



点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
1TuSimple
链接:https://github.com/TuSimple/tusimple-benchmark
道路上的对象可以分为两大类:静态对象和动态对象。车道标线是公路上的主要静态组成部分, 为了鼓励行业解决高速公路上的车道检测问题,图森发布了大约7000个1秒长的视频剪辑,每个视频剪辑20帧。
1)场景分布
良好和中等天气条件;
不同的白天;
2车道/3车道/4车道/或更多;
不同的交通条件;
2)数据集大小:
训练集:3626个video clips,3626个带注释的frame
测试集:2782个视频片段
3)图像抽取
1s抽取20帧;
2CULane
链接:https://xingangpan.github.io/projects/CULane.html

对于车道检测的学术研究而言,CULane是一个具有挑战性的大规模数据集。它是由安装在北京不同司机驾驶的六辆不同车辆上的摄像机采集的。收集了55个多小时的视频,提取了133235帧。数据示例如上所示。我们将数据集分为88880个训练样本、9675个验证集和34680个测试集。测试集分为正常和8个挑战类别,对应于上述9个示例。
对于每一帧,使用三次样条手动注释车道。对于车道标线被车辆遮挡或不可见的情况,我们仍然根据上下文注释车道,我们还希望算法能够区分道路上的障碍物。在这个数据集中,我们将注意力集中在四条车道标线的检测上,这是实际应用中最受关注的。其他车道标记未注释。
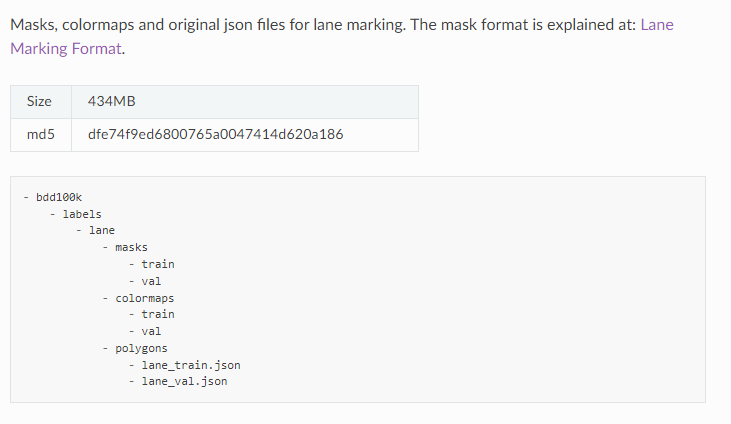
3BDD100k
链接:http://bdd-data.berkeley.edu/
车道标记对驾驶员来说是重要的道路指示。当GPS或地图没有精确的全球覆盖范围时,它们也是自动驾驶系统驾驶方向和定位的关键线索。根据车道标记对车道内车辆的指示,数据集将其分为两种类型。垂直车道标记(下图中用红色标记)表示沿其车道行驶方向的标记。平行车道标记(下图中用蓝色标记)表示车道内车辆停止的标志。我们还为标记提供了属性,如实线与虚线、双线与单线。
4Caltech
链接:http://www.mohamedaly.info/datasets/caltech-lanes
加州理工学院车道数据集包括在一天中不同时间在加州帕萨迪纳街道周围拍摄的四个片段。包括1225个单独的帧,这些帧是从安装在Alice上的摄像机上以及标记的通道上拍摄的。该数据集分为四个单独的剪辑:cordova1有250帧,cordova2有406帧,washington1有337帧,washington2有232帧。
5VPGNet
链接:https://github.com/SeokjuLee/VPGNet#vpgnet-dataset
VPGNet建立了一个车道和道路标记基准,该基准由大约20000张图像组成,其中17个车道和道路标记类,分别在四种不同场景下:无雨、下雨、大雨和夜间。
63D Lane Synthetic Dataset
链接:https://github.com/yuliangguo/3D_Lane_Synthetic_Dataset
这是一个合成数据集,用于3D车道检测方法的开发和评估,该数据集是Apollo合成数据集的扩展,详细可以参考论文:Gen-LaneNet: a generalized and scalable approach for 3D lane detection
7Jiqing Expressway
链接:https://github.com/vonsj0210/Multi-Lane-Detection-Dataset-with-Ground-Truth
该数据集是一个多车道检测数据集,可用于测试和评估多车道检测算法。数据集中有40个视频片段,每个视频片段持续3分钟,帧速率为30 fps,视频分辨率为1920×1080。共包括210610张不同照明强度和不同路况(上游、下坡、隧道、涵洞、坡道等)的道路图像。
8A Dataset for Lane Instance Segmentation in Urban Environments
链接:https://arxiv.org/abs/1807.01347
完整的注释集包括402个序列,共23979个图像,每个序列平均60个图像。总共有47497个车道实例被注释,即每个序列118.2个。
9DET
链接:https://spritea.github.io/DET/

