



作者 | 一辄@知乎 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/703097381
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
前几天听了王鹤老师的工作分享,感觉很有趣,之后有时间把论文都看一遍,现在简单记下思路
王鹤老师也是银河通用的创始人,现在银河应该融了有3个亿了。无论从具身科研主题,还是做公司来讲,技术逻辑是闭环的,故事脉络很清晰。也听说银河在做药店前置仓的取药探索
我也是具身新手上路,以下部分观点是我个人的理解,如有错误,麻烦指出讨论,谢谢!
本篇文章逻辑:
什么是具身智能 → 什么是具身智能大模型 → 王鹤老师组具身思路 → 具身感兴趣的一些点
什么是具身智能
前几天还听了圆桌讨论具身智能,主持人提的第一个问题就是它的定义。有些嘉宾提到了交互、数据等,我印象比较深的是上交的卢策吾老师提出的最简单的一个定义,具身智能就是具备身体的智能
其实也就是三维物理空间里机器人的智能。它的目标就是听从人类模糊指令做事,有一定自主性的表现。比如在家居场景下,人类坐在卧室说,我口渴了,机器人能自动到厨房的冰箱中拿一瓶可乐递给人类
应该是卢老师提的吧,有几个嘉宾坐在那里,过了几天我有点记不太清了qaq,好像记得那个讲话位置是卢老师
什么是具身智能大模型
从物理空间的角度来划分,大模型可以分为非具身大模型(Disembodied Model)、具身智能大模型(又被叫做机器人大模型)(Embodied VLA Model)。它们的区别是能否生成运动姿态(例如夹爪的末端位姿等),即是否能跟物理机器人联系起来。GPT是前者,RT是后者
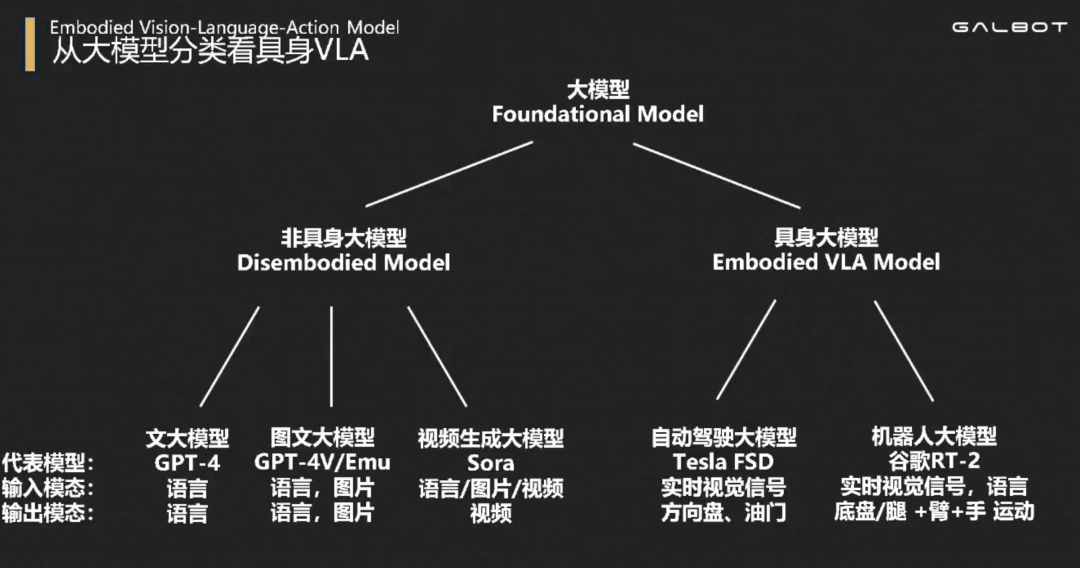
个人觉得,目前具身大模型应该可以分为两大流派。一类是RT这种端到端大模型。一类是分层具身大模型(王鹤老师组是)
端到端具身大模型
以RT2为典型代表。输入是图像及文本指令,输出是夹爪末端动作。直接端到端地实现从人类指令到机械臂执行
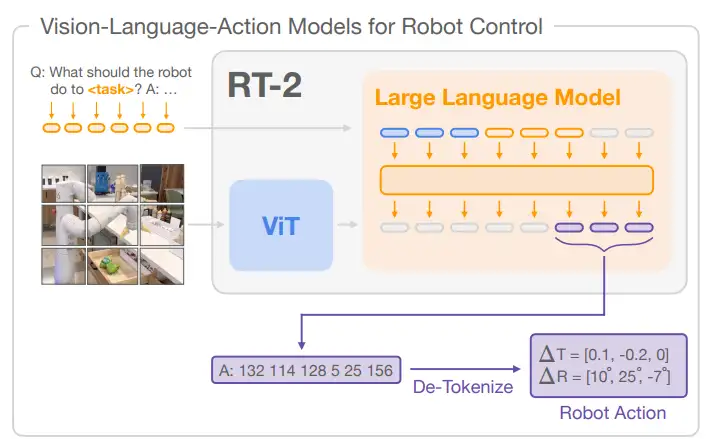
但目前这类端到端的大模型有2个重要缺点:
