




 本文探讨了文本生成的背景和重要性,强调了预训练语言模型(PLMs)在该领域的应用。从输入数据编码、模型设计和优化等方面详细阐述了如何利用PLMs进行文本生成。讨论了非结构化、结构化和多模态输入的表征学习,以及标准的PLM结构,如掩码、因果和前缀语言模型。同时,介绍了微调技术,包括普通微调、中介微调、参数微调等,以适应不同任务需求。文章还涵盖了挑战,如数据不足、模型复杂性和优化问题,并提出了解决方案。
本文探讨了文本生成的背景和重要性,强调了预训练语言模型(PLMs)在该领域的应用。从输入数据编码、模型设计和优化等方面详细阐述了如何利用PLMs进行文本生成。讨论了非结构化、结构化和多模态输入的表征学习,以及标准的PLM结构,如掩码、因果和前缀语言模型。同时,介绍了微调技术,包括普通微调、中介微调、参数微调等,以适应不同任务需求。文章还涵盖了挑战,如数据不足、模型复杂性和优化问题,并提出了解决方案。
本文生成的目标是通过输入数据用人类语言产生可靠、可读的文本。PLMs应用到文本生成要关注三个点:
- 如何将输入数据编码为表征并保留输入语义,从而融入到PLMs。
- 如何设计一个有效的PLM作为生成模型。
- 如何在给定参考文本的情况下对PLM进行精调,并保证生成文本满足特殊属性。
一、简介
文本生成,也称为自然语言生成,是自然语言处理(NLP)中的最重要的一种。它的目的是在一个人类的语言上产生可信的和可读的文本。输入数据的式包括文字、图像、表格和知识各种形。在过去的几十年里,文本生成技术得到了广泛的应用。例如,对话系统中、机器翻译、文本摘要。
文本生成的主要目标是从数据中自动学习输入到输出的映射,以在最少的人工干预下构建端到端解决方案。这种映射功能使生成系统具有更广泛的泛化能力,能够在给定条件下生成自由文本。早期的方法通常采用统计语言模型对给定𝑛-gram上下文的单词的条件概率进行建模。这种统计方法会受到数据稀疏性问题的影响,已经开发了一些平滑方法来缓解这个问题,以便更好地估计未观察到的项出现次数。尽管如此,这些方法仍然使用单词标记作为基本表示单元,这导致了相似的标记不能容易地相互映射的问题。
随着深度学习技术的出现],神经网络模型占据了主导地位主流的文本生成方法,并在生成自然语言方面取得了非凡的成功。深度神经生成模型通常采用序列到序列框架。基于编码器-解码器方案:编码器首先将输入序列映射为固定大小的低维度向量(称为输入嵌入),然后解码器基于生成目标文本。已经提出了各种不同设计的编码器-解码器架构的神经模型,例如用于编码图输入的图神经网络(GNN)和用于文本解码的循环神经网络(RNN)。此外,注意力机制
复制机制被广泛用于提高文本生成模型的性能。
二、准备工作
2.1文本生成
每个文本建模为一个token序列
y
=
⟨
y
1
,
…
,
y
j
,
…
,
y
n
⟩
y=\left\langle y_1, \ldots, y_j, \ldots, y_n\right\rangle
y=⟨y1,…,yj,…,yn⟩,
y
j
y_j
yj来自词汇表,
x
x
x为输入数据。需保证的语言属性例如流畅性、自然性、连贯性等。文本生成定义为
y
=
f
M
(
x
,
P
)
y=f_{\mathcal{M}}(x, \mathbb{P})
y=fM(x,P)
其中
f
M
f_{\mathcal{M}}
fM为生成模型,通常为预训练模型PLM,
P
\mathbb{P}
P为需满足属性集合。根据输入数据和所需满足属性的不同,可将文本生成任务分为以下类:
- 当没有输入 x x x或者其为随机向量时,文本生成生成语言模型或无条件文本生成,所需满足属性可为流畅性和自然性。
- 当输入 x x x为离散属性时(例如话题词、或情感标签),文本生成为话题-文本生成或基于属性的生成,此时生成文本要符合给定的话题或给定的文本属性。
