



作者 | BBuf 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/2130907920
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
blog链接:https://pytorch.org/blog/cuda-free-inference-for-llms/
无CUDA的LLM推理
作者:Adnan Hoque, Less Wright, Raghu Ganti 和 Mudhakar Srivatsa
在这篇博客中,我们讨论了如何使用OpenAI的Triton语言实现流行的LLM模型(如Meta的Llama3-8B和IBM的Granite-8B Code)的FP16推理,其中 100% 的计算都是使用Triton语言完成的。对于使用我们基于Triton kernel的模型进行单个token生成的时间,我们能够在Nvidia H100 GPU上达到相对于CUDA kernel主导工作流的0.76-0.78x性能,在Nvidia A100 GPU上达到0.62-0.82x性能。
为什么要探索使用100%的Triton?Triton为LLM在不同类型的GPU(如NVIDIA、AMD,以及未来的Intel和其他基于GPU的加速器)上运行提供了一条路径。它还为GPU编程提供了更高层次的Python抽象,使我们能够比使用特定供应商的API更快地编写高性能kernel。在本文的其余部分,我们将分享我们如何实现无CUDA的计算,对单个kernel进行微基准测试以进行比较,并讨论我们如何进一步改进未来的Triton kernel以缩小差距。
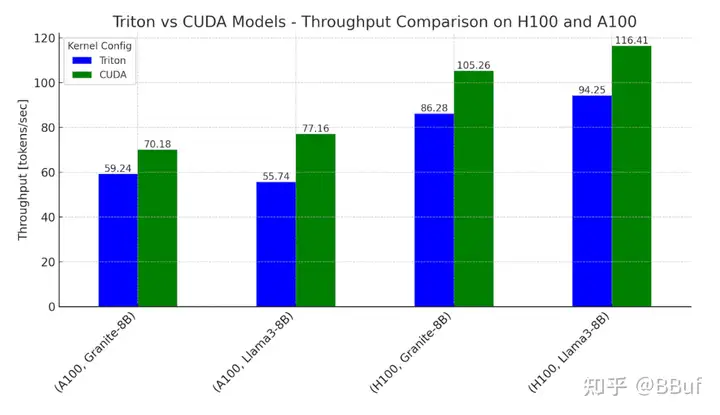
图1. 在NVIDIA H100和A100上,Llama3-8B和Granite-8B的Triton和CUDA变体的推理吞吐量基准测试 设置:批量大小 = 2,输入序列长度 = 512,输出序列长度 = 256
2.0 Transformer块的组成
我们从Transformer模型中发生的计算分解开始。下图显示了一个典型Transformer块的“kernels”。
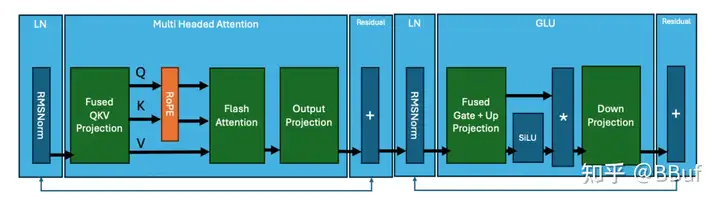
图2. 按核心kernels划分的Transformer块
Llama3架构的核心操作总结如下:

这些操作中的每一个都是通过在GPU上执行一个(或多个)kernels来计算的。尽管这些kernels的具体细节在不同的transformer模型中可能有所不同,但核心操作保持不变。例如,IBM的Granite 8B Code模型在MLP层中使用了偏置,这与Llama3不同。这种变化确实需要对kernels进行修改。一个典型的模型是由这些transformer块堆叠在一起,并通过嵌入层连接起来的。
3.0 模型推理
典型的模型架构代码与一个由PyTorch启动的python model.py文件共享。在默认的PyTorch eager执行模式下,这些kernel都是使用CUDA执行的。为了实现Llama3-8B和Granite-8B端到端推理的100% Triton,我们需要编写和集成手写的Triton kernel,并利用torch.compile(生成Triton操作)。首先,我们用编译器生成的Triton kernel替换较小的操作,其次,我们用手写的Triton kernel替换更昂贵和复杂的计算(例如矩阵乘法和flash attention)。
Torch.compile自动为RMSNorm、RoPE、SiLU和Element Wise Multiplication生成Triton kernel。使用Nsight Systems等工具,我们可以观察这些生成的kernel;它们在矩阵乘法和注意力之间显示为微小的深绿色kernel。

