



作者 | erkang 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/707464289
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
做了粗略的LLM在自动驾驶中的survey
汇总了相关的paper list
方便快速了解信息,摘取了abstract,图-问题描述,图-方法overview
TODO:归纳分类 & 极简总结
整体感觉,目前的LLM for Autonomous Driving虽然很火,在三维世界理解下的reasoning还是大有可为,尤其是为端到端服务。
Sec-1: Paper list
[1] LMDrive: Closed-loop End-to-End Driving with Large language Models
[2] Driving Everywhere with Large Language Model Policy Adaptation
[3] ADAPT: Action-aware Driving Caption Transformer
[4] Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
[5] DriVLMe: Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experience
[6] Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Model
[7] DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
[8] ADriver-I: A General World Model for Autonomous Driving
[9] DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
[10] Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
[11] Embodied Understanding of Driving Scenarios
[12] Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
[13] OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
[14] Dolphins: Multimodal Language Model for Driving
[15] HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving
[16] Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving
[17] RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
[18 ]AD-H: Autonomous Driving with Hierarchical Agents
[19] Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
[20] LingoQA: Video Question Answering for Autonomous Driving
[21] 3D Dense Captioning beyond Nouns: A Middleware for Autonomous Driving
[22] Probing Multimodal LLMs as World Models for Driving
[23] LeGo-Drive: Language-enhanced Goal-oriented Closed-Loop End-to-End Autonomous Driving
[24] LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding|
[25] DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
Sec-2: Paper汇总
包含Title, Venue, Year, Institute, Abstract, Fig-Problem-define, and Fig-Method-Overview
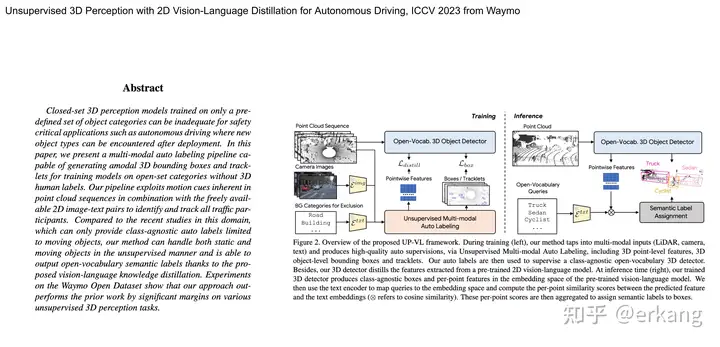









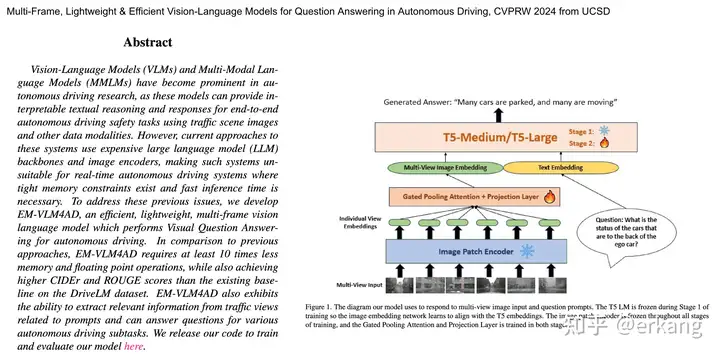


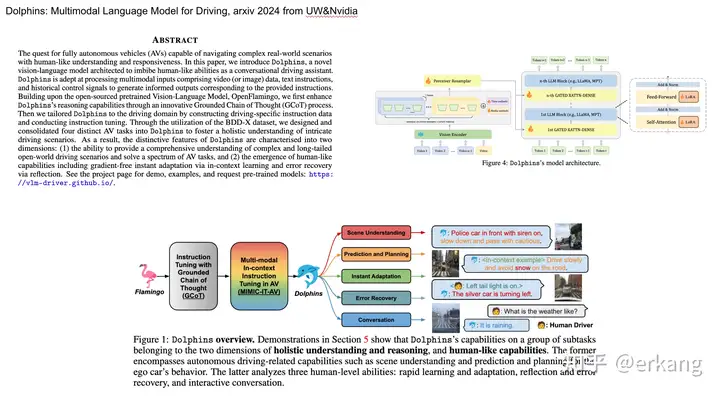








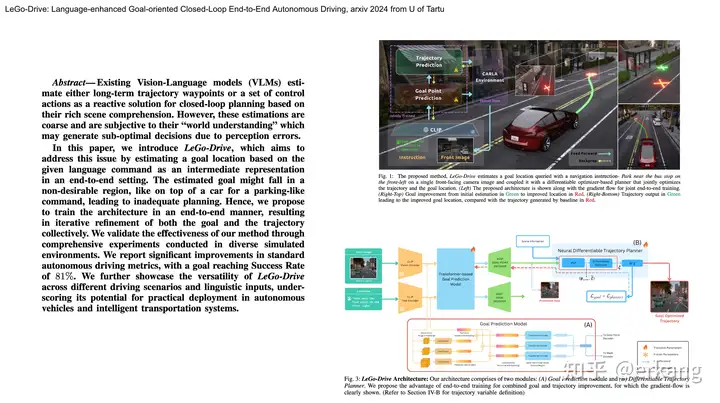
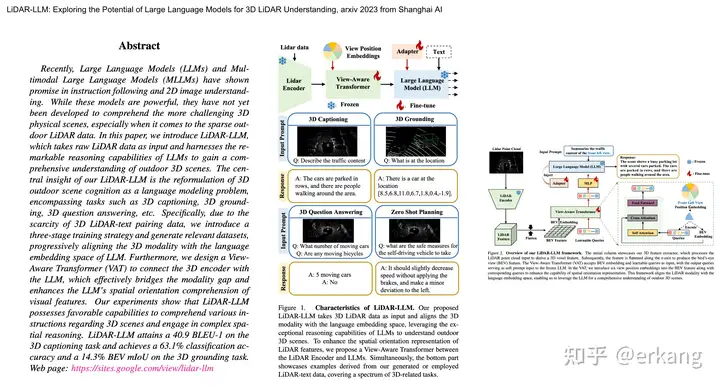

投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