- 当输入 x x x为结构化数据时(例如知识、表格),文本生成为数据-文本生成,输出要保证准确性。
- 当输入 x x x为多模态输入时(例如图片、语音),文本生成就变成了图片捕获和语音识别任务。
- 大多数情况下,输入 x x x为文本序列。机器翻译、文本摘要、对话系统都属于这种类型。
2.2 预训练语言模型
预训练语言模型就是在大型未标记语料库上提前进行训练,能适配各种下游子任务。PLMs可以用大量参数编码大量有意义的语言知识。预训练+精调的范式有助于自然语言理解和自然语言生成任务。几乎所有PLM都是基于Transformer来实现的。典型的有GPT系列用Transformer的decoder,BERT用Tansformer的encoder。 XLNet, RoBERTa以及ERNIE基于BERT实现,T5和BART是基于encoder-decoder实现。增加参数数量可以提升预训练模型的效果,因此有GPT-3之类的模型出现。
2.3 基于PLMs的文本生成
分别从数据、模型、优化三方面考虑:
- 输入数据:重点在于给PLMs提升模型效率、灵活的表征学习用以捕获各种输入数据类型的语义信息。
- 模型结构:自编码模型(可以融入上下文信息。例如BERT)、自回归模型(预测下一个词。只能通过以往信息进行预测,例如GPT系列)。
- 优化算法:难点在于一些所需的特性难以定量计算和优化。
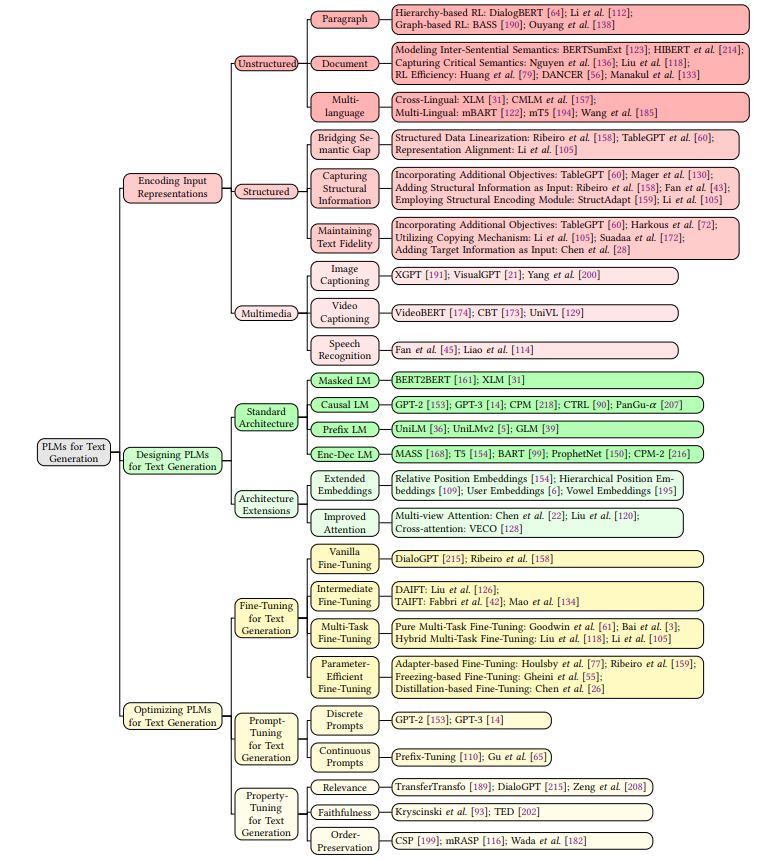
接下来将会从这三方面进行介绍,PLMs应用到文本生成的大致流程如下图所示:

三、编码输入表征
3.1 非结构化输入
非结构化输入只关注文本输入,包括句子、段落和文档。重点在于准确的学习输入文本表征。文本表征学习的目标是将输入文本转换为低维的向量。
3.1.1 段落表征学习
段落由句子组成,段落表征学习需要捕获低级别的词语和高级别的语义。可通过基于层次的方法和基于图的方法来完成。
- 基于层次的方法:DialogBERT
- 基于图的方法:段落可能包含重复和矛盾的信息,利于图结构可以解决该问题。例如可以将词或段落直接作为节点,它们之间的相似度作为边。
3.1.2 文档表征学习
多个段落组成一个文档,重点在于如何建模句内/段内语义以及捕获关键的语义。
- 建模句内语义:以分层方式学习文档表示,先学习句子表示,再学习上下文相关的句子表示。
- 捕获关键语义:通过主题模型(topic model)获取关键语义表示。
- 表征学习效率:可通过分治法提升效率,长文档分割为短句;局部自注意力机制。
3.1.3 多语言表征学习
- 语言内表征:构建一个共享embedding空间,学习多种语言的相同表征。
- 多语言表征:CSR(contrastive sentence ranking)、SAS(sentence aligned substitution)
3.2 结构化输入
现实世界中有许多数据都是结构化的,例如病历、天气预报。结构化输入的文本生成需要关注三个方面:(1)由于PLMs是由自然语言文本训练而来,所以结构化数据与之存在语义鸿沟;(2)结构化输入中结构信息不容易编码;(3)生成文本要忠实于原始数据
3.2.1 缩小语义鸿沟
- 结构化数据线性化:例如将知识图谱线性化为三元组。
- 表征对齐:将结构化数据表征与PLM的词嵌入在语义空间对齐。
3.2.2 捕获结构信息
- 纳入额外训练目标:将结构信息融入输入,重构表结构,额外进行训练,例如在PLMs的属性值表征基础上,将输入表的属性名作为标签,用来重构表结构;提出了基于循环一致性的损失,以评估输出文本的质量,基于它可以重建输入结构的程度。
- 添加结构信息作为输入
- 采用结构编码模块:直接用结构编码器。
