




文章目录
一、堆的定义
堆是一种特殊的完全二叉树,他满足在这个完全二叉树中,父亲节点一定大于等于它的孩子结点(这种情况称为大堆)或者父亲节点一定小于等于他的孩子结点(这种情况称为小堆)。
所谓完全二叉树,就是一种结点排布和满二叉树一样但是结点个数不一定一样的二叉树,除最后一层外,其他层数与满二叉树排布相同,最后一层结点从左往右排。
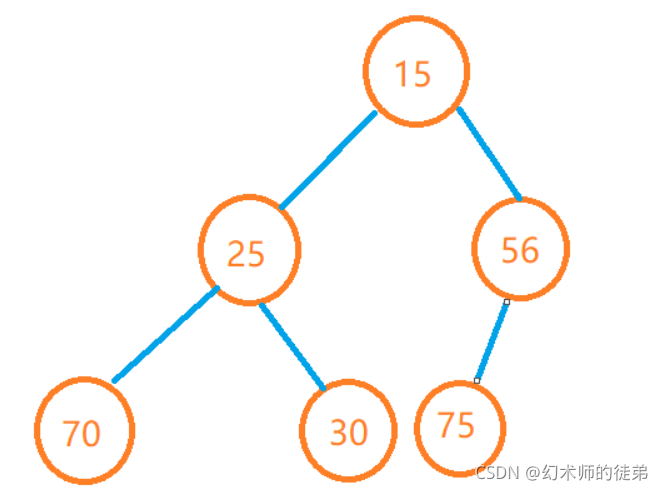
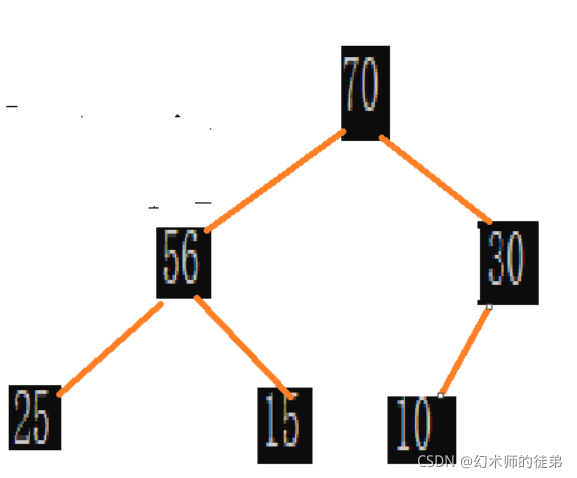
从堆的结构就可以看出,堆顶的元素一定是堆中元素里最大(大堆)或最小(小堆)的元素。
二、堆的实现
1.堆的存储结构
完全二叉树的特殊结构让我们可以用一个动态顺序表来存储它,并且观察到一个数组和一个完全二叉树可以这样建立起一个一对一的映射,对于一个数组大小为n的下标为i的节点,其双亲结点的下标和孩子结点的下标可以这样表示:
p
a
r
e
n
t
=
i
−
1
2
,
i
f
(
0
≤
p
a
r
e
n
t
)
l
e
f
t
c
h
i
l
d
=
2
∗
i
+
1
,
i
f
(
l
e
f
t
c
h
i
l
d
≤
n
−
1
)
r
i
g
h
t
c
h
i
l
d
=
2
∗
i
+
2
,
i
f
(
r
i
g
h
t
c
h
i
l
d
≤
n
−
1
)
parent = \frac{i-1}{2},if(0\leq parent)\\ leftchild = 2*i+1,if(leftchild\leq n-1)\\ rightchild = 2*i+2,if(rightchild\leq n-1)
parent=2i−1,if(0≤parent)leftchild=2∗i+1,if(leftchild≤n−1)rightchild=2∗i+2,if(rightchild≤n−1)
typedef struct Heap {
int* a;
int size;
int capacity;
}Heap;
2.堆的初始化、销毁、打印、判空、返回堆顶元素
这些都是在顺序表中就讲过很多次的东西了,就不赘述了。
void HeapInit(Heap* hp)
{
assert(hp);
hp->a = NULL;
hp->size = hp->capacity = 0;
}
void Heapdestroy(Heap* hp)
{
assert(hp);
free(hp->a);
hp->capacity = hp->size = 0;
hp->a = NULL;
}
void HeapPrint(Heap* hp)
{
assert(hp);
for (int i = 0; i < hp->size; i++)
{
printf("%d ", hp->a[i]);
}
printf("\n");
}
bool HeapEmpty(Heap* hp)
{
return hp->size == 0;
}
int HeapSize(Heap* hp)
{
return hp->size;
}
int HeapTop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->a[0];
