



作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【transformer综述】获取2022最新ViT综述论文!
导读
一个标准的 ViT 模型,训练时候的 Patch Size 是多大,它只能够在那个 Patch Size 的情况下取得良好的性能。当 Patch Size 改变时,一般模型就需要重新训练。为了克服这一限制,本文提出了一个可以适应所有 Patch Size 的 ViT 模型FlexiViT。
本文目录
1 FlexiViT:一个适应所有 Patch 大小的 ViT 模型
(来自谷歌,ViT,MLP-Mixer 作者团队)
1 FlexiViT 论文解读
1.1 背景和动机
1.2 标准 ViT 对于 Patch Size 灵活吗?
1.3 对于 Patch Size 更灵活的 FlexiViT 模型
1.4 如何改变 Patch Embedding 的尺寸?
1.5 与知识蒸馏的关系
1.6 FlexiViT 的内部表征
1.7 实验:使用预训练的 FlexiViT 模型
1 FlexiViT:一个适应所有 Patch 大小的 ViT 模型
论文名称:FlexiViT: One Model for All Patch Sizes
论文地址:
https://arxiv.org/pdf/2212.08013.pdf
1.1 背景和动机
视觉 Transformer (ViT) 和 CNN 模型不同的一点是对输入图片处理方式的不同:ViT 的处理方式是分块化 (Patchification) 将图像切割成不重叠的 Patches,并对这些 Patches 通过线性映射得到的 tokens 进行后续的运算。而 CNN 通过一些密集的,重叠的卷积来处理输入图片,使之转化成特征图。那么我们可以发现,ViT 这种与 CNN 完全不同的处理图片的范式解锁了新的功能。比如,我们可以随机丢弃一些不重要的 tokens 来提升模型的效率,额外增加一些 tokens 来适应新的任务,或者混合一些不同模态的 tokens。
尽管分块化对 ViT 模型很重要,但块的大小的作用却在之前的工作中很少受到关注。最初的 ViT 使用三种 Patch Size (32×32, 16×16 和 14×14 像素),但许多后续工作将 Patch Size 固定在 16×16。在这项工作中,作者提出 Patch Size 在不改变模型参数量的前提下,为模型的计算复杂度和预测性能提供了一个简单而有效的平衡。
比如,一个 ViT-B/8 模型在 156 GFLOPs 和 85 M 参数的情况下,在 ImageNet-1K 上的 Top-1 准确率为 85.6%,而一个 ViT-B/32模型在 8.6 GFLOPs 和 87 M 参数的情况下,在 ImageNet-1K 上的 Top-1 准确率仅仅为 79.1%。尽管在性能和计算复杂度方面存在巨大的差异,但是这些模型在本质上具有相同的参数。一个标准的 ViT 模型,训练时候的 Patch Size 是多大,它只能够在那个 Patch Size 的情况下取得良好的性能。当 Patch Size 改变时,一般模型就需要重新训练。
为了克服这一限制,本文提出 FlexiViT,希望在不增加成本的前提下,训练一个可以适应所有 Patch Size 的 ViT 模型。为了训练 FlexiViT,作者在训练过程中随机化 Patch Size,并对位置编码参数和 patch embedding 参数做 Resize 操作。这些简单的修改已经足以获得强大的性能,此外,作者借助 KD 获得更好的结果。
1.2 标准 ViT 对于 Patch Size 灵活吗?
