



 本文介绍了一种新型的生成式端到端自动驾驶模型GenAD,它结合了生成式人工智能和端到端技术,通过实例中心的场景表示和结构化隐空间学习,实现了更有效的未来轨迹预测和规划。在nuScenes基准测试中,GenAD表现出SOTA性能,有望推动自动驾驶技术的发展。
本文介绍了一种新型的生成式端到端自动驾驶模型GenAD,它结合了生成式人工智能和端到端技术,通过实例中心的场景表示和结构化隐空间学习,实现了更有效的未来轨迹预测和规划。在nuScenes基准测试中,GenAD表现出SOTA性能,有望推动自动驾驶技术的发展。
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心为大家分享中科慧拓和中科院自动化所最新提出的GenAD—超越UniAD,生成式端到端自动驾驶最新SOTA!文章已经授权自动驾驶之心原创!如果您有相关工作需要分享,请在文末联系我们!
本文作者 | Ruiqi Song&Xianda Guo
编辑 | 自动驾驶之心
写在前面
生成式人工智能(Generative AI)正催生出科技领域的一场创新革命,其中ChatGPT作为开创性的代表,展示了强大的自然语言处理和生成能力。本文将生成式人工智能(Generative AI)和端到端自动驾驶技术结合,提出生成式端到端自动驾驶GenAD。GenAD提出以实例为中心的场景表示,首先将周围场景转换为地图和感知实例。然后,使用变分自编码器在结构化隐空间中学习未来轨迹分布,用于轨迹先验建模。进一步采用时序模型来捕捉隐空间中的agent和自车运动,以生成更有效的未来轨迹。最终,GenAD通过在学习的结构化隐高斯空间分布中采样,并使用学习的时序模型生成未来信息,同时执行运动预测和规划。GenAD超越CVPR2023 best paper UniAD,在广泛使用的nuScenes基准测试中进行的实验证明,所提出的GenAD在以视觉为中心的端到端自动驾驶方面取得了SOTA的性能。
论文链接:https://arxiv.org/abs/2402.11502
代码链接:https://github.com/wzzheng/GenAD
🌐 GenAD:中科慧拓技术团队新成果
中科慧拓技术团队和中科院自动化所共同提出的生成式端到端自动驾驶模型GenAD,将生成式人工智能(Generative AI)和端到端自动驾驶技术结合,是业界首个生成式端到端自动驾驶模型。该技术颠覆了UniAD的渐进式流程端到端方案,探讨了一种新的端到端自动驾驶范式,关键在于采用生成式人工智能的方式预测自车和周围环境在过去场景中的时序演变方式。
技术上本方案提出以实例为中心的场景表示,首先将周围场景转换为地图和感知实例。然后,使用变分自编码器在结构化隐空间中学习未来轨迹分布,用于轨迹先验建模。进一步采用时序模型来捕捉隐含空间中的agent和自车运动,以生成更有效的未来轨迹。最终,GenAD通过在学习的结构化隐高斯空间分布中采样,并使用学习的时序模型生成未来信息,同时执行运动预测和规划。