}
为了引出创建堆的两种核心算法:向上调整算法和向下调整算法,我们先介绍一下堆的插入和删除。
3.堆的插入
假定我们已经有了一个堆,如果要在堆中插入元素,首先位置上肯定是插入在数组的结尾,但是插入以后不一定还满足堆结构了,这种情况下我们需要仔细分析一下。
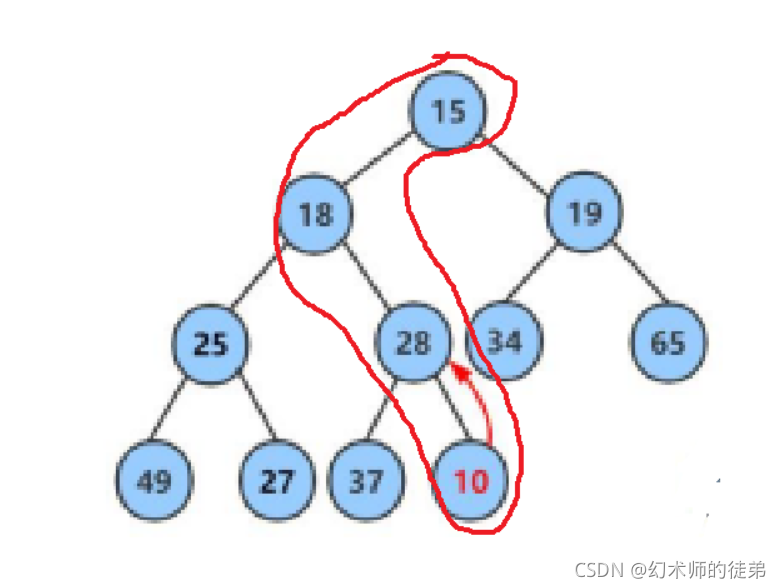
发现每次插入只会影响当前节点到根节点路径上的节点,不会影响其他节点,以大堆为例,其他节点的值满足大堆的性质,一定是父节点大于子结点,你就把根节点调整了,根节点也只会是更大的,其他节点的堆关系不会变。
根据这点性质我们可以设计一个向上调整算法,每次都去比较当前节点与其双亲结点(如果存在的话),以小堆为例,如果当前结点小于双亲结点,则交换当前结点与双亲结点的值,然后看新的当前结点与双亲结点,直到当前结点大于双亲结点或当前结点已经是根节点的情况下退出。
void swap(HPDataType* x, HPDataType* y)
{
assert(x && y);
HPDataType tmp = *x;
*x = *y;
*y = tmp;
}
//自child处向上调整
//最坏情况调整层数次,O(logn)
void AdjustUp(HPDataType* a, int n, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)
{
int newcapacity = hp->capacity == 0 ? 4 : 2 * hp->capacity;
HPDataType* tmp = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
printf("ralloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
AdjustUp(hp->a, hp->size, hp->size - 1);
}
这里向上调整算法有个好玩的地方,如果我们把while循环条件换成:
while (parent >= 0)
//显然这样设计是想当child=0时parent = (0-1)/2<0跳出去
这样就错了,但又没完全错,因为最后一次child=0后由于取整的机制,parent=(0-1)/2=0,还是等于0,并没有像预料中小于0,
那既然如此怎么出去的呢?此时因为parent == child ==0 所以a[parent] == a[child],会走else出去。
这种情况就好像下图,你说是设计的巧妙吧,好像也不是,但你说设计错了吧,但是人家效果和正确代码是一样的。

堆的插入最多要调整层数次,所以时间复杂度是O(logn)
4.移除堆顶元素
移除堆顶元素的方法比较巧妙,首先我们使堆顶元素和当前堆中最后一个元素进行交换,然后堆的大小-1以移除最后一个元素,然后此时堆的特性被破坏了,需要调整。
这里需要一个向下调整算法,以大堆为例,把堆顶元素与它较小的孩子交换,然后再接着往下走,直到没有孩子了或他比他的孩子中的较小者大的时候,跳出循环。
//最坏情况要调整层数次 O(logn)