3.2.3 保留文本真实度
- 纳入额外训练目标
- 使用copy机制
- 添加目标信息到输入
3.3 多模态输入
与研究方向不符合,略过。。。
四、设计文本生成的PLMs
将输入数据编码为低维表征之后,需要设计一个PLM
M
\mathcal{M}
M作为生成函数
f
M
f_{\mathcal{M}}
fM,由此可将生成目标构建为给定输入
x
x
x,生成文本
y
y
y的条件概率:
Pr
M
(
y
∣
x
)
=
∏
i
=
1
n
Pr
M
(
y
i
∣
y
<
i
,
x
)
,
\operatorname{Pr}_{\mathcal{M}}(y \mid x)=\prod_{i=1}^n \operatorname{Pr}_{\mathcal{M}}\left(y_i \mid y_{<i}, x\right),
PrM(y∣x)=i=1∏nPrM(yi∣y<i,x),
其中
y
i
y_i
yi为第
i
i
i个token,
y
<
i
y_{<i}
y<i表示
y
i
y_i
yi之前的tokens
y
1
,
…
,
y
i
−
1
y_1, \ldots, y_{i-1}
y1,…,yi−1。
4.1 标准结构
要么是采用单个Transformer(encoder或者decoder)要么是基于Transformer(encoder-decoder)的架构。例如GPT-3、UniLM,这种类似结构(只有encoder或只有decoder)的主要包括三种类型:掩码语言模型(MML)、因果语言模型、前缀语言模型;另外一种类型是基于encoder-decoder的语言模型。
4.1.1 掩码语言模型(Masked Language Models)
采用full-attention机制的encoder,例如考虑双向信息来对mask的token进行预测。代表是常用来做自然语言理解的BERT。
4.1.2 因果语言模型(Causal Language Models)
类似于Transformer的decoder,使用对角掩码矩阵。因果语言模型用来确定给定确定给定的单词序列在一个句子中出现的概率。下一个词预测。例如GPT是第一个文本生成的因果语言模型;GPT-2为零样本生成任务扩展转换能力;GPT-3使用少量的样例或提示以及大规模参数提升效果;CTRL是一种条件因果LM,用于基于控制样式、内容和特定于任务的行为的控制代码生成文本。因果语言模型在结构和算法上的限制:仅从左到右对标记进行编码,因此忽略了输入端的双向信息。因果语言模型不是专门为序列到序列的生成任务设计的,因此它们在摘要和翻译等任务中并没有达到很高的性能。
4.1.3 前缀语言模型(Prefix Language Models)
前缀语言模型在输入端采用双向的encoding,在输出端采用从左到右的生成模式。UniLM是第一个前缀语言模型,其使用前缀注意力掩码(prefix attention mask)解决条件生成任务,有点类似于encoder-decoder。
4.1.4 encoder-decoder语言模型
标准的Transformer结构。MASS和ProphetNet将带有一个掩码段的序列作为编码器的输入,然后解码器以自回归的方式生成掩码标记。T5用不同的特殊标记随机替换源文本中的几个span,然后解码器依次预测每个被替换的span。
4.2 结构扩展
4.2.1 扩展输入嵌入
除了词嵌入,一般还有会有位置嵌入。大多数PLMs(BERT、GPT)都使用绝对位置嵌入,也有一些(T5、UniLMv2、ProphetNet)使用相对位置嵌入,层次位置嵌入用于固定格式的文本,例如诗歌。
4.2.2 提升注意力机制
