



 文章探讨了CUDA编程中的共享内存优化,包括静态和动态共享内存的使用,以及如何通过避免银行冲突来提升矩阵乘法性能。作者还通过示例展示了银行冲突的创建与解决方法,以及推荐的行优先访问和数据对齐策略。
文章探讨了CUDA编程中的共享内存优化,包括静态和动态共享内存的使用,以及如何通过避免银行冲突来提升矩阵乘法性能。作者还通过示例展示了银行冲突的创建与解决方法,以及推荐的行优先访问和数据对齐策略。
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
论文作者 | EasonBob
0. 写在前面
共享内存是模型部署和加速很重要的一环,它决定了优化的效率到底能做到什么程度,主要分为动态和静态共享内存,下面将详细为大家介绍了共享内存及其源码,以及可能的冲突!
1. 共享内存
Input size is 4096 x 4096
matmul in gpu(warmup) uses 102.768669 ms
matmul in gpu(without shared memory)<<<256, 16>>> uses 101.848831 ms
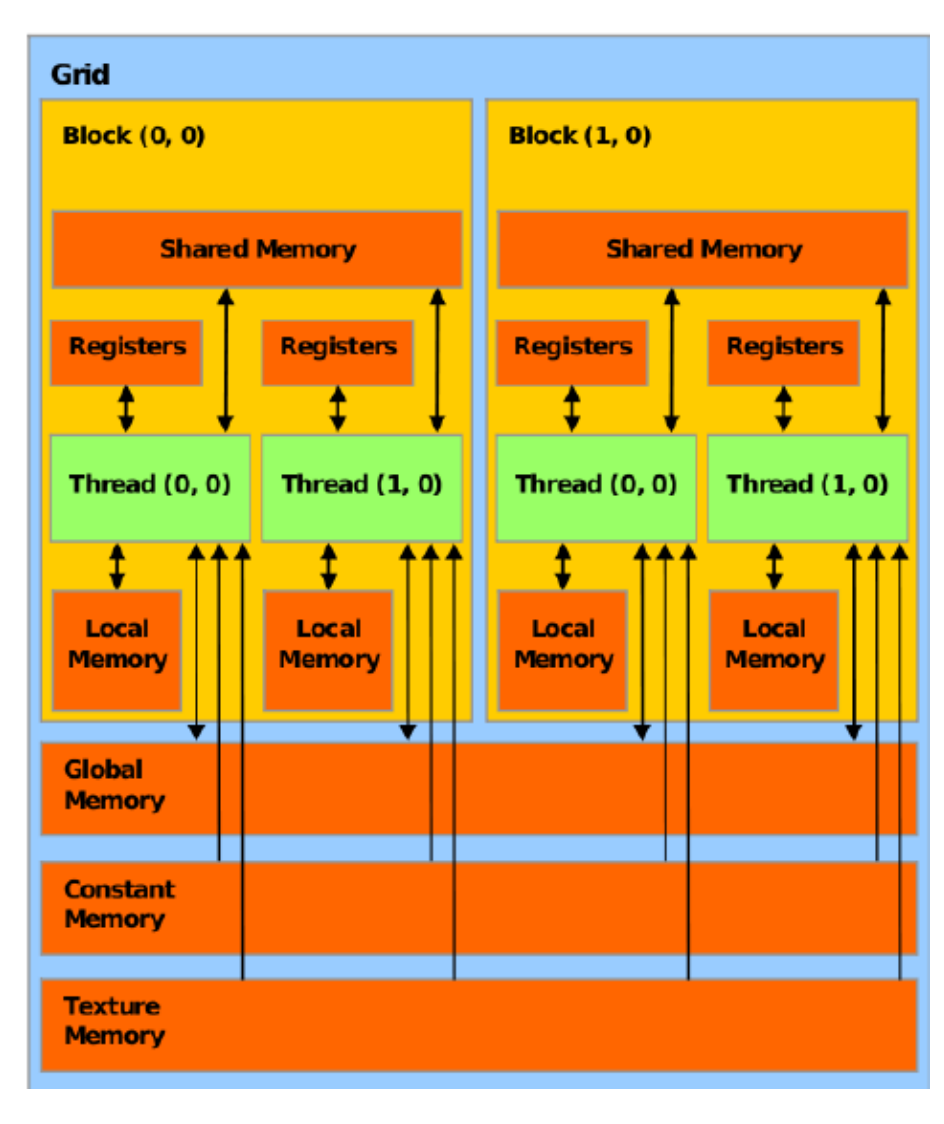
matmul in gpu(with shared memory(static))<<<256, 16>>> uses 63.545631 ms在之前的案例中, 我们把M, N两个矩阵通过cudaMalloc()开辟然后cudaMemcpy()把数据从Host搬到Device上, 这里其实用的是Global Memory, 从图上可以看到的是Global Memory其实很慢, 因为在图中离Threads越近, 他会有一个更高的带宽, 所以在CUDA编程中我们需要更多的去使用L1 Cache和Share Memory。共享内存是每个线程块(block)专用的。
1.1 MatmulSharedStaticKernel()
静态共享内存, 这里的设计是给每一个block设置跟线程数同等大小的共享内存, 最后的P_element跟之前一样还是把全部的block里面计算的都加起来, 这里的思想跟之前一样。唯一的区别就是每一个block访问的内存。
每一个block中, 线程先是从Global Memory(M_device, N_device)中拿到对应的内存去填上共享内存, 全部填完了(同步)之后再从共享内存依次取出来去做对应的计算。
__syncthreads(); 这个是跟共享内存绑定的, 这里出现两次, 第一次是每个线程块(block)中的线程首先将一小块(tile)的数据从全局内存(M_device 和 N_device)复制到共享内存。第二次是等待全部计算完成。
M的共享内存往右边遍历, 拿的是行, 这里可以想象成是为了拿到每一行, 也就是在y++的情况下怎么拿到每一行的每一个元素, 用tx和y
M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];M的共享内存往下边遍历, 拿的是列, 这里可以想象成是为了拿到每一列, 也就是在x++的情况下拿到每一列的元素, 用tx和y
N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];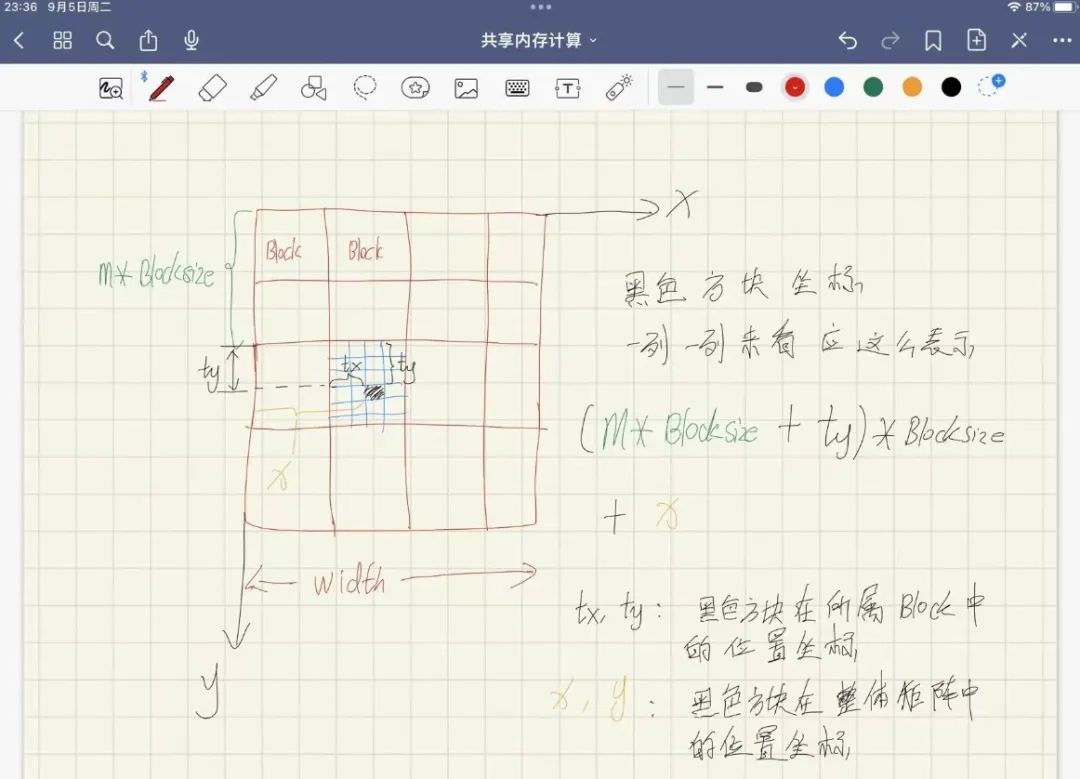
__global__ void MatmulSharedStaticKernel(float *M_device, float *N_device, float *P_device, int width){
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float P_element = 0.0;