该模型在城市场景数据集nuScenes已经取得了SOTA的性能,并在实时性能上远超UniAD。同时,中科慧拓技术团队正在进行该技术方案的场景迁移,未来该技术计划推广到矿区自动驾驶场景,助力矿区自动驾驶应用落地。
直接从原始传感器生成规划结果一直以来都是自动驾驶的一个长期期望解决方案,并近年来越来越受到关注。大多数现有的端到端自动驾驶方法将这个问题分解为感知、运动预测和规划。然而,本文认为传统的渐进式流程仍然不能全面地建模整个交通演化过程,例如自车与其他交通参与者之间的未来互动以及结构轨迹先验。在本文中,本文探讨了一种新的端到端自动驾驶范式,关键在于预测自车和周围环境在过去场景中的演变方式。本文提出了GenAD,这是一个将自动驾驶转化为生成建模问题的框架。GenAD提出以实例中心的场景表示,首先将周围场景转换为地图和感知实例。然后,使用变分自编码器在结构化隐空间中学习未来轨迹分布,用于轨迹先验建模。进一步采用时序模型来捕捉隐含空间中的agent和自车运动,以生成更有效的未来轨迹。最终,GenAD通过在学习的结构化隐高斯空间分布中采样,并使用学习的时序模型生成未来信息,同时执行运动预测和规划。在广泛使用的nuScenes基准测试中进行的实验证明,所提出的GenAD在以视觉为中心的端到端自动驾驶方面取得了SOTA的性能。
问题背景
视觉为中心的自动驾驶近年来得到了广泛研究,因其经济便利性而备受关注。虽然研究人员在各种任务中推动了以视觉为中心的自动驾驶的极限,包括3D物体检测、地图分割和3D语义占用预测,但最近以视觉为中心的端到端自动驾驶的进展揭示了一条直接从原始传感器产生规划结果的潜在而优雅的技术路径。
大多数现有的端到端自动驾驶模型由多个模块组成,遵循感知、运动预测和规划的流程。例如,UniAD进一步渐进性地执行地图感知、检测、跟踪、运动预测、占用预测和规划模块,以提高系统的鲁棒性。研究还观察到,使用规划目标可以提高中间任务的性能。然而,现有流水线的序列设计忽略了现有Pipeline中预测和规划之间可能的未来交互,GenAD认为这种交互对准确的规划很重要。例如,自车的车道变化会影响后方车辆的行动,并进一步影响自车的规划。这种高阶交互无法通过当前设计在规划之前进行运动预测有效建模。此外,未来轨迹具有高度结构化并共享一个共同的先验(例如,大多数轨迹都是连续的直线)。然而,大多数现有方法未能考虑这个结构先验,导致不准确的预测和规划。
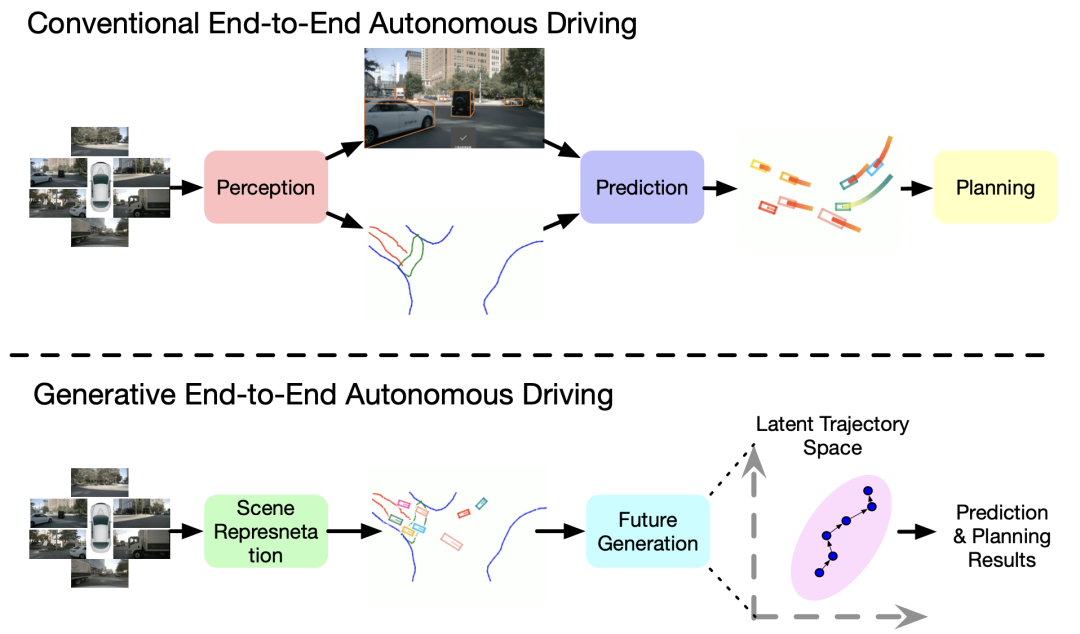
详解GenAD
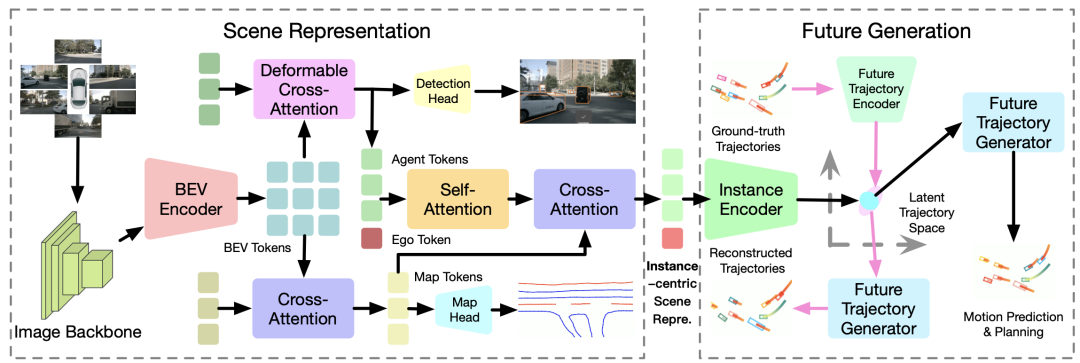
