



作者 | 科技猛兽 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/342675997
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
einops
通过灵活而强大的张量操作符为你提供易读并可靠的代码。支持 numpy、pytorch、tensorflow 等等。
大牛评价
Andrej Karpathy, AI at Tesla :用PyTorch和einops来写出更好的代码
<br/>Nasim Rahaman, MILA (Montreal) :einops正在缓慢而有力地渗入我代码的每一个角落和缝隙。如果你发现自己困扰于一堆高维的张量,这可能会改变你的生活。
本文介绍如何在你的代码中使用einops。
1 einops基础
转换张量维度,也许你曾经经常这样写:
y = x.transpose(0, 2, 3, 1)现在你可以这样写:
y = rearrange(x, 'b c h w -> b h w c')安装einops:
pip install einops作为示例,我们先load一些image:
ims = numpy.load('./resources/test_images.npy', allow_pickle=False)
# There are 6 images of shape 96x96 with 3 color channels packed into tensor
print(ims.shape, ims.dtype)(6, 96, 96, 3) float64
ims[0]
ims[1]
einops主要是rearrange, reduce, repeat这3个方法,下面介绍如何通过这3个方法如何来起到 stacking, reshape, transposition, squeeze/unsqueeze, repeat, tile, concatenate, view 以及各种reduction操作的效果):
from einops import rearrange, reduce, repeatrearrange:重新安排维度,通过下面几个例子验证用法:
rearrange(ims[0], 'h w c -> w h c')
rearrange(ims, 'b h w c -> (b h) w c')
# or compose a new dimension of batch and width
rearrange(ims, 'b h w c -> h (b w) c')
# length of newly composed axis is a product of components
# [6, 96, 96, 3] -> [96, (6 * 96), 3]
rearrange(ims, 'b h w c -> h (b w) c').shape(96, 576, 3)
# we can compose more than two axes.
# let's flatten 4d array into 1d, resulting array has as many elements as the original
rearrange(ims, 'b h w c -> (b h w c)').shape(165888,)
Decomposition of axis:
# decomposition is the inverse process - represent an axis as a combination of new axes
# several decompositions possible, so b1=2 is to decompose 6 to b1=2 and b2=3
rearrange(ims, '(b1 b2) h w c -> b1 b2 h w c ', b1=2).shape(2, 3, 96, 96, 3)
# finally, combine composition and decomposition:
rearrange(ims, '(b1 b2) h w c -> (b1 h) (b2 w) c ', b1=2)
# slightly different composition: b1 is merged with width, b2 with height
# ... so letters are ordered by w then by h
rearrange(ims, '(b1 b2) h w c -> (b2 h) (b1 w) c ', b1=2)
height变为2倍,width变为1半:
rearrange(ims, 'b h (w w2) c -> (h w2) (b w) c', w2=2)
rearrange(ims, 'b h w c -> h (b w) c')
# 与上例做个对比, leftmost digit is the most significant
rearrange(ims, 'b h w c -> h (w b) c')
# what if b1 and b2 are reordered before composing to width?
rearrange(ims, '(b1 b2) h w c -> h (b1 b2 w) c ', b1=2) # produces 'einops'
rearrange(ims, '(b1 b2) h w c -> h (b2 b1 w) c ', b1=2) # produces 'eoipns'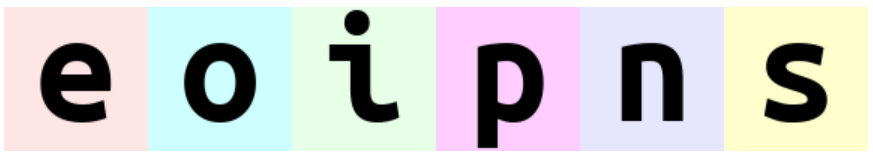
reduce:
之前写:
x.mean(-1)表示对张量的最后一维取平均值。
现在写:
reduce(x, 'b h w c -> b h w', 'mean')通过下面的例子验证用法:
# average over batch
reduce(ims, 'b h w c -> h w c', 'mean')
使用老方法应该这么写:
# the previous is identical to familiar:
ims.mean(axis=0)
# but is so much more readable
# besides mean, there are also min, max, sum, prod
reduce(ims, 'b h w c -> h w', 'min')
# this is mean-pooling with 2x2 kernel
# image is split into 2x2 patches, each patch is averaged
# 变小了
reduce(ims, 'b (h h2) (w w2) c -> h (b w) c', 'mean', h2=2, w2=2)