// 这里出现的是block里面的索引, 因为共享内存是block专属的东西
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/
for (int m = 0; m < width / BLOCKSIZE; m ++) {
M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];
N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k ++) {
P_element += M_deviceShared[ty][k] * N_deviceShared[k][tx];
}
__syncthreads();
}
P_device[y * width + x] = P_element;
}P_device的结果是全部m加起来的结果
1.2 动态共享内存
一般没有什么特殊需求就不要用共享动态内存了,也未必见得会快多少 By 韩导
__global__ void MatmulSharedDynamicKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){
/*
声明动态共享变量的时候需要加extern,同时需要是一维的
注意这里有个坑, 不能够像这样定义:
__shared__ float M_deviceShared[];
__shared__ float N_deviceShared[];
因为在cuda中定义动态共享变量的话,无论定义多少个他们的地址都是一样的。
所以如果想要像上面这样使用的话,需要用两个指针分别指向shared memory的不同位置才行
*/
extern __shared__ float deviceShared[];
int stride = blockSize * blockSize;
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * blockSize + threadIdx.x;
int y = blockIdx.y * blockSize + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了 */
for (int m = 0; m < width / blockSize; m ++) {
deviceShared[ty * blockSize + tx] = M_device[y * width + (m * blockSize + tx)];
deviceShared[stride + (ty * blockSize + tx)] = N_device[(m * blockSize + ty)* width + x];
__syncthreads();
for (int k = 0; k < blockSize; k ++) {
P_element += deviceShared[ty * blockSize + k] * deviceShared[stride + (k * blockSize + tx)];
}
__syncthreads();
}
if (y < width && x < width) {
P_device[y * width + x] = P_element;
}
}2. Bank Conflict