void AdjustDown(int* a, int n, int parent)
{
assert(a);
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child+1] > a[child])
{
child++;
}
if (a[child] > a[parent])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
swap(&hp->a[0], &hp->a[hp->size - 1]);
hp->size--;
AdjustDown(hp->a, hp->size, 0);
}
移除堆顶元素也是同理,最多向下调整,循环层数次,时间复杂度也是O(logn).
5.创建堆的两种算法
我们已经有了向上调整算法和向下调整算法:
void AdjustUp(HPDataType* a, int n, int child);
//向上调整
//需要调整的存储堆的数组a,数组的大小n,调整开始的位置的下标child
void AdjustDown(int* a, int n, int parent);//n是数组大小
//向下调整 调整开始的位置parent
如果真的要创建堆的话,最简单的方法当然是把数组元素不断地插入堆就可以了,但是这种思路空间复杂度是O(N),我们想就控制一个数组,不创建额外的数组,也就是说在空间复杂度O(1)的情况下控制数组使其变成堆的结构。
思路1:利用向上调整算法
总体思路就是一直控制当前数组中元素满足堆的性质,也就是从第二个元素开始不断进行向上调整算法,一直到第n个元素,这里利用了一种假插入的思想,从第二个元素开始进行向上调整算法其实就是把第二个元素、第三个元素…第n个元素插入堆中,只不过其实他们已经在数组里了。
//把a构建成堆 数组a的大小是n
//方法1
//利用插入的思想 相当于每次在叶子结点插入一个 然后向上调整
for (int i = 1; i < n; i++)
{
AdjustUp(a, n, i);
}
void createHeap(Heap* hp, int* a, int n)
{
assert(hp);
assert(a);
for (hp->size = 0; hp->size < n; hp->size++)
{
if (hp->size == hp->capacity)
{
int newcapacity = hp->capacity == 0 ? 4 : 2 * hp->capacity;
HPDataType* tmp = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
printf("ralloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = a[hp->size];
}
for (int i = 1; i < n; i++)
{
AdjustUp(hp->a, n, i);
}
}
思路2:利用向下调整算法