提出了一个生成式端到端自动驾驶(GenAD)框架(如图1所示),将自动驾驶建模为一个轨迹生成问题,以释放端到端方法的全部潜力。GenAD提出了一个场景表示器,用于获取以实例为中心的场景表示,聚焦于实例但也整合了地图信息。为实现这一点,使用一个骨干网络提取每个周围摄像头的图像特征,然后将其转换为3D鸟瞰图(BEV)空间。进一步使用交叉注意力从BEV特征中提炼高级地图和agent token。然后,添加一个自车token,并使用自车-agent自注意力捕捉它们的高阶交互。通过交叉注意力进一步注入地图信息以获得具有地图感知的实例标记。为了建模未来轨迹的结构先验,学习一个变分自编码器,将地面实况轨迹映射到考虑运动预测和驾驶规划的不确定性的高斯分布。然后,使用一个简单而有效的门控循环单元(GRU)进行自回归,以建模结构化隐空间中的实例移动。在推理过程中,从学习的分布中采样,条件是以实例为中心的场景表示,因此可以预测不同的可能未来。GenAD可以同时执行运动预测和规划,使用统一的未来轨迹生成模型。在广泛使用的nuScenes基准测试上进行了大量实验证明,评估了所提出的GenAD框架的性能。基于生成建模,GenAD在高效性能方面取得了最先进的基于视觉的规划性能。
1)以实例为中心的场景表示
端到端自动驾驶的第一步是对传感器输入进行感知,以获取对周围场景的高级描述。这些描述通常包括语义地图和实例边界框。为了实现这一点,GenAD遵循传统的以视觉为中心的感知流程,首先提取鸟瞰图(BEV) 特征,然后在此基础上进行进一步的地图和边界框特征的优化。
由于预测和规划主要关注agent和自车的实例,因此提出了一种实例为中心的场景表示,以全面且高效地呈现自动驾驶场景。首先将自车token添加到学到的agent标记中,构建一组实例tokens。
现有方法通常以串行方式执行运动预测和规划,忽略了未来自车运动对agent的影响。例如,自车的车道变化可能会影响后方车辆的行动,使得运动预测结果不准确。与之不同的是,GenAD通过对实例标记执行自注意力来实现自车和其他agent之间的高阶交互:
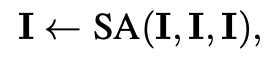
SA(Q,K,V) 表示由使用 Q、K 和 V 作为查询、键和值的自注意力层组成的自注意力块。
此外,为了进行准确的预测和规划,agent和自车都需要了解语义地图信息。因此,GenAD在更新后的实例token和学到的地图token之间使用交叉注意力,获取地图感知的实例为中心的场景表示:
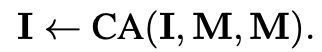
学到的实例标记 I 结合了高阶agent-自车交互,并了解了学到的语义地图,这些地图紧凑但包含执行运动预测和轨迹规划所需的所有必要地图和实例信息。
2)轨迹先验建模
其他车辆的运动预测目标和自车规划共享相同的输出空间,本质上是相同的。它们都旨在在给定语义地图和与其他车辆的交互的情况下,产生所关注实例的高质量真实轨迹。因此,提出的GenAD的目标可以被表述为在给定具有地图感知的以实例为中心的场景表示 I 的情况下,推断未来轨迹 T。
