



作者 | 微动变量 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/715018829
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
学习某种工具最好的办法就是实践,深入浅出,首先对CUDA的概念和关键定义有个了解,在脑子里形成简易记忆,知道下次遇到这个概念去哪里翻找;下一步定一个实践目标,例如去魔改某个开源库或者整合几个开源库。
step1: 概念
查看本专栏其他几篇关于CUDA的文章
step2: 实践
< Probing the Efficacy of Hardware-Aware Weight Pruning to Optimize the SpMM routine on Ampere GPUs > , PACT2022
https://gac.udc.es/~basilio/papers/Castro22-MLSparse.pdf
GitHub - UDC-GAC/CLASP: CoLumn-vector pruning-Aware SPmm kernel
<MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models>
https://github.com/IST-DASLab/Sparse-Marlin
https://www.microsoft.com/en-us/research/uploads/prod/2023/05/N_M_Sparse_kernels__MLSys23.pdf
https://github.com/microsoft/SparTA/tree/nmsparse
《Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity》
https://arxiv.org/pdf/2309.10285
https://github.com/AlibabaResearch/flash-llm
其他参考:
https://github.com/NVIDIA/CUDALibrarySamples
https://github.com/zchee/cuda-sample
GitHub - google-research/sputnik: A library of GPU kernels for sparse matrix operations.
https://github.com/wangsiping97/FastGEMV
https://github.com/Guangxuan-Xiao/SPMM-CUDA
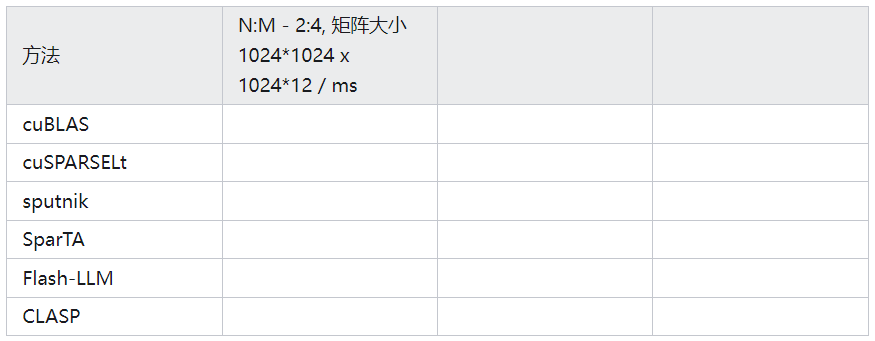
整合以上三篇工作,对比它们在N:M剪枝方法中常见稀疏矩阵运算的性能。
参考https://github.com/microsoft/SparTA/tree/nmsparse, 定义稀疏矩阵测试样例
构建一个合适的project目录
结果记录:
step3 (进阶):
<ELSA: Exploiting Layer-wise N:M Sparsity for Vision Transformer Acceleration> how to choose best N:M + 《VENOM: A Vectorized N:M Format for Unleashing the Power of Sparse Tensor Cores》 kernel supports arbitray N:M
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵



















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