给定一张输入图片 , 其中 分别是宽, 高和通道数, ViT 首先把输入图片切分成 个 大小的 Patches 。这一过程被称为分块化 (Patchification), 如下图1所示。序列长度 是分块化后的 Patch (或 tokens) 的数量, 并控制 ViT 的计算量。
接下来是计算 Patch Embeddings , 就是把每个 Patch 变成一个向量, 计算方法是:
, 其中, 是 Patch Embedding 的权重, 是计算 dot product, vec 是把多维张量向量化的过程。最后, 将学习到的位置编码 加到 Patch Embedding 上。然后, 将 作为输入传递给 Transformer。
总之,对于给定的图像大小 , Patch Size 决定了 Transformer 模型的输入序列的长度 : 较小的 Patch Size 对应较长的输入序列更有表现力的模型, 但是速度较慢。
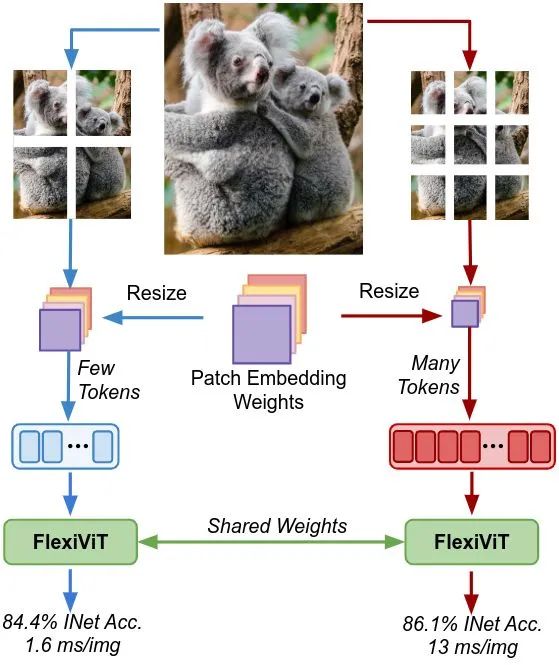
接下来作者表明,一个预训练好的标准 ViT 模型,在不同的 Patch Size 下会产生较差的性能,如下图2虚线所示。这里为了适配 Patch Size 大小的改变,作者简单地用双线性插值调整 Patch Embedding 权重 和位置编码 。
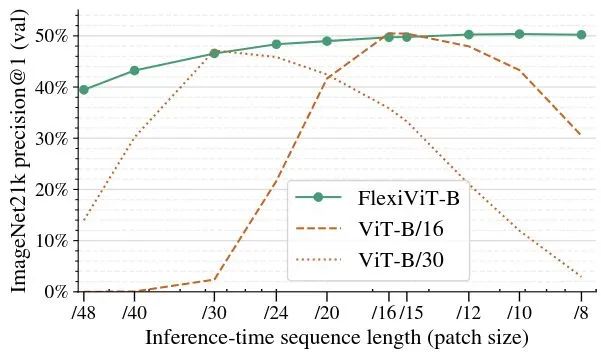
可以看到,标准 ViT 模型的性能随着 Patch Size 偏离预训练 Patch Size 的大小程度越大,ViT 性能的下降也越大。因此,标准 ViT 对于 Patch Size 是不灵活的,作者也因此开发了 FlexiViT,希望解决这个问题。
1.3 对于 Patch Size 更灵活的 FlexiViT 模型
如图2中的实线所示是 FlexiViT-B 模型的性能,可以看到性能与 ViT-B/16 和 ViT-B/30 接近,且当 Patch Size 是16和30除外的其他数时,性能均优于 ViT-B/16 和 ViT-B/30。FlexiViT-B 模型的训练方法与 ViT-B/16 和 ViT-B/30 一致,但是不同的是,在训练的每一步,Patch Size 的大小都是从一组预定义的 Patch Size 中均匀随机选择的。只需要对模型和训练的代码做以下2处修改即可。
第1处: 模型需要为 Patch Embedding 的权重参数 和位置编码 定义一个基本的 Shape,并在模型前进过程中动态调整大小。这个基本的 Shape 的具体大小并不重要,作者在所有实验中使用 32×32 的 Patch Embedding 的 7×7 的位置编码。
第2处: 为了做出各种各样的 Patch Size,作者使用了 240x240 的图像分辨率,也就是说,Patch Size 的大小可以是 {240,120,60,48,40,30,24,20,16,15,12,10,8,6,5,4,2,1},其中作者使用的 Patch Size 大小都在48和8之间。在每次迭代中,从这些 Patch Size 大小的均匀分布 中采样。
注意,改变 Patch Size 大小不等于改变图片分辨率的大小,这二者是完全不一样的两回事。Patch Size 大小纯粹是对模型的改变,而改变图像大小可能会大大减少可用信息。以上2处的改进,如下列算法所示。
model = ViT(...)