# yet another example. Can you compute result shape?
reduce(ims, '(b1 b2) h w c -> (b2 h) (b1 w)', 'mean', b1=2)
# rearrange can also take care of lists of arrays with the same shape
x = list(ims)
print(type(x), 'with', len(x), 'tensors of shape', x[0].shape)
# that's how we can stack inputs
# "list axis" becomes first ("b" in this case), and we left it there
rearrange(x, 'b h w c -> b h w c').shape(6, 96, 96, 3)
rearrange(x, 'b h w c -> h w c b').shape(96, 96, 3, 6)
numpy.array_equal(rearrange(x, 'b h w c -> h w c b'), numpy.stack(x, axis=3))True
# ... or we can concatenate
rearrange(x, 'b h w c -> h (b w) c').shape # numpy.stack(x, axis=3))(96, 576, 3)
numpy.array_equal(rearrange(x, 'b h w c -> h (b w) c'), numpy.concatenate(x, axis=1))True
Addition or removal of axes:
x = rearrange(ims, 'b h w c -> b 1 h w 1 c') # functionality of numpy.expand_dims
print(x.shape)
print(rearrange(x, 'b 1 h w 1 c -> b h w c').shape) # functionality of numpy.squeeze(6, 1, 96, 96, 1, 3)
(6, 96, 96, 3)
# compute max in each image individually, then show a difference
x = reduce(ims, 'b h w c -> b () () c', 'max') - ims
rearrange(x, 'b h w c -> h (b w) c')
# interweaving pixels of different pictures
# all letters are observable
rearrange(ims, '(b1 b2) h w c -> (h b1) (w b2) c ', b1=2)
# interweaving along vertical for couples of images
rearrange(ims, '(b1 b2) h w c -> (h b1) (b2 w) c', b1=2)
# disproportionate resize
reduce(ims, 'b (h 4) (w 3) c -> (h) (b w)', 'mean')
# interweaving lines for couples of images
# exercise: achieve the same result without einops in your favourite framework
reduce(ims, '(b1 b2) h w c -> h (b2 w) c', 'max', b1=2)
# spilt each image in two halves, compute mean of the two
reduce(ims, 'b (h1 h2) w c -> h2 (b w)', 'mean', h1=2)
# split in small patches and transpose each patch
rearrange(ims, 'b (h1 h2) (w1 w2) c -> (h1 w2) (b w1 h2) c', h2=8, w2=8)
rearrange(ims, '(b1 b2) (h1 h2) (w1 w2) c -> (h1 b1 h2) (w1 b2 w2) c', h1=3, w1=3, b2=3)
# pixelate: first downscale by averaging, then upscale back using the same pattern
averaged = reduce(ims, 'b (h h2) (w w2) c -> b h w c', 'mean', h2=6, w2=8)
repeat(averaged, 'b h w c -> (h h2) (b w w2) c', h2=6, w2=8)
rearrange(ims, 'b h w c -> w (b h) c')
2 einops用在PyTorch里面
到这里我们学习了einops操作你的张量,下面是告诉大家如何在深度学习中使用它:
from einops import rearrange, reduce
import numpy as np
x = np.random.RandomState(42).normal(size=[10, 32, 100, 200])
from utils import guess
# select one from 'chainer', 'gluon', 'tensorflow', 'pytorch'
flavour = 'pytorch'
print('selected {} backend'.format(flavour))
if flavour == 'tensorflow':
import tensorflow as tf
tape = tf.GradientTape(persistent=True)
tape.__enter__()
x = tf.Variable(x) + 0
elif flavour == 'pytorch':
import torch
x = torch.from_numpy(x)
x.requires_grad = True
elif flavour == 'chainer':
import chainer
x = chainer.Variable(x)
else:
assert flavour == 'gluon'
import mxnet as mx
mx.autograd.set_recording(True)
x = mx.nd.array(x, dtype=x.dtype)
x.attach_grad()
type(x), x.shape(torch.Tensor, torch.Size([10, 32, 100, 200]))
y = rearrange(x, 'b c h w -> b h w c')
guess(y.shape)(torch.Tensor, torch.Size([10, 100, 200, 32]))
