




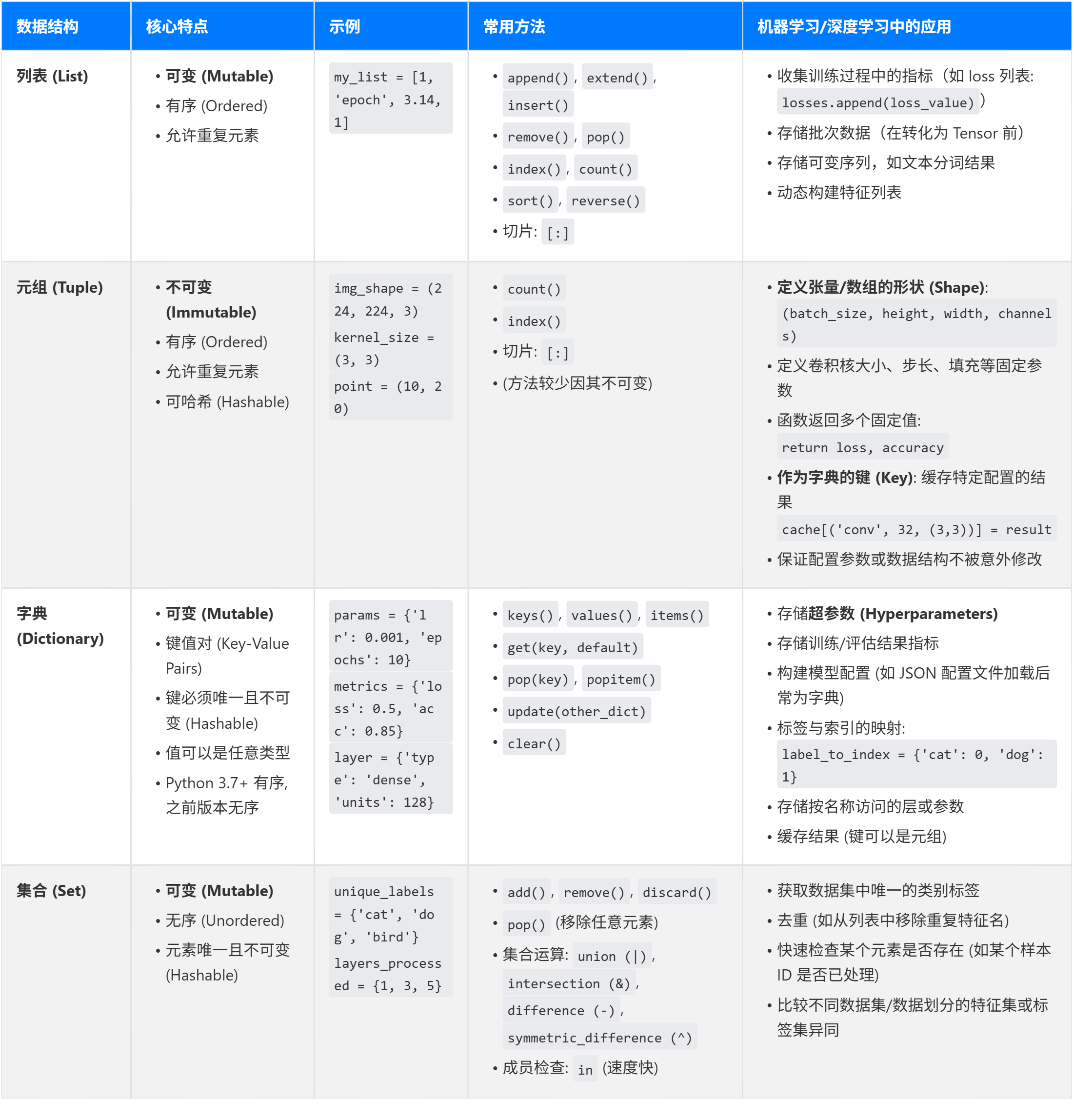
- 元组
- 可迭代对象
- os模块
元组
1. 元组的定义和特点
元组是python中一个内置数据类型,用于存储一系列有序的元素。元组中的元素可以是任何类型,包括数据、字符串、列表等,且元组之间用逗号分隔,整个元组用圆括号包围。
2. 元组和列表的对比
元组与列表在功能上有许多相似之处,但它们的可变性是关键区别。
列表是可变的,可以添加、删除或修改元素;而元组则不可变。
管道工程中pipeline类接收的是一个包含多个小元组的 列表 作为输入。
3. 与Pipeline的关系
管道工程中pipeline类接收的是一个包含多个小元组的列表作为输入。
可以这样理解这个结构:
1. 列表 [ ]: 定义了步骤执行的先后顺序。Pipeline 会按照列表中的顺序依次处理数据。之所以用列表,是未来可以对这个列表进行修改。
2. 元组 ( ): 用于将每个步骤的名称和处理对象捆绑在一起。名称用于在后续访问或设置参数时引用该步骤,而对象则是实际执行数据转换或模型训练的工具。固定了操作名+操作
可迭代对象
可迭代对象(Iterable)是Python中一个非常核心的概念。简单来说,一个可迭代对象就是指那些能后一次返回其成员(元素)的对象,让你可以在一个循环(比如for循环)中遍历它们。
Python中有很多内置的可迭代对象,目前我们见过的类型包括:
- 数据类型(Sequence Types):
- list(列表)
- tuple(元组)
- str(字符串)
- range(范围)
- 集合类型(Set Types):
- set(集合)
- 字典类型(Mapping Types):
- dict(字典)- 迭代时返回键(keys)
- 文件对象(File objects)
- 生成器(Generators)
- 迭代器(Iterable)本身
# 列表 (list)
print("迭代列表:")
my_list = [1, 2, 3, 4, 5]
for item in my_list:
print(item)
# 元组 (tuple)
print("迭代元组:")
my_tuple = ('a', 'b', 'c')
for item in my_tuple:
print(item)
# 字符串 (str)
print("迭代字符串:")
my_string = "hello"
for char in my_string:
print(char)
# range (范围)
print("迭代 range:")
for number in range(5): # 生成 0, 1, 2, 3, 4
print(number)
# 集合 (set) - 注意集合是无序的,所以每次迭代的顺序可能不同
print("迭代集合:")
my_set = {3, 1, 4, 1, 5, 9}
for item in my_set:
print(item)
# 字典 (dict) - 默认迭代时返回键 (keys)
print("迭代字典 (默认迭代键):")
my_dict = {'name': 'Alice', 'age': 30, 'city': 'Singapore'}
for key in my_dict:
print(key)
# 迭代字典的键值对 (items)
print("迭代字典的键值对:")
for key, value in my_dict.items(): # items方法很好用
print(f"Key: {key}, Value: {value}")OS模块
随着深度学习项目变得越来越大、数据量越来越多、代码结构越来越复杂,你会越来越频繁使用os模块来管理文件、目录、路径,以及进行一些基本的操作系统交互。虽然深度学习核心在于模型构建和训练,但数据和模型的有效管理是项目成功的关键环节,而os模块为此提供了重要的工具。
在简单的入门级项目中,你可能只需要使用pd.read_csv( )加载数据,而不需要直接操作文件路径。但是,当你开始处理图像数据集、自定义数据加载流程、保存和加载复杂的模型结构时,os模块就会变得非常有用
好的代码组织结构和有效文件管理是大型深度学习项目的基石。os模块是实现这些目标的重要组成部分。
import os
# os是系统内置模块,无需安装1. 获取当前工作目录
os.getcwd() # get current working directory 获取当前工作目录的绝对路径2. 获取当前目录下的文件列表
os.listdir() # list directory 获取当前工作目录下的文件列表# 我们使用 r'' 原始字符串,这样就不需要写双反斜杠 \\,因为\会涉及到转义问题
path_a = r'C:\Users\YourUsername\Documents' # r''这个写法是写给python解释器看,他只会读取引号内的内容,不用在意r的存在会不会影响拼接
path_b = 'MyProjectData'
file = 'results.csv'
# 使用 os.path.join 将它们安全地拼接起来,os.path.join 会自动使用 Windows 的反斜杠 '\' 作为分隔符
file_path = os.path.join(path_a , path_b, file)
file_path3. 环境变量方法
# os.environ 表现得像一个字典,包含所有的环境变量
os.environ# 使用 .items() 方法可以方便地同时获取变量名(键)和变量值,之前已经提过字典的items()方法,可以取出来键和值
# os.environ是可迭代对象
for variable_name, value in os.environ.items():
# 直接打印出变量名和对应的值
print(f"{variable_name}={value}")