第一,训练数据难收集,而泛化性差。谷歌花了上千万美金16个人耗时17个月收集得到了13万条厨房数据训练RT,模型在厨房表现很好,但除了厨房成功率却骤降至30%。这种泛化性难其实一定程度上也是数据采集没有做到scalable。归根到底就是数据问题
机器人数据不像当前互联网图像/文本数据那样大量而易得,更缺少机器人界自己的“ImageNet”。数据这方面是一个非常重要的研究课题,之后我会再看一些这方面的工作
可想而知,如果真正要训练一个通用具身大模型,需要的数据量级、数据收集成本、模型训练成本该多恐怖。数据是一项重要制约,所以很多研究转向了分层具身的形式
第二,推理速度慢。RT2中用到的LLM是谷歌的PaLM-E,频率1-3Hz,也就是说响应速度0.3s甚至1s
好像OpenAI和Figure合作用的是小模型,动作输出频率200Hz,还挺丝滑。这个之后我再了解一下
分层具身大模型
目前围绕做决策的大语言模型(如GPT),有许多在做工作流架构,适应机器人使用的
我觉得有两个点比较重要。其一,是需要摸清大语言模型的技术能力边界,它能干什么,不能干什么,不能干什么,不能干的部分就像人类使用工具一样,去调用传统小模型算法解决。其二,大语言模型是二维的,它基本不具备三维物理空间感知能力,也就是需要一些辅助工具来做场景理解(比如一些经典小模型)
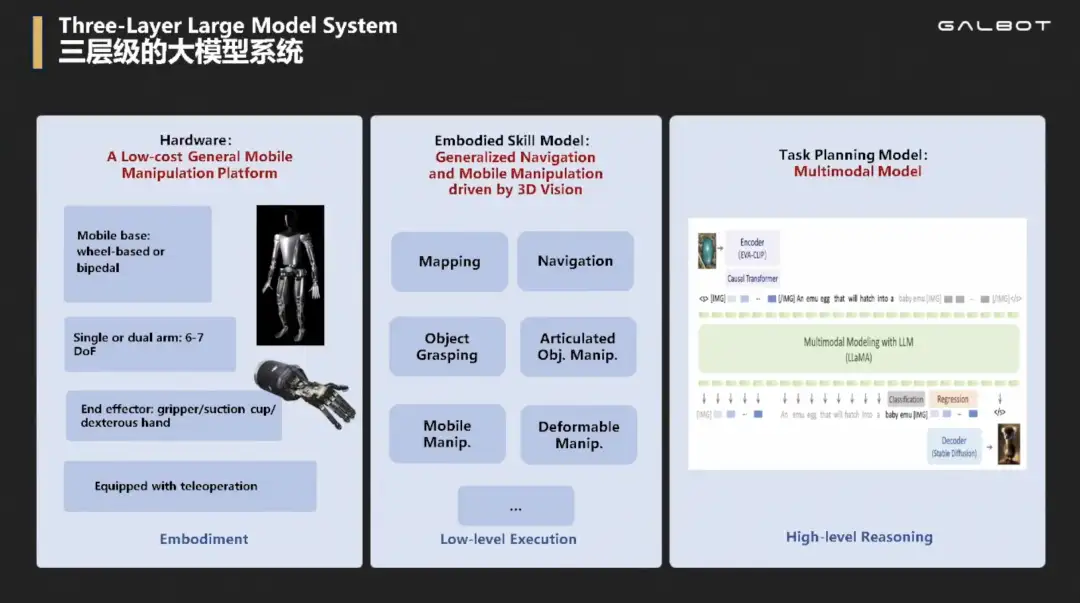
底层是硬件层,中间层是些响应快小模型(比如三维感知、自主建图、自主导航、物体抓取、开门开抽屉开冰箱、移动操作、挂衣服叠衣服、柔性物体操作等),上层是用来做推理慢的做任务规划的大语言模型LLM
当得到指令,LLM负责分析,安排调度哪个小模型API。小模型执行完后,LLM分析结果,研究下一步该怎么做。比如可以加入一些交互、结果判断等等,不同paper工作流中有所不同
例如用三维视觉小模型来弥补LLM场景理解能力差的问题。先用Grounded-SAM小模型做分割、求bbox,再将这处理后的图片扔给GPT,它就能更好地理解做出决策
孰劣孰优
目前端到端VLA性能没有达到通用的原因,是受数据制约。未来当机器人数据达到量级,也许这会是最简单、最优的通用机器人大模型数据实现路径,是一条未来之路