车道提取是自动驾驶的一项基本而必要的任务。尽管过去几年中,深度学习模型在车道提取方面取得了重大进展,但它们都是针对基于帧的摄像机生成的普通RGB图像,这在本质上限制了它们的性能。为了解决这个问题,我们引入了动态视觉传感器(DVS),一种基于事件的传感器到车道提取任务,并建立了一个用于车道提取的高分辨率DVS数据集。我们收集原始事件数据并生成5424个基于事件的传感器图像,分辨率为1280x800,是目前所有DVS数据集中分辨率最高的。这些图像包括复杂的交通场景和各种车道类型。DET的所有图像均采用多类分割格式进行注释。完全注释的DET图像包含17103个车道实例,每个实例都手动逐像素标记。
10CurveLanes
链接:https://github.com/SoulmateB/CurveLanes
CurveLanes是一个新的基准车道检测数据集,具有150K车道图像,用于复杂场景,如车道检测中的曲线和多车道。它是在中国多个城市的真实城市和公路场景中收集的。它是迄今为止最大的车道检测数据集,为社区建立了更具挑战性的基准。
我们将整个数据集150K分为三个部分:训练:100K,val:20K和测试:30K。该数据集中大多数图像的分辨率为2650×1440。
对于每个图像,我们使用自然三次样条手动注释图像中的所有车道。仔细选择所有图像,使其中大多数图像至少包含一条曲线车道。在此数据集中可以找到更困难的场景,如S形曲线、Y形车道、夜间和多车道(车道线的数量超过4条)。
11Comma2k19 LD
链接:https://www.kaggle.com/datasets/tkm2261/comma2k19-ld
Comma2k19 LD数据集中,手动注释了2000帧的左右车道线(100种场景)。所选场景是从原始Comma2k19数据集中时速超过30英里(约48公里/小时)的场景中随机选择;

12OpenLane: 3D lane datasets
链接:https://github.com/OpenPerceptionX/OpenLane
OpenLane是迄今为止第一个真实世界和最大比例的3D lane数据集。我们的数据集从公共感知数据集Waymo Open数据集中收集有价值的内容,并为1000个段提供车道和最近路径对象(CIPO)注释。简言之,OpenLane拥有20万帧和超过88万条精心标注的车道。我们公开发布了OpenLane数据集,以帮助研究界在3D感知和自动驾驶技术方面取得进展。
13SDLane Dataset(CVPR 2022)
链接:https://www.42dot.ai/akit/dataset/
SDLane数据集是一种用于自动驾驶的新型车道标记数据集。我们提供1920 x 1208像素的高分辨率图像,捕捉高速公路和城市地区的挑战场景。该数据集由39K训练图像和4K测试图像组成,具有精确的地面真值标签。对于每个场景,我们手动注释道路上所有可见车道标记的2D车道几何体。此外,为了更好地推断ego车辆的位置,我们注释了每个车道相对于最左侧车道标记的索引。
14ONCE-3DLanes(CVPR 2022)
链接:https://once-3dlanes.github.io/3dlanes/
ONCE-3DLanes数据集是一个在三维空间中具有车道布局注释的真实自主驾驶数据集,是为刺激单目三维车道检测方法的发展而构建的新基准。
该数据集是从ONCE构建的,可以参考论文ONCE-3DLanes:Building Monocular 3D Lane Detection以了解数据集的构建细节。它收集在中国不同的地理位置,包括公路、桥梁、隧道、郊区和市中心,具有不同的天气条件(晴天/雨天)和照明条件(白天/夜晚)。
整个数据集包含211K个图像,在摄像机坐标中有相应的3D车道注释。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!

















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