for batch in data:
ps = np.random.choice([8, 10, ..., 40, 48])
logits = model(batch["images"], (ps, ps))
# [...] backprop and optimize as usual
class ViT(nn.Module):
def __call__(self, image, patchhw):
# Patchify, flexibly:
w = self.param("w_emb", (32, 32, 3, d))
b = self.param("b_emb", d)
w = resize(w, (*patchhw, 3, d))
x = conv(image, w, strides=patchhw) + b
# Add flexible position embeddings:
pe = self.param("posemb", (7, 7, d))
pe = resize(pe, (*x.shape[1:3], d))
return TransformerEncoder(...)(x + pe)1.4 如何改变 Patch Embedding 的尺寸?
给定一个图片的 Patch , Patch Embedding 的权重是 。然后现在加入图片的 Patch Size 变为原来的2倍, 变为了 。那这时候, 如果用双线性插值来调整 Patch Embedding 的权重尺寸, 那就变成了:
可以看到, Patch Size 为 和 的情况下, Patch Embedding 结果的幅值差了4倍左右, 这也许就是标准 ViT 模型对于 Patch Size 不灵活的原因。
作者认为:理想情况下, Patch Size 调整大小的过程中没有信息丟失, 调整大小后的 与调整大小前的 应该保持相同。
然后,作者把双线性插值的过程等效为一次线性映射:

式中, 是任意输入, 是线性映射的参数, 直观地说, 我们的目的是要找到一组新的 Patch Embedding 权重 , 使得 Patch Size 调整大小的过程中没有信息丟失, 即满足下式:
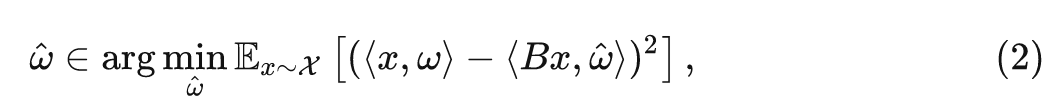
式中, 是 Patches 的分布, 在 Patch Size 增加的情况下, 即 时, 可以使用 , 其中 是 伪逆矩阵。
那么有了这样的一系列变换之后,Patch Size 调整大小的过程中就有:
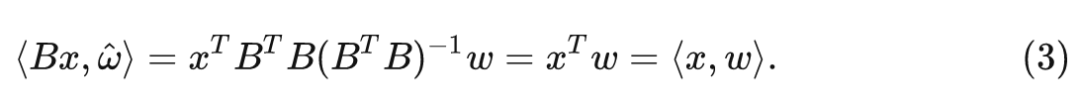
在 Patch Size 减小的情况下,式2可以重写成:
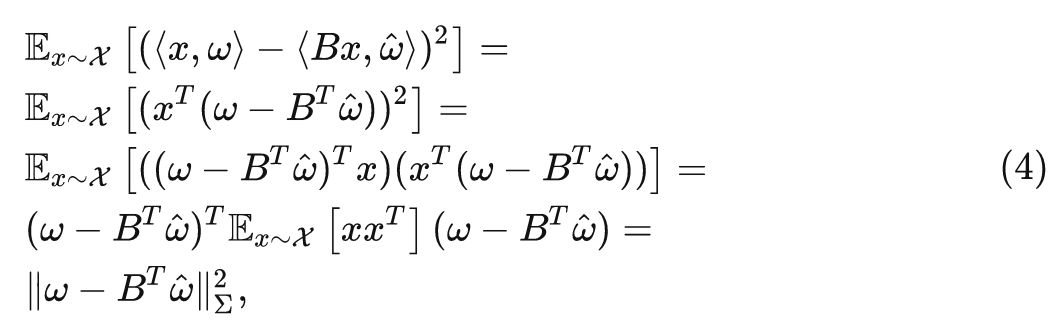
式中, , 其中 是 的 (非中心) 协方差矩阵。当 时有 。伪逆矩阵恢复了线性方程组的最小二乘解:
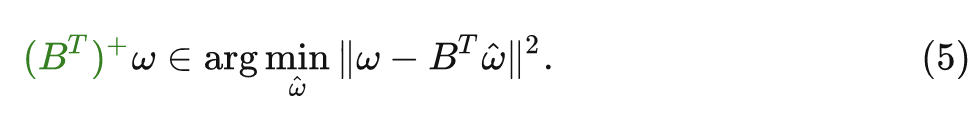
也可以推导出任意 的解析解。注意到 , 因此, 我们有:
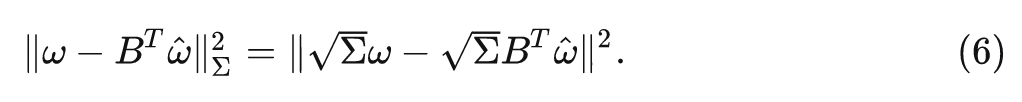
类似式4的推导,最优解是:
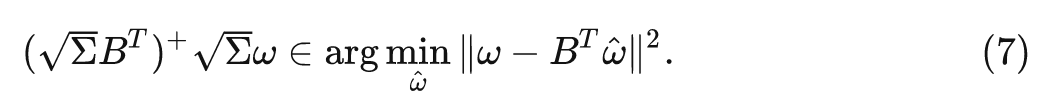
总而言之,可以将定义 PI-resize (伪逆 resize) 为:
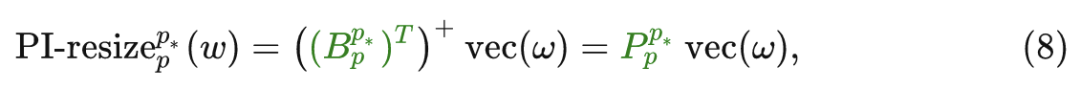
其中, 就是对应于 PI-resize 变换的矩阵, 只需要将它乘以 即可得到新的 Patch Embedding 权重。PI-resize 操作调整 Patch Embedding 权重的大小。
