




- 官方文档的检索方式:github和官网
- 官方文档的阅读和使用:要求安装的包和文档为同一个版本
- 类的关注点:
- 实例化所需要的参数
- 普通方法所需要的参数
- 普通方法的返回值
- 绘图的理解:对底层库的调用
我们已经掌握了相当多的机器学习和python基础知识,现在面对一个全新的官方库,看看是否可以借助官方文档的写法了解其如何使用。
我们以pdpbox这个机器学习解释性库来介绍如何使用官方文档。
大多数 Python 库都会有官方文档,里面包含了函数的详细说明、用法示例以及版本兼容性信息。
通常查询方式包含以下3种:
- GitHub 仓库:https://github.com/SauceCat/PDPbox
- PyPI 页面:https://pypi.org/project/PDPbox/
- 官方文档:https://pdpbox.readthedocs.io/en/latest/
一般通过github仓库都可以找到对应的官方文档,在官方文档中搜索函数名,然后查看函数的详细说明和用法示例
以pdpbox库为例:
# pip install pdpbox scikit-learn pandas plotly
# pip install pdpbox --upgrade # 升级pdpbox下面以鸢尾花三分类项目来演示如何查看官方文档
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 加载鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target # 添加目标列(0-2类:山鸢尾、杂色鸢尾、维吉尼亚鸢尾)
# 特征与目标变量
features = iris.feature_names # 4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
target = 'target' # 目标列名
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