注意到如果我们对第一个非叶子结点进行向下调整算法,以这个非叶子结点为根节点的完全二叉树会满足堆的性质,那我们可以这样从第一个非叶子结点开始,对它进行向下调整算法,一直调整到根节点。这个过程就相当于不断地在增加堆顶元素,然后向下调整使得子堆满足堆的性质。
注意到第一个非叶子结点就是数组最后一个元素的双亲,即:
n
−
1
−
1
2
\frac{n-1-1}{2}
2n−1−1
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
void createHeap(Heap* hp, int* a, int n)
{
assert(hp);
assert(a);
for (hp->size = 0; hp->size < n; hp->size++)
{
if (hp->size == hp->capacity)
{
int newcapacity = hp->capacity == 0 ? 4 : 2 * hp->capacity;
HPDataType* tmp = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
printf("ralloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = a[hp->size];
}
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(hp->a, n, i);
}
}
6.创建堆的时间复杂度的分析
向上调整创建堆
for (int i = 1; i < n; i++)
{
AdjustUp(a, n, i);
}
你可能会觉得这不就是外循环n次,循环内部向上调整时间复杂度是O(logn),所以时间复杂度是O(nlogn)吗,这样的话,你就忽略了一点情况,我们不是每个元素都是从堆底向上调整的。
以向上调整为例,我们是进行了假插入,第二个元素在堆的第二层,最多只需要调整1次,第三个元素还在第二层,最多也只需要调整一次,第四个元素在第三层,最多需要调整两次,第五个元素在第三层,最多需要调整两次,第六个元素也在第三层,最多需要调整两次,第七个元素也在第六层,最多也需要调整两次,第八个元素在第四层,最多需要调整3次。。。
为了估算起来方便,我们考虑堆是一个n个结点h层的完全二叉树,
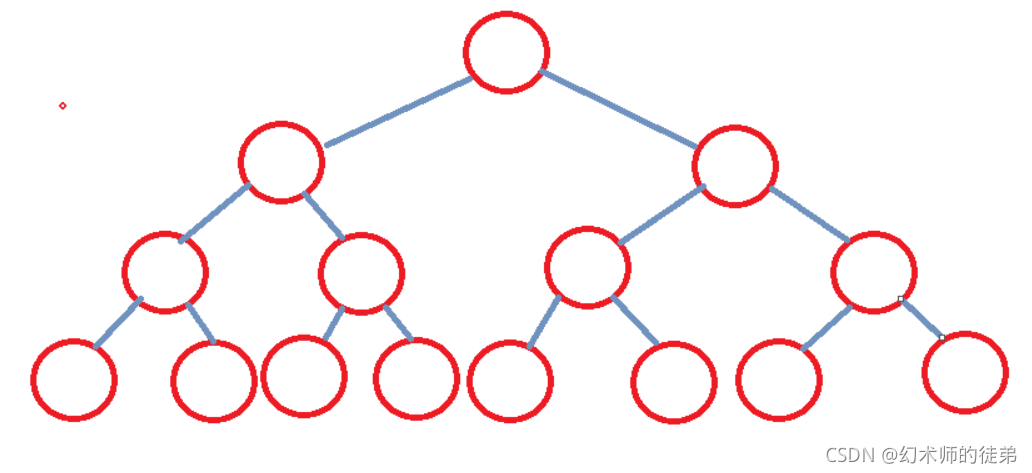
- 第2层的2^1个元素要向上移动1层
- 第3层的2^2个元素要向上移动2层
- 第4层的2^3个元素要向上移动3层
…
- 第h层的2^(h-1)个元素要向上移动h-1层
T ( n ) = 1 ∗ 2 1 + 2 ∗ 2 2 + 3 ∗ 2 3 + . . . + ( h − 1 ) ∗ 2 h − 1 T(n)=1*2^{1}+2*2^{2}+3*2^{3}+...+(h-1)*2^{h-1}\\ T(n)=1∗21+2∗22+3∗23+...+(h−1)∗2h−1
进行一个错位相减法,有:
2
T
(
n
)
=
1
∗
2
2
+
2
∗
2
3
+
.
.
.
+
(
h
−
2
)
∗
2
h
−
1
+
(
h
−
1
)
∗
2
h
−
T
(
n
)
=
2
1
+
2
2
+
.
.
.