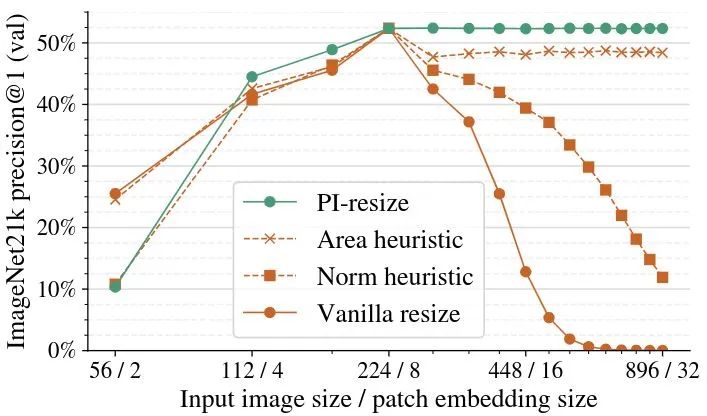
为了验证 PI-resize 的有效性, 作者将其与几种备选方法 (包括标准线性 resize) 进行比较, 结果如下图3所示。首先加载一个预训练的 ViT-B/8 模型, 并调整图像和 Patch Size 大小, 保持序列长度 不变。可以发现在下面的几种 resize 方法中, 只有 PI-resize 维持了性能。
1.5 与知识蒸馏的关系
知识蒸馏中,一个通常较小的学生模型被训练来模仿一个通常较大的教师模型的预测。与标准标签监督训练相比,这可以显著提高学生模型的性能。使用 FlexiViT,可以用一个强大的 ViT 教师的权重初始化一个学生 FlexiViT,并显著提高蒸馏性能。本文从 ViT-B/8 模型初始化并且蒸馏得到一个 FlexiViT-B 模型。在初始化时,作者使用 PI-resize 调整教师模型的 Patch Embedding 权重为 32×32,并双线性地重新采样其位置编码为 7×7。然后按照 FunMatch 方法训练学生模型,最小化教师和学生 FlexiViT 之间的 KL Divergence。
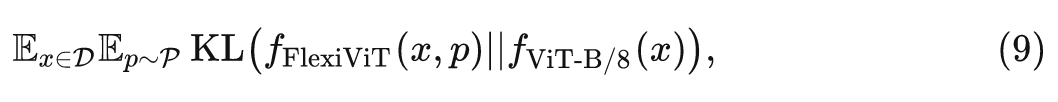
其中, 是 FlexiViT 模型在输入为 和 Patch Size 大小为 的上的分布, 是教师在完全相同输入上的预测分布, 是训练数据分布, 是 Patch Size 的分布。
1.6 FlexiViT 的内部表征
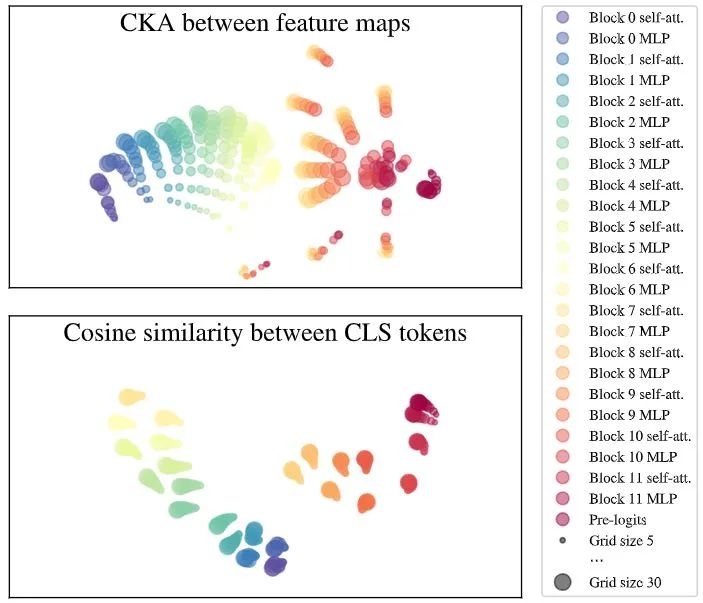
FlexiViT 有没有以与 ViT 相似的方式处理不同 Patch Size 的输入?