# 你也可以选择性地打印总数
print(f"\n--- 总共检测到 {len(os.environ)} 个环境变量 ---")4. 目录树
os.walk( ) 是 Python os 模块中一个非常有用的函数,它用于遍历(或称“行走”)一个目录树。
核心功能:
os.walk(top, topdown=True, οnerrοr=None, followlinks=False) 会为一个目录树生成文件名。对于树中的每个目录(包括 top 目录本身),它会 yield(产生)一个包含三个元素的元组 (tuple):
(dirpath, dirnames, filenames)
- dirpath: 一个字符串,表示当前正在访问的目录的路径。
- dirnames: 一个列表(list),包含了 dirpath 目录下所有子目录的名称(不包括 . 和 ..)。
- filenames: 一个列表(list),包含了 dirpath 目录下所有非目录文件的名称。
示例目录结构:
假设你的 start_directory (当前工作目录 .) 是 my_project,其结构如下:
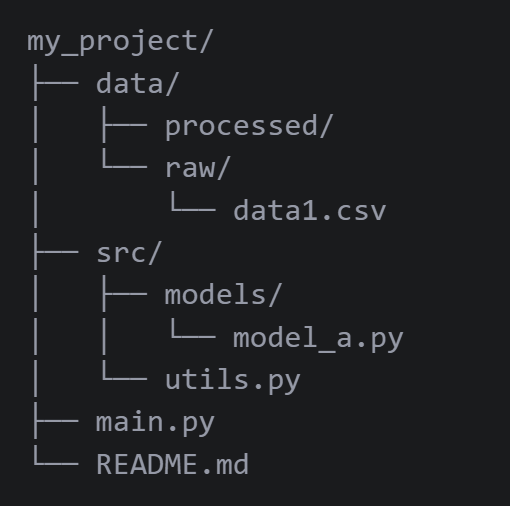
os.walk 会首先访问起始目录 (my_project),然后它会选择第一个子目录 (data) 并深入进去,访问 data 目录本身,然后继续深入它的子目录 (processed -> raw)。只有当 data 分支下的所有内容都被访问完毕后,它才会回到 my_project 这一层,去访问下一个子目录 (src),并对 src 分支重复深度优先的探索。
它不是按层级(先访问所有第一层,再访问所有第二层)进行的,而是按分支深度进行的。这种策略被称之为深度优先。
import os
start_directory = os.getcwd() # 假设这个目录在当前工作目录下
print(f"--- 开始遍历目录: {start_directory} ---")
for dirpath, dirnames, filenames in os.walk(start_directory):
print(f" 当前访问目录 (dirpath): {dirpath}")
print(f" 子目录列表 (dirnames): {dirnames}")
print(f" 文件列表 (filenames): {filenames}")
# # 你可以在这里对文件进行操作,比如打印完整路径
# print(" 文件完整路径:")
# for filename in filenames:
# full_path = os.path.join(dirpath, filename)
# print(f" - {full_path}")总结

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









