



 本文深入解析GPU共享缓存中Bank Conflict的概念,阐述其对程序效率的影响,并解释在不同线程访问共享内存时如何避免冲突,以提升GPU运算性能。
本文深入解析GPU共享缓存中Bank Conflict的概念,阐述其对程序效率的影响,并解释在不同线程访问共享内存时如何避免冲突,以提升GPU运算性能。
一直不太理解GPU共享缓存中所谓的bank conflict是什么意思,知道今天对共享缓存操作时,发现简简单单的一句话:temp[tdx] = cach4[7];对程序的运行时间竟然有0.05ms的影响!!
是时候彻底弄清楚到底何谓bank conflict了。
对于有八个memory-bank 的GPU,共享内存的存储方式如表一中所述。目前计算能力大于2.0的GPU中,大多有16个memory-bank.
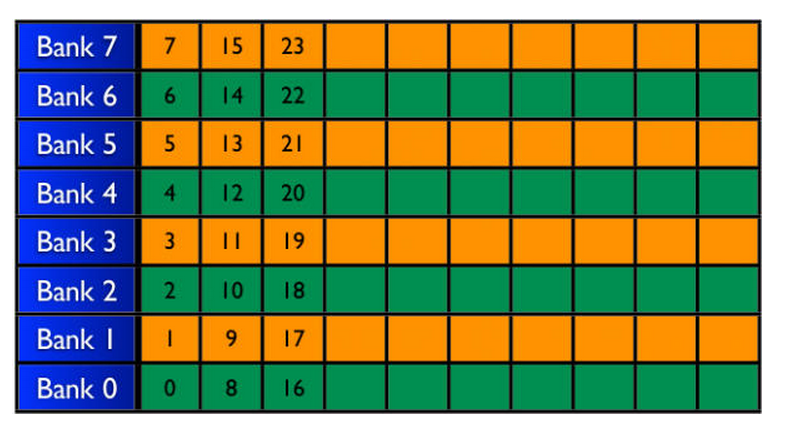
表一 Memory Bank Architecture
对于同一个wrap中的线程(一个wrap内包含了32个线程),访问共享存储器时,以half-wrap的形式分两次访问。
同一half-wrap内的线程同时可以访问不同的bank,而不同线程对同一个bank 的访问只能顺序进行。
所谓的bank-conflict,就是同一half-wrap内的线程,访问了同一bank里的共享内存。bank-conflict会让原本并行的对共享内存的访存操作变成串行从而极大的降低程序效率。
特殊情况是:half-wrap内所有的线程访问同一个共享内存中的同一地址,会产生一次广播,在这种情况下不会发生bank conflict

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