作者通过分析模型的内部表征来研究这个问题。作者应用了 Centered Kernel Alignment (CKA) 方法,这是一种广泛用于比较神经网络内部和跨模型表征的方法。可视化结果如下图3所示。从 Block1 到 Block 6 的 MLP 层,特征映射的表征相似。在 Block 6 的 MLP 层,开始发散,然后在最后一个 Block 再次收敛。
1.7 实验:使用预训练的 FlexiViT 模型
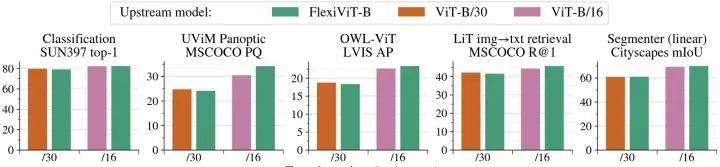
作者使用预训练的 FlexiViT 模型在下列迁移学习任务中验证 FlexiViT 的性能。实验结果如下图4所示。在不同的任务集中,FlexiViT 模型大致与两个固定 Patch Size 的 ViT 模型的性能相匹配,在大 Patch Size 时几乎不落后,在小 Patch Size 时有改进。这些结果证实,与针对不同 Patch Size 预训练多个 ViT 模型相比,使用预训练的 FlexiViT 没有明显的缺点。FlexiViT 提供了一种新的方式,使迁移学习更有效地利用资源,节省加速器内存和计算量。我们可以使用大的输入 Patch Size 进行廉价的迁移学习,但稍后使用小的 Patch Size 部署得到的模型,以获得不错的性能。
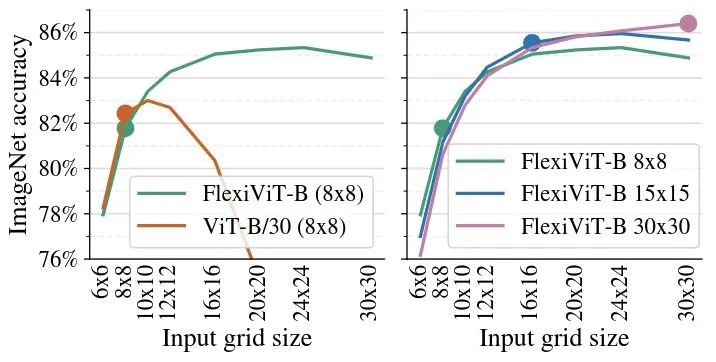
如下图5左侧所示,是微调 grid size 为8的 FlexiViT 模型,然后在其他 grid size 下评估的结果。标准 ViT 模型的精度很快就会下降,而 FlexiViT 随着网格尺寸的增加表现出极大的性能提升。
如下图5右侧所示,是一个 FlexiViT-B 模型在三种不同的 grid size 下进行了微调,并在不同的 grid size 下进行了评估。可以看到,无论FlexiViT-B 模型在哪种 grid size 下做微调,都能在更大的 grid size 下正常工作。比如,可以在 8×8 的 grid size 小下执行相对低计算代价的微调。当在 8×8 grid size 下评估时,模型达到 81.8% 的精度,但当在 24×24 grid size 下评估时,它达到 85.3% 的精度。
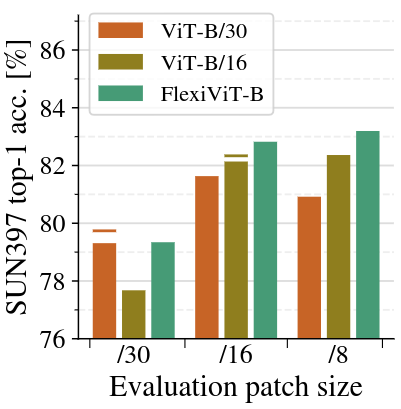
作者进一步表明,FlexiViT 的预训练模型在迁移到下游任务时也更加灵活。如下图6所示是 SUN397 数据集的实验结果。在迁移学习实验中,作者随机化 Patch Size 的大小,并在不同的 Patch Size 大小下评估单个模型。FlexiViT 的迁移效果最好。当 Patch Size 的大小发生变化时,FlexiViT 的灵活性最好。
如下图7所示,作者对 FlexiViT 的 attention 做了一些分析。可以观察到,attention relevance 在不同的 Patch Size 大小下会发生显著变化。随着 Patch Size 的减小,注意力会集中到更多的小区域。

总结
一个标准的 ViT 模型,训练时候的 Patch Size 是多大,它只能够在那个 Patch Size 的情况下取得良好的性能。当 Patch Size 改变时,一般模型就需要重新训练。为了克服这一限制,本文提出 FlexiViT,希望在不增加成本的前提下,训练一个可以适应所有 Patch Size 的 ViT 模型。为了训练 FlexiViT,作者在训练过程中随机化 Patch Size,并对位置编码参数和 patch embedding 参数做 Resize 操作。这些简单的修改已经足以获得强大的性能,此外,作者借助 KD 获得更好的结果。

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 3476
3476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