图3. Llama3-8B 使用 torch.compile 的跟踪,显示用于矩阵乘法和 flash attention 的 CUDA kernels
对于上述跟踪,我们注意到在 Llama3-8B 风格的模型中,构成 80% 端到端延迟的两个主要操作是矩阵乘法和注意力 kernels,并且这两个操作仍然是 CUDA kernels。因此,为了缩小剩余的差距,我们用手写的 Triton kernels 替换了矩阵乘法和注意力 kernels。
4.0 Triton SplitK GEMM Kernel
对于线性层中的矩阵乘法,我们编写了一个自定义的FP16 Triton GEMM(通用矩阵-矩阵乘法)kernel,该kernel利用了SplitK工作分解(https://pytorch.org/blog/accelerating-moe-model//#30-work-decomposition---splitk)。我们之前在其他博客中讨论过这种并行化方法,作为加速LLM推理解码部分的一种方式。
这里对上面博客中的 Work Decomposition - SplitK 一节也翻译一下
工作分解 - SplitK
我们之前已经证明,对于LLM推理中发现的矩阵问题大小,特别是在W4A16量化推理的背景下,通过应用SplitK工作分解(https://arxiv.org/abs/2402.00025),GEMM内核可以加速。因此,我们通过在vLLM MoE kernel(https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/layers/fused_moe/fused_moe.py)中实现SplitK,开始了我们的MoE加速研究,这相对于数据并行方法产生了大约18-20%的加速。
这一结果表明,SplitK优化可以作为在推理设置中改进/开发Triton kernel的更公式化方法的一部分。为了建立对这些不同工作分解的直觉,让我们考虑一个简单的例子,即两个4x4矩阵的乘法和SplitK=2。
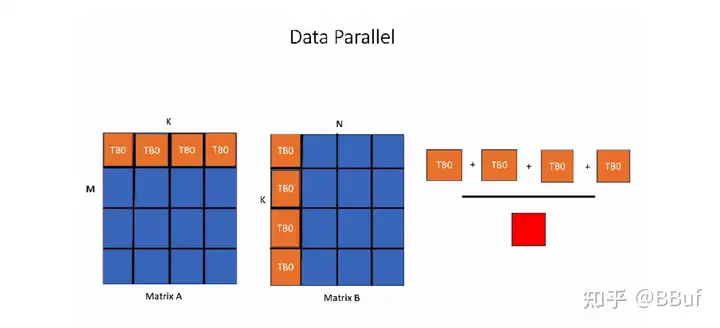
在下图中显示的数据并行GEMM kernel中,输出矩阵的单个块的计算将由1个线程块TB0处理。
相比之下,在SplitK kernel中,计算输出矩阵中单个块所需的工作被“分割”或共享给两个线程块TB0和TB1。这提供了更好的负载均衡和增加的并行性。
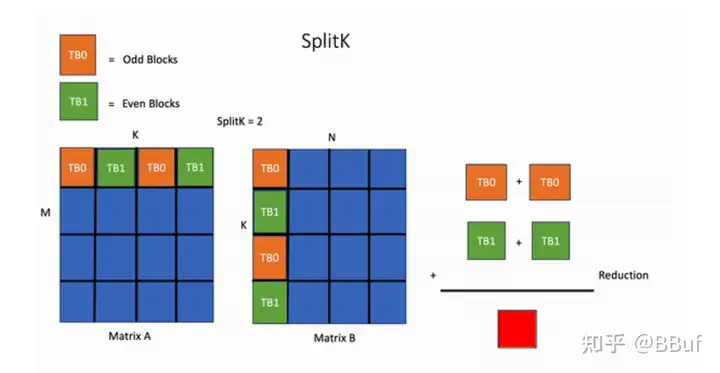
关键思想是我们将并行性从MN增加到MN*SplitK。这种方法确实会带来一些成本,例如通过原子操作增加线程块间通信。然而,这些成本相对于节省的其他受限GPU资源(如共享内存和寄存器)来说是微不足道的。最重要的是,SplitK策略为瘦矩阵(如MoE推理中的情况)提供了优越的负载均衡特性,并且在解码和推理期间是常见的矩阵配置文件。
5.0 GEMM Kernel 调优
为了实现最佳性能,我们使用了穷举搜索方法来调优我们的SplitK GEMM kernel。Granite-8B和Llama3-8B的线性层具有以下形状:

