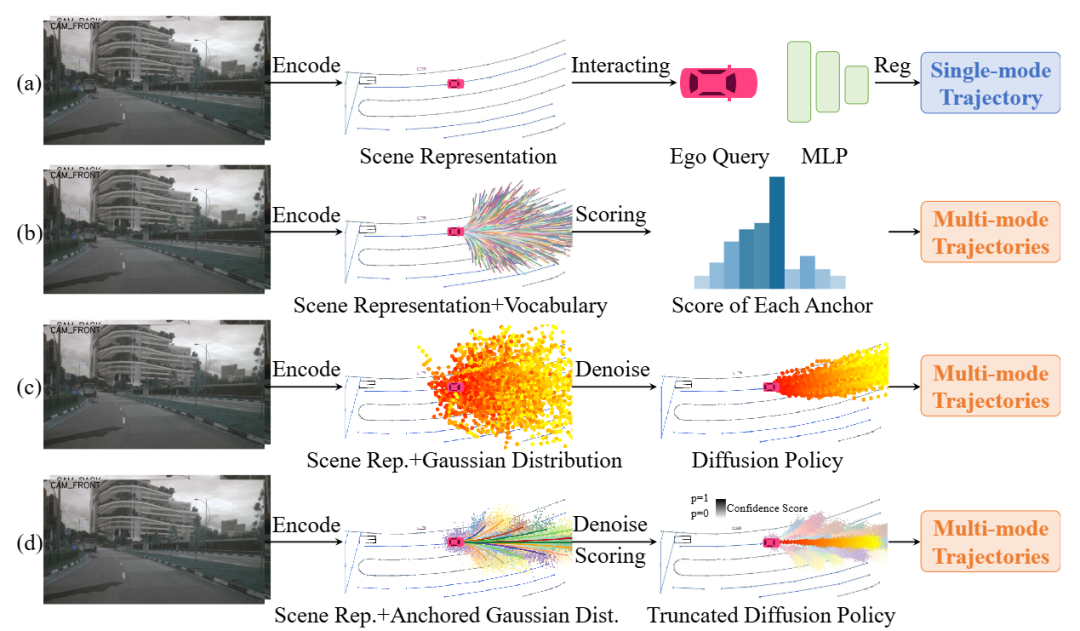
去噪步骤上减少10倍!DiffusionDrive:面向端到端自动驾驶的截断扩散模型
在仅需2步的情况下就能够提供更优质和多样的结果。在以规划为导向的NAVSIM数据集上,结合ResNet-34骨干网络,DiffusionDrive在没有任何额外优化的情况下达到了88.1的PDMS,创下了新纪录!
题目:DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
作者单位:华中科技大学,地平线
开源地址:https://github.com/hustvl/DiffusionDrive

















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