+
2
h
−
1
−
(
h
−
1
)
∗
2
h
=
2
h
−
2
−
(
h
−
1
)
2
h
T
(
n
)
=
(
h
−
2
)
2
h
−
2
=
(
l
o
g
2
(
n
+
1
)
−
2
)
(
n
+
1
)
−
2
T
(
n
)
−
>
O
(
n
l
o
g
n
)
2T(n)=1*2^2+2*2^3+...+(h-2)*2^{h-1}+(h-1)*2^{h}\\ -T(n)=2^1+2^2+...+2^{h-1}-(h-1)*2^{h}\\=2^h-2-(h-1)2^h\\ T(n)=(h-2)2^h-2=(log_{2}(n+1)-2)(n+1)-2\\ T(n)->O(nlogn)
2T(n)=1∗22+2∗23+...+(h−2)∗2h−1+(h−1)∗2h−T(n)=21+22+...+2h−1−(h−1)∗2h=2h−2−(h−1)2hT(n)=(h−2)2h−2=(log2(n+1)−2)(n+1)−2T(n)−>O(nlogn)
看到这里是不是觉得倒腾了半天时间复杂度这不就是O(nlogn)嘛,别急,好戏才刚刚开始。
对于向下调整,情况有所不同。
- 第一层,2^0个元素,向下移动h-1层
- 第二层,2^1个元素,向下移动h-2层
- …
- 第h-1层,2^(h-2)个元素,向下移动1层
T ( n ) = ( h − 1 ) ∗ 2 0 + ( h − 2 ) ∗ 2 1 + ( h − 3 ) ∗ 2 2 + . . . + 1 ∗ 2 h − 2 T(n)=(h-1)*2^{0}+(h-2)*2^{1}+(h-3)*2^{2}+...+1*2^{h-2} T(n)=(h−1)∗20+(h−2)∗21+(h−3)∗22+...+1∗2h−2
进行一个错位相减法:
2
T
(
n
)
=
(
h
−
1
)
2
1
+
(
h
−
2
)
2
2
+
.
.
.
+
2
∗
2
h
−
2
+
1
∗
2
h
−
1
T
(
n
)
=
2
1
+
2
2
+
.
.
.
+
2
h
−
2
+
2
h
−
1
−
h
+
2
0
T
(
n
)
=
2
h
−
1
−
h
由
n
=
2
h
−
1
有
T
(
n
)
=
n
−
l
o
g
2
(
n
+
1
)
T
(
n
)
−
>
O
(
n
)
2T(n)=(h-1)2^1+(h-2)2^2+...+2*2^{h-2}+1*2^{h-1}\\ T(n)=2^1+2^2+...+2^{h-2}+2^{h-1}-h+2^0\\ T(n)=2^h-1-h\\ 由n=2^h-1有\\ T(n)=n-log_{2}(n+1)\\ T(n)->O(n)
2T(n)=(h−1)21+(h−2)22+...+2∗2h−2+1∗2h−1T(n)=21+22+...+2h−2+2h−1−h+20T(n)=2h−1−h由n=2h−1有T(n)=n−log2(n+1)T(n)−>O(n)
所以创建堆最好用向下调整思路来创建堆,时间复杂度是O(n).
三、TOPK问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。 比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