Figure 4. Granite-8B and Llama3-8B Linear Layer Weight Matrix Shapes
这些线性层具有不同的权重矩阵形状。因此,为了获得最佳性能,Triton kernel必须针对每种形状配置进行调优。在对每个线性层进行调优后,我们能够在Llama3-8B和Granite-8B上实现1.20倍的端到端加速,相比于未调优的Triton kernel。
6.0 Flash Attention Kernel
我们评估了一系列具有不同配置的现有Triton flash attention kernels,分别是:
AMD Flash(https://github.com/ROCm/triton/blob/triton-mlir/python/perf-kernels/flash-attention.py)
OpenAI Flash(https://github.com/triton-lang/triton/blob/main/python/tutorials/06-fused-attention.py)
Dao AI Lab Flash(https://github.com/Dao-AILab/flash-attention/blob/3669b25206d5938e3cc74a5f7860e31c38af8204/flash_attn/flash_attn_triton.py#L812)
XFormers Flash(https://github.com/facebookresearch/xformers/blob/fae0ceb195a41f2ab762d89449c6012fbcf2ffda/xformers/ops/fmha/triton_splitk.py#L96)
PyTorch FlexAttention(https://github.com/pytorch/pytorch/blob/e7b870c88bc3b854a95399a96a274d2f1f908172/torch/nn/attention/flex_attention.py#L800)
我们评估了每个kernel的文本生成质量,首先在eager模式下进行评估,然后(如果我们能够使用标准方法对kernel进行torch.compile)在编译模式下进行评估。对于kernel 2-5,我们注意到以下几点:
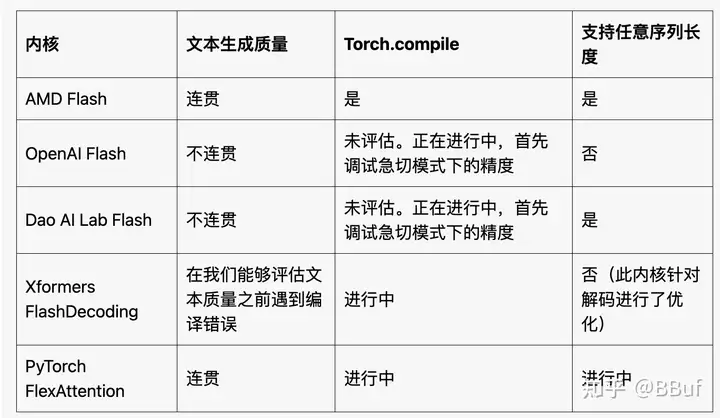
图5. 我们尝试的不同Flash Attention Kernels的组合表
上表总结了我们开箱即用的观察结果。我们预计通过一些努力,kernel 2-5可以被修改以满足上述标准。然而,这也表明,拥有一个适用于基准测试的kernel通常只是使其可用作端到端生产kernel的开始。我们选择在后续测试中使用AMD flash attention kernel,因为它可以通过torch.compile进行编译,并且在eager模式和编译模式下都能产生可读的输出。
为了满足AMD flash attention内核与torch.compile的兼容性,我们必须将其定义为torch自定义操作符。这个过程在这里有详细解释。教程链接讨论了如何包装一个简单的图像裁剪操作。然而,我们注意到包装一个更复杂的flash attention内核遵循类似的过程。两个步骤如下:
将函数包装成PyTorch自定义操作符