自车和其他车辆的轨迹都具有高度结构化(例如,连续性)并遵循一定的模式。例如,大多数轨迹是直线,表示车辆以恒定速度行驶,而有些轨迹是曲线,表示车辆右转或左转时曲率近似恒定。只有在极少数情况下,轨迹会呈锯齿状。考虑到这一点,GenAD采用变分自编码器(VAE)架构来学习一个隐空间 Z 以建模轨迹的先验知识。具体而言,使用未来轨迹groundtruth编码器,来建模未来轨迹的隐含空间 Z 。
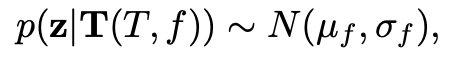
其中,N(μ,σ^2)表示均值为μ,标准差为σ的高斯分布。
3)隐含未来轨迹生成
在获得未来轨迹的隐含分布作为先验之后,需要明确地从隐含轨迹空间 Z 解码它们。虽然一种直接的方法是使用基于MLP的解码器直接在BEV空间中输出轨迹点以建模 ,但它未能对交通agent和自车的时间演变进行建模。为了考虑不同时间戳上实例的时间关系,将联合概率分布分解如下:
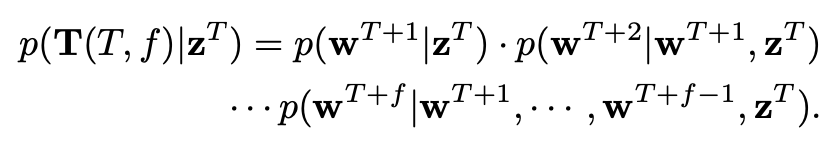
然后,采用门控循环单元(GRU)作为未来轨迹生成器,以建模实例的时间演变。与直接输出整个轨迹的单一解码器相比,MLP解码器执行的任务更简单,仅对BEV空间中的位置进行解码,而GRU模块则模拟了隐含空间Z中agent的移动。因此,考虑到在这个学习结构化隐空间中的先验知识,生成的轨迹更加真实和可信。
4)生成式端到端自动驾驶
在本小节中,介绍了提出的GenAD框架的整体架构,用于以视觉为中心的端到端自动驾驶。给定周围摄像机信号 s 作为输入,首先使用图像骨干网络提取多尺度图像特征 F,然后使用可变形注意力将它们转换为BEV空间。将过去 p 帧的BEV特征对齐到当前自车坐标,得到最终的BEV特征 B。使用全局交叉注意力和可变形注意力分别对地图标记 M 和agent标记 A 进行细化。为了建模交通agent与自车之间的高阶交互,将agent标记与自车标记结合,并在它们之间执行自注意力,构建一组实例标记 I。使用交叉注意力将语义地图信息注入到实例标记 I 中,以促进进一步的预测和规划。
由于真实轨迹具有高度结构,学习了一个VAE模块来建模轨迹先验,并采用生成框架同时进行运动预测和规划。学习一个编码器 et 将地面实况轨迹映射到结构空间 Z 作为高斯分布。然后,采用基于GRU的未来轨迹生成器 g 来模拟隐含空间 Z 中实例的时间演变,并使用一个简单的基于MLP的解码器 dw 从隐含表示中解码出路径点。最终,通过整合每个时间戳的解码路径点,可以重构出交通agent和自车的轨迹 和 。
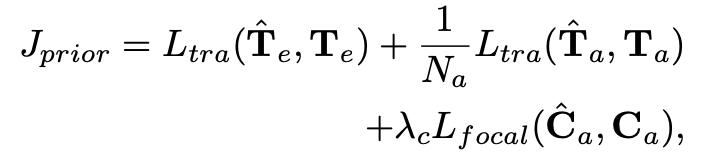