df[features], df[target], test_size=0.2, random_state=42
)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)此时模型已经建模完毕,这是一个经典的三分类项目。
在官方文档中,通常会有一个“API Reference”或“Documentation”部分,列出所有可用的函数、类和方法。
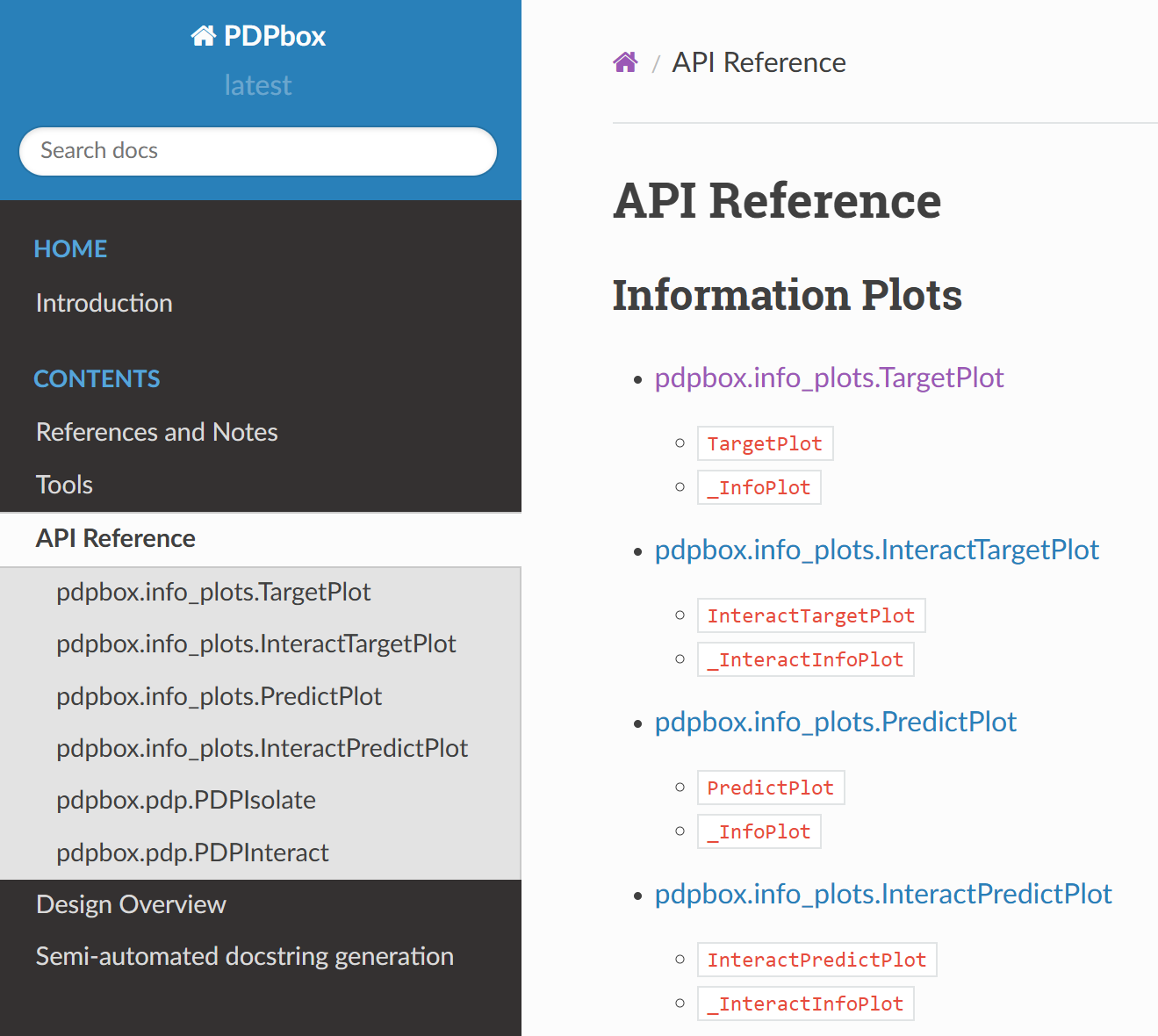 选择第一个图pdpbox.info_plots.TargetPlot进行绘制
选择第一个图pdpbox.info_plots.TargetPlot进行绘制
现在我们第一步是实例化这个类,TargetPlot类,确保安装的最新版本的库 (库名.__version__)
- 先导入这个类(三种不同的导入和引用方法)
- 传入实例化参数
import pdpbox
from pdpbox.info_plots import TargetPlot # 导入TargetPlot类可以鼠标悬停在这个类上,来查看定义这个类所需要的参数,以及每个参数的格式,ctrl进入可以查看这个类的详细信息
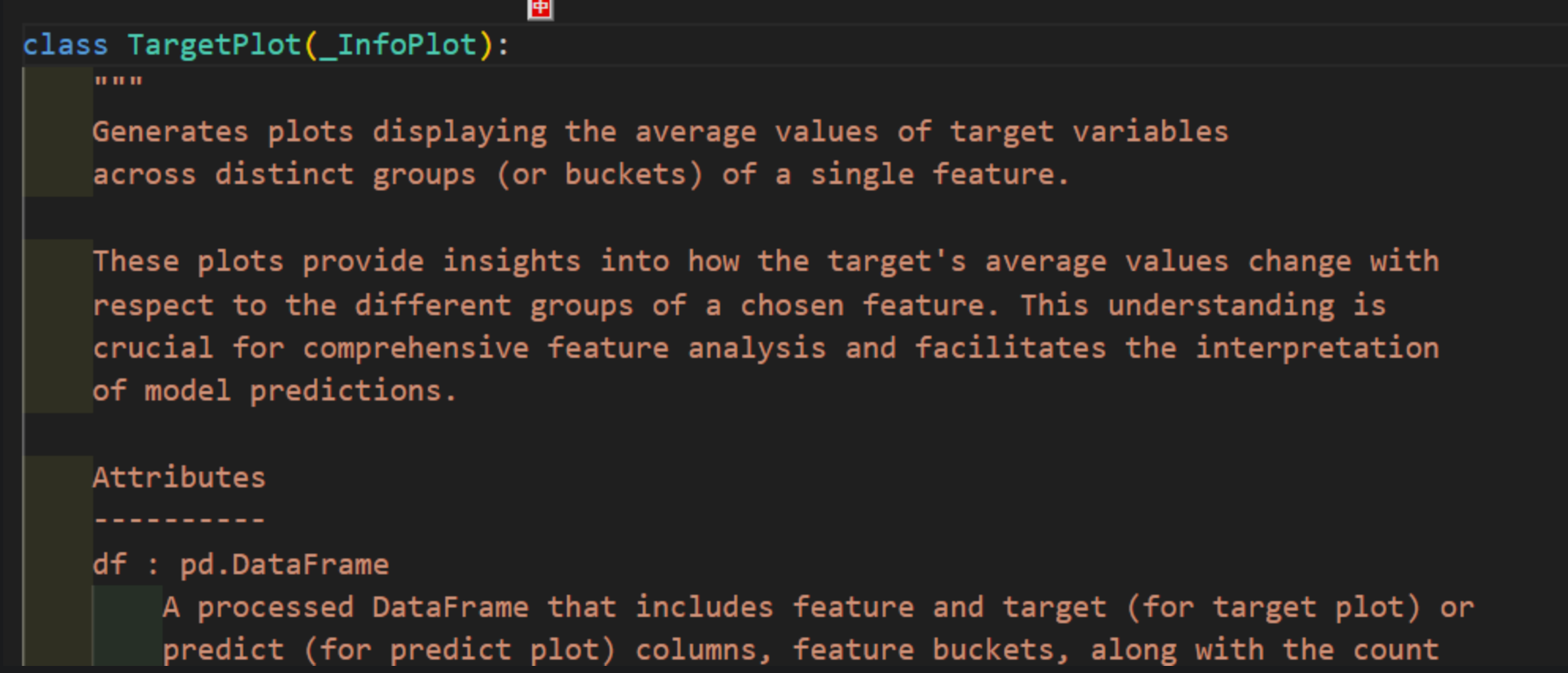
只能查看到他的初始化方法 __init__( ),但是无法看到他的普通方法。从提示中发现是有 plot( ) 方法的,但是看不到这个普通方法需要传入的参数;
但是发现 TargetPlot 类继承了_InfoPlot 类,此时我们再次进入 _InfoPlot 类里面,就顺利找到了这个继承的 plot() 方法及其参数。
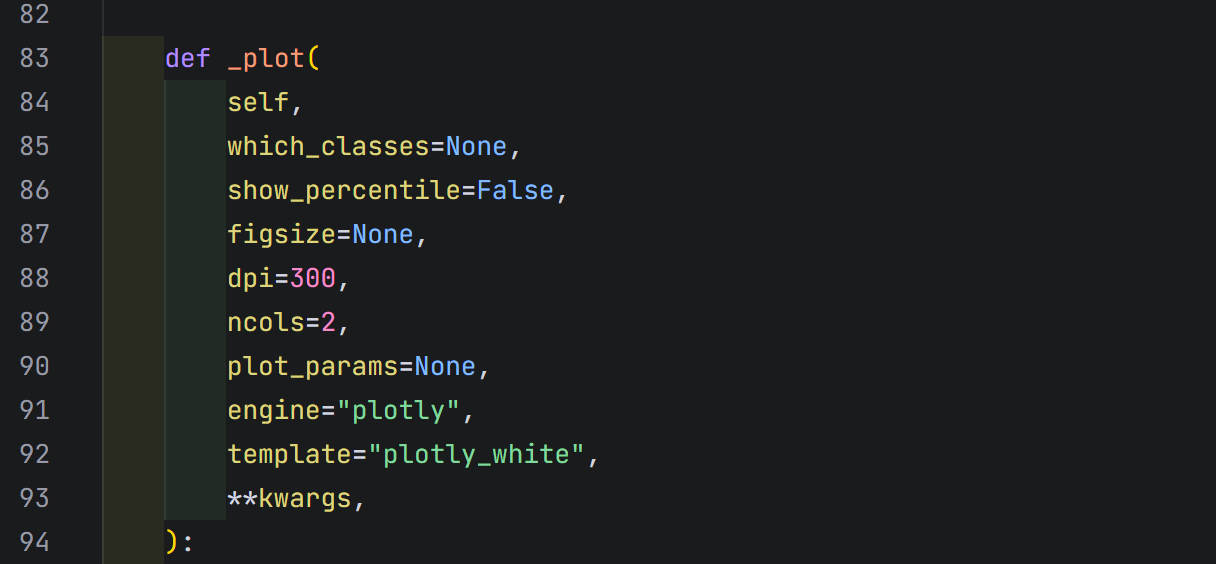
初始化TargetPlot对象并绘图
# 选择待分析的特征(如:petal length (cm))
feature = 'petal length (cm)'