抽象出来就是在N个数中找出最大的前k个.
思路1:排序(O(NlogN))然后取出前k个,时间复杂度O(NLogN)
思路2:创建一个N个元素的堆,然后pop k次,建堆时间复杂度O(N),POPk次时间复杂度O(klogN),总时间复杂度O(N+klogN)
但是有一个问题,通常情况下N很大,内存中存不下这些数,它们存在文件中,排序也无法排除最大的前k个了,因为可能最大的前k个不在你能内存能装的数中,所以思路1和思路2都不能用了,因为这些数据不能完整的读取到内存中。
思路3,:
- 用前k个数建立一个k个数的小堆。
- 把后续的N-K个数据依次与堆顶元素比较,如果比堆顶元素大,就替换堆顶,然后向下调整。
- 堆中的k个数就是前100个较大的数。(你堆外的元素肯定比堆顶的元素还要小,由此就选出了前k个大数。)
时间复杂度O(k+(N-k)logk)~O(N),效率也不错。
void PrintTopK(int* a, int n, int k)
{
Heap hp;
HeapInit(&hp);
createHeap(&hp, a, k);
for (int i = k; i < n; i++)
{
if (a[i] > HeapTop(&hp))
{
//只调用接口
HeapPop(&hp);
HeapPush(&hp, a[i]);
//直接访问结构体
//hp.a[0] = a[i];
//AdjustDown(hp.a, hp.size, 0);
}
}
HeapPrint(&hp);
Heapdestroy(&hp);
}
void TestTopk()
{
int n = 1000000;
int* a = (int*)malloc(sizeof(int) * n);
srand(time(0));
for (size_t i = 0; i < n; ++i)
{
a[i] = rand() % 1000000;
}
//设置10个比1000000大的
a[5] = 1000000 + 1;
a[1231] = 1000000 + 2;
a[531] = 1000000 + 3;
a[5121] = 1000000 + 4;
a[115] = 1000000 + 5;
a[2335] = 1000000 + 6;
a[9999] = 1000000 + 7;
a[76] = 1000000 + 8;
a[423] = 1000000 + 9;
a[3144] = 1000000 + 10;
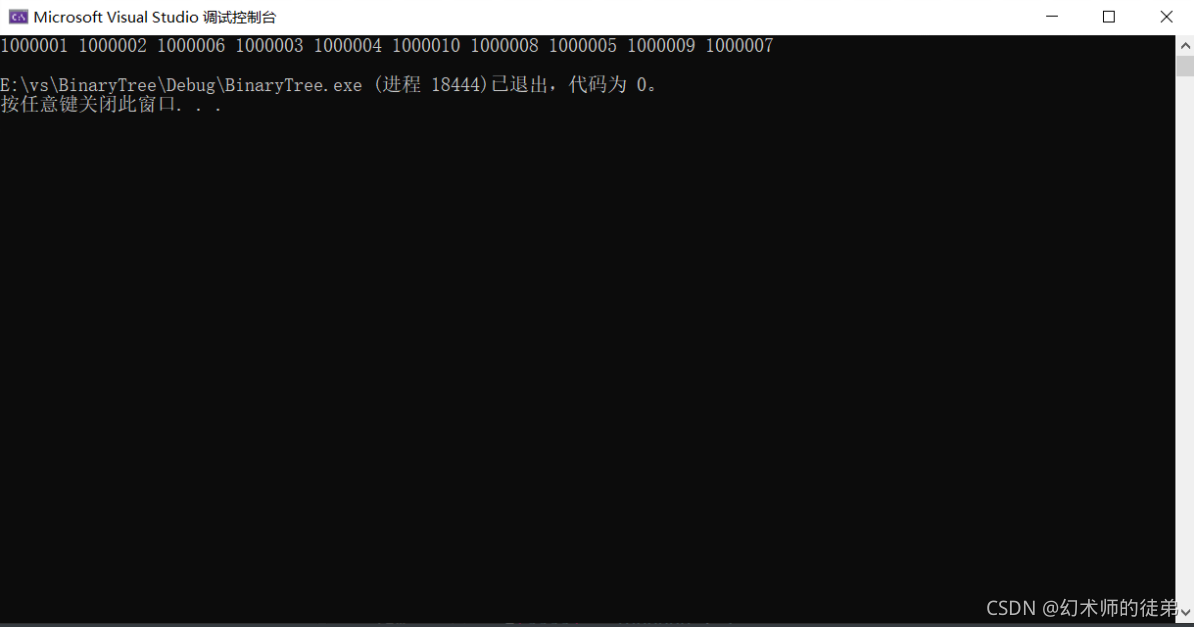
PrintTopK(a, n, 10);
}
四、堆排序
如果对空间复杂度没有要求,那真是太简单了,就建个堆,然后让数组入堆,然后popn次就行,但是这样空间复杂度是O(N)。
但是如果我限制上空间复杂度只能是O(1)呢,这样我们要自己操作数组,利用我们在创建堆中提到的算法,用向下调整算法,因为它的时间复杂度要低一些。
以升序为例,我们究竟要创建大堆还是小堆呢,这里是不能建小堆的,因为这样的话第一个元素确实是最小的了,但是这样其他元素要重新建堆,不然堆之间的父子关系都已经被破坏了(想想下标),下重新建小堆的时间复杂度是:
O
(
n
)
+
O
(
n
−
1
)
+
.