反向传播:
y0 = x
y1 = reduce(y0, 'b c h w -> b c', 'max')
y2 = rearrange(y1, 'b c -> c b')
y3 = reduce(y2, 'c b -> ', 'sum')
if flavour == 'tensorflow':
print(reduce(tape.gradient(y3, x), 'b c h w -> ', 'sum'))
else:
y3.backward()
print(reduce(x.grad, 'b c h w -> ', 'sum'))tensor(320., dtype=torch.float64)
转化成numpy:
from einops import asnumpy
y3_numpy = asnumpy(y3)
print(type(y3_numpy), y3_numpy.shape)<class 'numpy.ndarray'> ()
y = rearrange(x, 'b c h w -> b (c h w)')
y.shape(torch.Tensor, torch.Size([10, 640000]))
y = rearrange(x, 'b c (h h1) (w w1) -> b (h1 w1 c) h w', h1=2, w1=2)
y.shape(torch.Tensor, torch.Size([10, 128, 50, 100]))
y = rearrange(x, 'b (c h1 w1) h w -> b c (h h1) (w w1)', h1=2, w1=2)
y.shape(torch.Tensor, torch.Size([10, 8, 200, 400]))
Reductions
Simple global average pooling:
y = reduce(x, 'b c h w -> b c', reduction='mean')
y.shape(torch.Tensor, torch.Size([10, 32]))
max-poolingwith a kernel 2x2:
y = reduce(x, 'b c (h h1) (w w1) -> b c h w', reduction='max', h1=2, w1=2)
y.shape(torch.Tensor, torch.Size([10, 32, 50, 100]))
1d, 2d and 3d pooling are defined in a similar way
for sequential 1-d models, you'll probably want pooling over time
reduce(x, '(t 2) b c -> t b c', reduction='max')reduce(x, 'b c (x 2) (y 2) (z 2) -> b c x y z', reduction='max')Squeeze and unsqueeze (expand_dims):
# models typically work only with batches,
# so to predict a single image ...
image = rearrange(x[0, :3], 'c h w -> h w c')
# ... create a dummy 1-element axis ...
y = rearrange(image, 'h w c -> () c h w')
# ... imagine you predicted this with a convolutional network for classification,
# we'll just flatten axes ...
predictions = rearrange(y, 'b c h w -> b (c h w)')
# ... finally, decompose (remove) dummy axis
predictions = rearrange(predictions, '() classes -> classes')per-channel mean-normalization foreach image:
y = x - reduce(x, 'b c h w -> b c 1 1', 'mean')
y.shape(torch.Tensor, torch.Size([10, 32, 100, 200]))
per-channel mean-normalization forwhole batch:
y = x - reduce(y, 'b c h w -> 1 c 1 1', 'mean')
y.shape(torch.Tensor, torch.Size([10, 32, 100, 200]))
Concatenation:
concatenate over the first dimension:
tensors = rearrange(list_of_tensors, 'b c h w -> (b h) w c')
tensors.shape(torch.Tensor, torch.Size([1000, 200, 32]))
Shuffling within a dimension:
channel shuffle:
y = rearrange(x, 'b (g1 g2 c) h w-> b (g2 g1 c) h w', g1=4, g2=4)
y.shape(torch.Tensor, torch.Size([10, 32, 100, 200]))
Split a dimension:
Example: when a network predicts several bboxes for each position
Assume we got 8 bboxes, 4 coordinates each. To get coordinated into 4 separate variables, you move corresponding dimension to front and unpack tuple.
bbox_x, bbox_y, bbox_w, bbox_h = \
rearrange(x, 'b (coord bbox) h w -> coord b bbox h w', coord=4, bbox=8)
# now you can operate on individual variables
max_bbox_area = reduce(bbox_w * bbox_h, 'b bbox h w -> b h w', 'max')
guess(bbox_x.shape)
guess(max_bbox_area.shape)(torch.Tensor, torch.Size([10, 8, 100, 200]))
(torch.Tensor, torch.Size([10, 100, 200]))
Striding anything:
Finally, how to convert any operation into a strided operation?