feature_name = feature # 特征显示名称
# 初始化TargetPlot对象(移除plot_type参数)
target_plot = TargetPlot(
df=df, # 原始数据(需包含特征和目标列)
feature=feature, # 目标特征列
feature_name=feature_name, # 特征名称(用于绘图标签)
target='target', # 多分类目标索引(鸢尾花3个类别)
grid_type='percentile', # 分桶方式:百分位
num_grid_points=10 # 划分为10个桶
)# 调用plot方法绘制图形
target_plot.plot()实际上,返回一个三元组 (fig, axes, summary_df),其中 fig 是 Plotly 的 Figure 对象。要查看或修改图形的形状(如宽度、高度、边距等),可以直接操作这个 Figure 对象。
在官方文档介绍中的plot方法最下面,写明了参数和对应的返回值

综上需要注意,我们关注一个类需要关注如下信息
- 传入的参数和对应的格式
- 类对应的方法的返回值
最后,我们用规范的形式来完成
fig, axes, summary_df = target_plot.plot(
which_classes=None, # 绘制所有类别(0,1,2)
show_percentile=True, # 显示百分位线
engine='plotly',
template='plotly_white'
)
# 手动设置图表尺寸(单位:像素)
fig.update_layout(
width=800, # 宽度800像素
height=500, # 高度500像素
title=dict(text=f'Target Plot: {feature_name}', x=0.5) # 居中标题
)
fig.show()

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