但当下,使用分层具身也不失为一个选择。王鹤老师在演讲中提到了一个隐藏的逻辑,没有做好小模型的公司、没有能让动作小模型泛化的公司,不可能让大模型泛化。因为大模型在单一任务上的数据需求远高于小模型。而当分层具身做得足够好,或者讲王鹤老师说得抓取、放置、柔性物体操作、关节类物体操作等小模型做得足够好,能够达到B端C端应用落地的程度,机器设备在某个场景下铺开,会收集到大量数据,跑通数据飞轮,为实现端到端VLA的训练打下坚实的基础
这是蛮有意思的一点。现在很多做具身智能、人形机器人的创业团队其实都意识到这波物理AI变革应该在智能性上,而从目前的技术道路上来看(不排除未来会出现新的通向AGI的技术方向),数据是最大的制约瓶颈。大家都想率先跑起数据飞轮,反向提升模型性能,都在讲这个故事。但大家都明白这个逻辑,能找到一条自己的道路讲清自身的优势、为什么自己的产品能铺开使用,如何达成故事闭环,这是很考验初创公司和创始人战略思维的一点
王鹤老师组工作
感觉听演讲,有两个方面。其一,就是上面提到的分层具身智能大模型的框架流程。其二,是三维数据仿真
王鹤老师2017年读博时就在做仿真研究。可以通过生成大量三维仿真数据,来训练分层具身框架里的中间小模型,让其有更好的三维理解能力。有些小模型如果用二维图像来训,也缺少一些空间信息
Figure好像用的就是二维视觉模型,很难泛化,受光照等很大影响。而三维数据能看到的是点云、物体的几何,不会受到外部环境颜色、光照、纹理等影响 目前读的论文还不多,还处在泛读和学习阶段。以下我比较感兴趣的几个点,之后想看下王鹤老师及其它国内外学者做的研究,也找找综述啥的。如果评论区朋友们能帮我指路就更感谢啦!
其一,仿真数据合成方式(及目前应对数据不足的从数据端、模型端的应对方式)
其二,分层具身这个思想在不同组的具体实现框架区别
其三,机器人大模型中对三维视觉/场景理解的部分(是二维LLM很匮乏的一点)
其四,抓取(通过海量合成数据的泛化抓取训练思路等)
其五,导航大模型(好像银河有个工作是在没有三维定位建图激光雷达,只在图片/命令下在未知环境里行走找路,也有看到一些其它相关工作)
更多资料欢迎加入『具身智能知识星球』,国庆期间我们偷偷搭建了一个全栈技术社区


① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