(like convolution with strides, aka dilated/atrous convolution)
# each image is split into subgrids, each is now a separate "image"
y = rearrange(x, 'b c (h hs) (w ws) -> (hs ws b) c h w', hs=2, ws=2)
y = convolve_2d(y)
# pack subgrids back to an image
y = rearrange(y, '(hs ws b) c h w -> b c (h hs) (w ws)', hs=2, ws=2)
assert y.shape == x.shapeLayers
For frameworks that prefer operating with layers, layers are available.
You'll need to import a proper one depending on your backend:
from einops.layers.torch import Rearrange, ReduceEinopslayers are identical to operations, and have same parameters.
(for the exception of first argument, which should be passed during call):
# example given for pytorch, but code in other frameworks is almost identical
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear, ReLU
from einops.layers.torch import Reduce
model = Sequential(
Conv2d(3, 6, kernel_size=5),
MaxPool2d(kernel_size=2),
Conv2d(6, 16, kernel_size=5),
# combined pooling and flattening in a single step
Reduce('b c (h 2) (w 2) -> b (c h w)', 'max'),
Linear(16*5*5, 120),
ReLU(),
Linear(120, 10),
)Restyling Gram matrix for style transfer:
主要是为了展示einsum的用法,现在求Gram matrix,我们分别看老版本的代码和einsum代码:
def gram_matrix_old(y):
(b, ch, h, w) = y.size()
features = y.view(b, ch, w * h)
features_t = features.transpose(1, 2)
gram = features.bmm(features_t) / (ch * h * w)
return gramdef gram_matrix_new(y):
b, ch, h, w = y.shape
return torch.einsum('bchw,bdhw->bcd', [y, y]) / (h * w)3 一些经典网络的code的变化:
3.1 Simple ConvNet:
老代码:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
conv_net_old = Net()新代码:
conv_net_new = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Dropout2d(),
Rearrange('b c h w -> b (c h w)'),
nn.Linear(320, 50),
nn.ReLU(),
nn.Dropout(),
nn.Linear(50, 10),
nn.LogSoftmax(dim=1)
)3.2 Channel shuffle (from shufflenet):
老代码:
def channel_shuffle_old(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
# transpose
# - contiguous() required if transpose() is used before view().
# See https://github.com/pytorch/pytorch/issues/764
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x新代码:
def channel_shuffle_new(x, groups):
return rearrange(x, 'b (c1 c2) h w -> b (c2 c1) h w', c1=groups)3.3 Simple attention:
老代码:
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
def forward(self, K, V, Q):
A = torch.bmm(K.transpose(1,2), Q) / np.sqrt(Q.shape[1])
A = F.softmax(A, 1)
R = torch.bmm(V, A)
return torch.cat((R, Q), dim=1)新代码:
def attention(K, V, Q):
_, n_channels, _ = K.shape
A = torch.einsum('bct,bcl->btl', [K, Q])
A = F.softmax(A * n_channels ** (-0.5), 1)
R = torch.einsum('bct,btl->bcl', [V, A])
return torch.cat((R, Q), dim=1)3.4 Transformer's attention needs more attention:
老代码:
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, mask=None):
attn = torch.bmm(q, k.transpose(1, 2))
attn = attn / self.temperature
if mask is not None:
attn = attn.masked_fill(mask, -np.inf)
attn = self.softmax(attn)
attn = self.dropout(attn)
output = torch.bmm(attn, v)
return output, attn
class MultiHeadAttentionOld(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k)
self.w_ks = nn.Linear(d_model, n_head * d_k)
self.w_vs = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.attention = ScaledDotProductAttention(temperature=np.power(d_k, 0.5))
self.layer_norm = nn.LayerNorm(d_model)
self.fc = nn.Linear(n_head * d_v, d_model)
nn.init.xavier_normal_(self.fc.weight)
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, _ = q.size()
sz_b, len_k, _ = k.size()
sz_b, len_v, _ = v.size()
residual = q
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
q = q.permute(2, 0, 1, 3).contiguous().view(-1, len_q, d_k) # (n*b) x lq x dk
k = k.permute(2, 0, 1, 3).contiguous().view(-1, len_k, d_k) # (n*b) x lk x dk
v = v.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v) # (n*b) x lv x dv
mask = mask.repeat(n_head, 1, 1) # (n*b) x .. x ..