使用共享内存的时候可能会遇到的问题
2.1 Bank Conflict
共享内存的Bank组织
共享内存被组织成若干bank(例如,32或64),每个bank可以在一个时钟周期内服务一个内存访问。因此,理想情况下,如果32个线程(一个warp)访问32个不同的bank中的32个不同的字(word),则所有这些访问可以在一个时钟周期内完成。
什么是Bank Conflict?
当多个线程在同一个时钟周期中访问同一个bank中的不同字时,就会发生bank conflict。这会导致访问被序列化,增加总的访问时间。例如,如果两个线程访问同一个bank中的两个不同字,则需要两个时钟周期来服务这两个访问。
如何避免Bank
避免bank conflict的一种策略是通过确保线程访问的内存地址分布在不同的bank上。这可以通过合理的数据布局和访问模式来实现。例如,在矩阵乘法中,可以通过使用共享内存的块来重新排列数据访问模式来减少bank conflicts。
总结 理解和避免bank conflicts是优化CUDA程序的一个重要方面,特别是当使用共享内存来存储频繁访问的数据时。你可以通过修改你的数据访问模式和数据结构来尽量减少bank conflicts,从而提高程序的性能。
2.2 案例
最简单的理解就是之前是[ty][tx] =====> [tx][ty] , 左图是bank conflict, 右图是解决bank conflict的分布
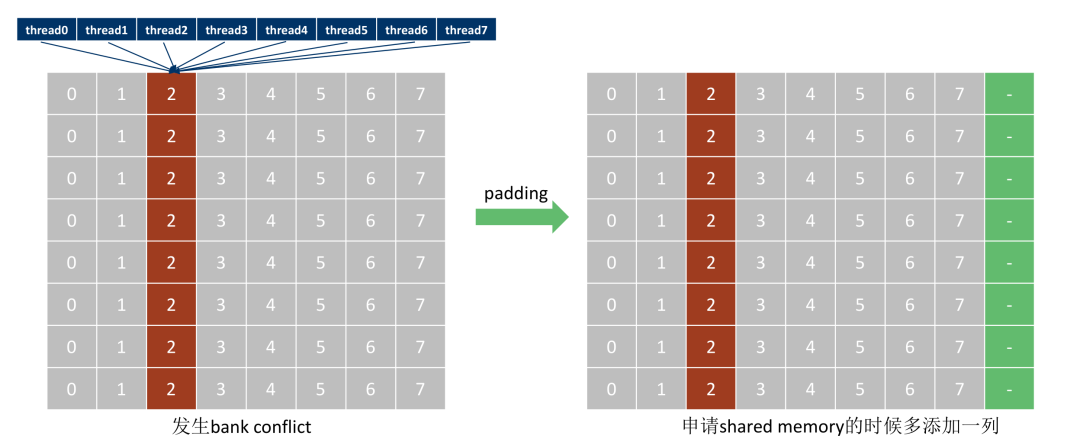
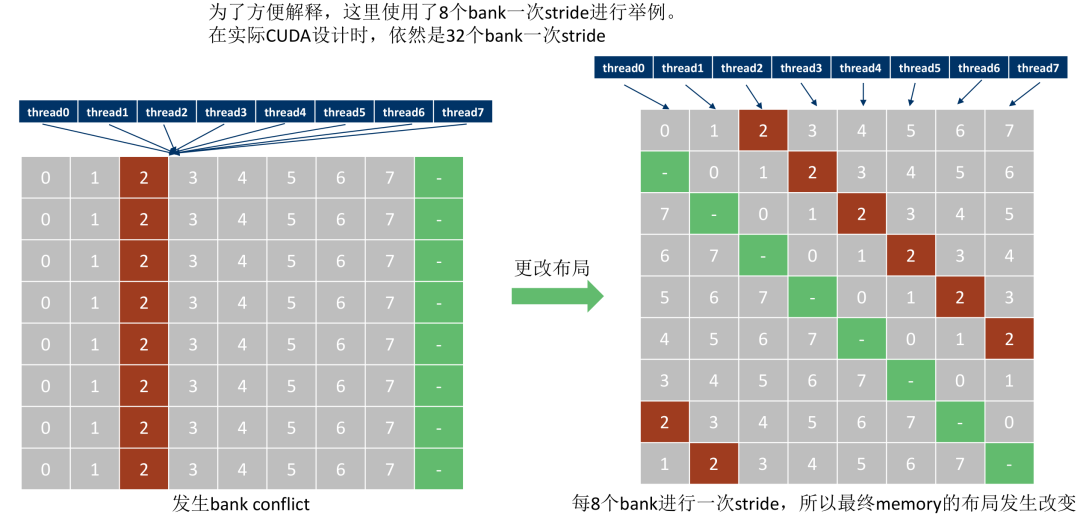
2.2.1 创造bank conflict
/*
使用shared memory把计算一个tile所需要的数据分块存储到访问速度快的memory中
*/
__global__ void MatmulSharedStaticConflictKernel(float *M_device, float *N_device, float *P_device, int width){
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/
for (int m = 0; m < width / BLOCKSIZE; m ++) {
/* 这里为了实现bank conflict, 把tx与tx的顺序颠倒,同时索引也改变了*/
M_deviceShared[tx][ty] = M_device[x * width + (m * BLOCKSIZE + ty)];
N_deviceShared[tx][ty] = M_device[(m * BLOCKSIZE + tx)* width + y];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k ++) {
P_element += M_deviceShared[tx][k] * N_deviceShared[k][ty];
}
__syncthreads();
}
/* 列优先 */
P_device[x * width + y] = P_element;
}2.2.2 用pad的方式解决bank conflict
__global__ void MatmulSharedStaticConflictPadKernel(float *M_device, float *N_device, float *P_device, int width){
/* 添加一个padding,可以防止bank conflict发生,结合图理解一下*/