其中,|| · ||₁表示L1范数,Na表示agent的数量,Lfocal表示用于约束预测agent类别的焦点损失。Ltra表示轨迹损失,包括L1差异、自车-agent碰撞约束、自车-边界越界约束以及自车-车道方向约束。Ĉa和Ca分别表示所有agent的预测和groundtruth类别。
运动预测和规划可以统一并被表述为实例分布 p(z|I) 与地面实况分布 p(z|T(T , f )) 之间的分布匹配问题。采用Kullback-Leibler散度损失以强制进行分布匹配:
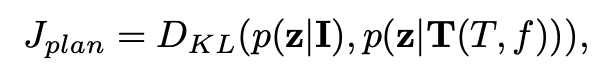
其中,DKL 表示 Kullback-Leibler 散度。GenAD框架的整体训练目标函数可以表述为:
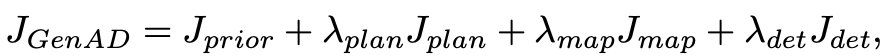
其中,λplan、λmap和λdet是平衡因子。提出的GenAD可以以高效的端到端方式进行训练。GenAD将端到端自动驾驶建模为一个生成问题,通过在结构化隐空间中进行未来预测和规划,考虑了现实轨迹的先验,从而产生高质量的轨迹预测和规划。
GenAD实验结果
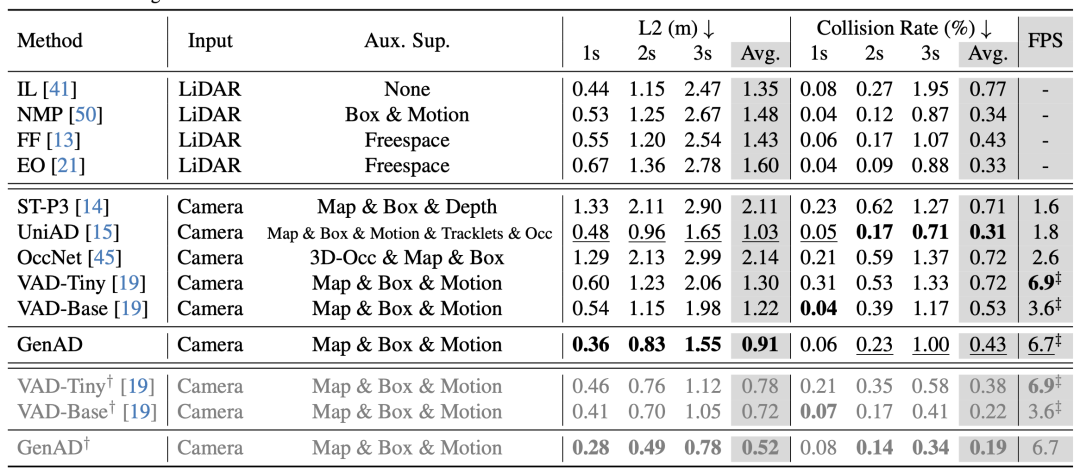
表1. 在nuScenes 验证集上与最先进的方法在运动规划性能方面的比较。
在表1中将GenAD与最先进的端到端自动驾驶方法进行了比较。可以看到,GenAD在所有方法中取得了最佳的L2误差,并且具有高效的推理速度。尽管UniAD 在碰撞率方面优于GenAD的方法,但它在训练过程中使用了额外的监督信号,如跟踪和占用信息,这些信息已经被验证为在避免碰撞方面至关重要的信息 。然而,这些在3D空间中的标签很难标注,使得使用更少的标签实现有竞争力的性能并不是一件轻松的事情。GenAD比UniAD更高效,展示了性能和速度之间的强大平衡。
GenAD可视化效果

可以看到,在包括直行、超车和转弯在内的各种场景中,GenAD产生了比VAD更好且更安全的轨迹。对于涉及多个agent的复杂交通场景的挑战性情境,GenAD仍然展现出良好的结果。
总结
本文提出了一个用于从视觉输入进行更好规划的生成式端到端自动驾驶(GenAD)框架。研究了传统的自动驾驶感知、预测和规划的串行设计,并提出了一个全新的生成式框架,以实现高阶自车-agent交互,并通过学习的结构先验生成更准确的未来轨迹。在广泛采用的nuScenes数据集上进行了大量实验证明了所提出的GenAD框架的规划性能处于领先水平。在未来,探索其他生成建模方法,如生成对抗网络或扩散模型,用于端到端自动驾驶将是一个有趣的方向。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2400人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