output, attn = self.attention(q, k, v, mask=mask)
output = output.view(n_head, sz_b, len_q, d_v)
output = output.permute(1, 2, 0, 3).contiguous().view(sz_b, len_q, -1) # b x lq x (n*dv)
output = self.dropout(self.fc(output))
output = self.layer_norm(output + residual)
return output, attn新代码:
class MultiHeadAttentionNew(nn.Module):
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.w_qs = nn.Linear(d_model, n_head * d_k)
self.w_ks = nn.Linear(d_model, n_head * d_k)
self.w_vs = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.fc = nn.Linear(n_head * d_v, d_model)
nn.init.xavier_normal_(self.fc.weight)
self.dropout = nn.Dropout(p=dropout)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, q, k, v, mask=None):
residual = q
q = rearrange(self.w_qs(q), 'b l (head k) -> head b l k', head=self.n_head)
k = rearrange(self.w_ks(k), 'b t (head k) -> head b t k', head=self.n_head)
v = rearrange(self.w_vs(v), 'b t (head v) -> head b t v', head=self.n_head)
attn = torch.einsum('hblk,hbtk->hblt', [q, k]) / np.sqrt(q.shape[-1])
if mask is not None:
attn = attn.masked_fill(mask[None], -np.inf)
attn = torch.softmax(attn, dim=3)
output = torch.einsum('hblt,hbtv->hblv', [attn, v])
output = rearrange(output, 'head b l v -> b l (head v)')
output = self.dropout(self.fc(output))
output = self.layer_norm(output + residual)
return output, attn3.5 Self-attention GANs:
老代码:
class Self_Attn_Old(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn_Old,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention新代码:
class Self_Attn_New(nn.Module):
""" Self attention Layer"""
def __init__(self, in_dim):
super().__init__()
self.query_conv = nn.Conv2d(in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros([1]))
def forward(self, x):
proj_query = rearrange(self.query_conv(x), 'b c h w -> b (h w) c')
proj_key = rearrange(self.key_conv(x), 'b c h w -> b c (h w)')
proj_value = rearrange(self.value_conv(x), 'b c h w -> b (h w) c')
energy = torch.bmm(proj_query, proj_key)
attention = F.softmax(energy, dim=2)
out = torch.bmm(attention, proj_value)
out = x + self.gamma * rearrange(out, 'b (h w) c -> b c h w',
**parse_shape(x, 'b c h w'))
return out, attention注意Rearrange和Reduce的最后一个参数**axes_lengths,起一个确认长度的作用。
layer = Rearrange(pattern, **axes_lengths)
layer = Reduce(pattern, reduction, **axes_lengths)
# apply layer to tensor
x = layer(x)例:
y = rearrange(y, '(b z) c x y -> b c x y z', **parse_shape(x_5d, 'b c x y z'))parse_shape(x_5d, 'b c x y z'){'b': 10, 'c': 32, 'x': 100, 'y': 10, 'z': 20}
parse_shape(x_5d, 'batch c _ _ _'){'batch': 10, 'c': 32}
参考:
github.com/arogozhnikov/einops/blob/master/
http://einops.rocks/pytorch-examples.html
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 5343
5343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