__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];
__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];
/*
对于x和y, 根据blockID, tile大小和threadID进行索引
*/
int x = blockIdx.x * BLOCKSIZE + threadIdx.x;
int y = blockIdx.y * BLOCKSIZE + threadIdx.y;
float P_element = 0.0;
int ty = threadIdx.y;
int tx = threadIdx.x;
/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/
for (int m = 0; m < width / BLOCKSIZE; m ++) {
/* 这里为了实现bank conflict, 把tx与tx的顺序颠倒,同时索引也改变了*/
M_deviceShared[tx][ty] = M_device[x * width + (m * BLOCKSIZE + ty)];
N_deviceShared[tx][ty] = M_device[(m * BLOCKSIZE + tx)* width + y];
__syncthreads();
for (int k = 0; k < BLOCKSIZE; k ++) {
P_element += M_deviceShared[tx][k] * N_deviceShared[k][ty];
}
__syncthreads();
}
/* 列优先 */
P_device[x * width + y] = P_element;
}虽然说
Input size is 4096 x 4096
matmul in gpu(warmup) uses 113.364067 ms
matmul in gpu(general) uses 114.303902 ms
matmul in gpu(shared memory(static)) uses 73.318878 ms
matmul in gpu(shared memory(static, bank conf)) uses 141.755173 ms
matmul in gpu(shared memory(static, pad resolve bank conf)) uses 107.326782 ms
matmul in gpu(shared memory(dynamic)) uses 90.047234 ms
matmul in gpu(shared memory(dynamic, bank conf) uses 191.804550 ms
matmul in gpu(shared memory(dynamic, pad resolve bank conf)) uses 108.733856 ms在设计核函数时候通过选择合适的数据访问模式来避免bank conflicts是一种常用的优化策略。
在CUDA编程中,通常推荐的做法是:
行优先访问:因为CUDA的内存是按行优先顺序存储的,所以采用行优先访问可以更好地利用内存带宽,减少bank conflicts。
合适的数据对齐:通过确保数据结构的对齐也可以减少bank conflicts。例如,可以通过padding来确保矩阵的每行都是一个固定数量的word长。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