为操作符添加一个FakeTensor Kernel,该Kernel根据flash(q、k和v)输入张量的形状提供一种计算flash kernel输出形状的方法
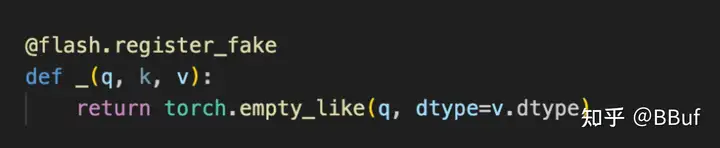
在将Triton flash kernel定义为自定义操作符后,我们能够成功地为我们的端到端运行进行编译。
图6。在替换Triton matmul和Triton flash attention kernel后,Llama3-8B的torch.compile跟踪
从图6中,我们注意到,在整合了SplitK矩阵乘法kernel、torch操作符包装的flash attention kernel,并运行torch.compile后,我们能够实现一个使用100% Triton计算kernel的前向pass。
7.0 End-to-End Benchmarks
我们在NVIDIA H100s和A100s(单GPU)上对Granite-8B和Llama3-8B模型进行了端到端测量。我们使用两种不同的配置进行了基准测试。
Triton kernel配置使用:- Triton SplitK GEMM - AMD Triton Flash Attention
CUDA kernel配置使用:- cuBLAS GEMM - cuDNN Flash Attention - Scaled Dot-Product Attention(SDPA)
我们发现在典型的推理设置下,eager模式和torch编译模式下的吞吐量和token间延迟如下:

图7。Granite-8B和Llama3-8B在H100和A100上的单token生成延迟, (批量大小 = 2,输入序列长度 = 512,输出序列长度 = 256)
总结来说,Triton模型在H100上可以达到CUDA模型性能的78%,在A100上可以达到82%。
性能差距可以通过我们在下一节中讨论的矩阵乘法和flash attention的kernel延迟来解释。
8.0 Microbenchmarks

图8. Triton 和 CUDA kernel 延迟比较(Llama3-8B 在 NVIDIA H100 上) 输入是一个任意提示(bs=1, prompt = 44 seq length),解码延迟时间
从上述结果中,我们注意到以下几点:
Triton 矩阵乘法 kernel 比 CUDA 慢 1.2-1.4 倍
AMD 的 Triton Flash Attention kernel比 CUDA SDPA 慢 1.6 倍
这些结果突显了进一步提高GEMM和Flash Attention等核心原语kernel性能的必要性。我们将其留作未来的研究,因为最近的工作(例如FlashAttention-3(https://pytorch.org/blog/flashattention-3/),FlexAttention(https://pytorch.org/blog/flexattention/))提供了更好地利用底层硬件的方法,以及我们希望能够在其基础上构建以实现更大加速的Triton路径。为了说明这一点,我们将FlexAttention与SDPA和AMD的Triton Flash kernel进行了比较。
我们正在努力验证FlexAttention的端到端(E2E)性能。目前,使用Flex进行的初步微基准测试在处理较长上下文长度和解码问题形状(其中查询向量较小)时显示出了良好的前景:
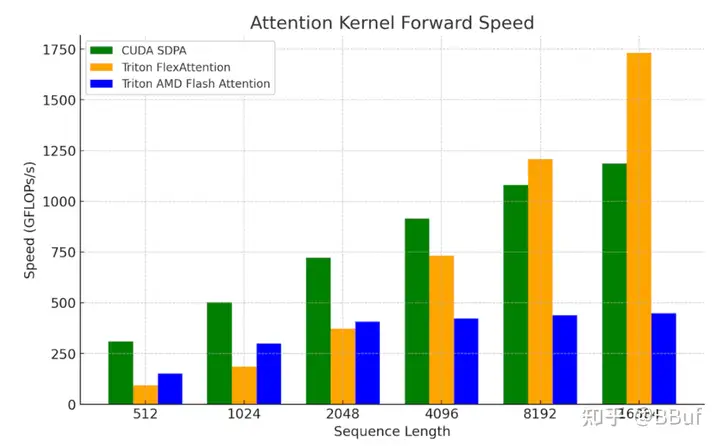
图9。在NVIDIA H100 SXM5 80GB上的FlexAttention kernel基准测试 (批量大小=1,头数=32,序列长度=seq_len,头维度=128)
9.0 Future Work
未来的工作计划包括探索进一步优化我们的矩阵乘法,以更好地利用硬件,例如我们发表的关于在H100上利用TMA的博客(https://pytorch.org/blog/hopper-tma-unit/),以及不同的工作分解(如持久内核技术如StreamK等)以获得更大的速度提升。对于flash attention,我们计划探索FlexAttention和FlashAttention-3,因为这些kernel中使用的这些技术可以帮助进一步缩小Triton和CUDA之间的差距。我们还注意到我们之前的研究表明,FP8 Triton GEMM kernel性能在与cuBLAS FP8 GEMM相比时前景光明,因此在未来的帖子中,我们将探索端到端的FP8 LLM推理。
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵



















 1829
1829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