.
.
O
(
1
)
=
O
(
n
2
)
O(n)+O(n-1)+...O(1) = O(n^{2})
O(n)+O(n−1)+...O(1)=O(n2)
那这样我为什么不循环一次找到最小的呢,这样用堆完全没有体现出用堆的优势。
所以堆排序排升序建立大堆,排降序建立小堆。实现思路如下(以升序为例):
- 建大堆,第一个元素是最大的元素,把最后一个元素和第一个元素交换。
- 最后一个元素已经是最大的元素了,仿照冒泡排序,它不需要再排了,只要不把它当做堆内的元素(也就是把堆的元素个数看做是n-1),堆这时的堆顶进行一个向下调整,再次建出一个大堆,然后再换。
void HeapSort(int* a, int n)
{
assert(a);
if (n == 1)
return;
//建堆 O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//O(NlogN)
for (int i = n - 1; i > 0; i--)
{
swap(&a[0], &a[i]);
AdjustDown(a, i, 0);
}
}
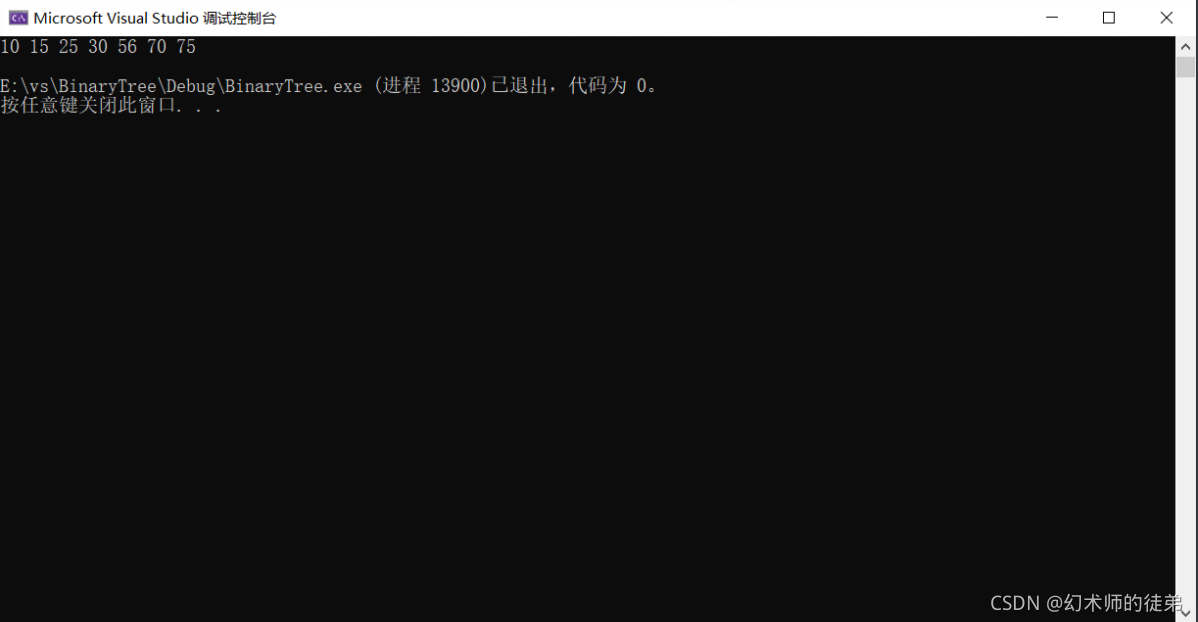
void test3()
{
int a[] = { 70, 56, 30, 25, 15, 10, 75 };
HeapSort(a, sizeof(a) / sizeof(a[0]));
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
int main()
{
test3();
return 0;
}

















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