各种注意力机制的变种。self-attetion、cross-attention、full-attention、window-attention、global-attention、random-attention、Sinkhorn-attention。
五、优化PLMs
5.1 微调(fine-tuning)
预训练时,PLMs会捕获大型语料库的语言知识,但是为了适配下游任务,所以需要用下游任务的数据集来进行训练,也即常说的微调过程。微调是一种通过使用下游文本生成数据集调整它们的权重,将特定于任务的信息合并到PLM中。根据微调的参数如何更新,可将微调分为四种类型:普通微调(vanilla fine-tuning)、中介微调( intermediate fine-tuning)、参数高效微调(parameter-efficient fine-tuning)、多任务微调( multi-task fine-tuning)。
在小数据集上,和普通微调相比,中介微调和多任务微调能够缓解过拟合问题。由于普通微调需要调整整个模型,所以与之相比参数微调更加轻量级。
5.1.1 普通微调
普通微调使用下游任务数据集的特定任务损失来更新PLMs,例如交叉熵损失。BART和T5用经典的自回归交叉熵损失来对图-文本生成进行微调。普通微调的主要问题在于不能充分优化小数据集且易于过拟合。
5.1.2 中介微调
中介微调是将有足够多标记实例的中介数据集纳入微调。中介数据集来自不同领域的同一目标文本生成任务或者相同目标领域的相似NLP任务。可分细分为两类:领域适配的中介微调(DAIFT)和任务适配的中介微调(TAIFT)。
- 领域适配的中介微调:同一个目标领域,相似的NLP任务(非文本生成任务)的数据集。常用于机器翻译中翻译对的不可见语言(unseen language)。
- 任务适配的中介微调:相同的文本生成任务,不同目标领域额的数据集。
5.1.3 多任务微调
多任务微调(MTFT)是通过纳入辅助任务,利用任务交叉的知识来提升原本的生成任务。通过获取相关NLP任务的知识,多任务微调可以增强PLMs的鲁棒性并且减少对大量标记实例的需求。分为纯净MTFT和混合MTFT两种类型。
- 纯净多任务微调:相似文本生成任务,不同目标领域。
- 混合多任务微调:不同的文本生成任务。
5.1.4 参数微调
以上几种微调的方法都需要更新PLM的所有参数,参数微调只需要更新部分参数。
- 基于适配器的参数微调:适配器(Adapter)是一个特殊的神经层,先用两层前馈层把输入向量降维处理,再用一个非线性层把维度变为原始的维度。例如:输入是d维,经过前馈层变成了m维,最终需改变的参数为2md+d+m个。
- 基于冻结的参数微调:大部分参数冻结,只更新少部分。例如:在机器翻译任务中,更新交叉注意力或者decoder-encoder比更新自注意力更重要。
- 基于蒸馏的参数微调:知识蒸馏就是提取教师模型(teacher model)中的知识作为学生模型(student model)的输出。例如:BERT作为教师模型学习生成词序列的逻辑概率,再用Seq2Seq模型作为学生模型。
5.2 文本生成的提示微调
提示学习就是在预训练时把下游任务(文本生成任务)转换成语言建模任务。
5.2.1 背景
提示函数
f
prompt
(
x
)
f_{\text {prompt }}(x)
fprompt (x)将输入
x
x
x转换成提示
x
′
=
f
prompt
(
x
)
x^{\prime}=f_{\text {prompt }}(x)
x′=fprompt (x)需要两个步骤:
(1)输入
x
x
x对应插槽(slot)
[
X
]
[X]
[X],中途生成的答案
z
z
z对应另一个插槽
[
Z
]
[Z]
[Z],
z
z
z后续会映射到输出
y
y
y。
(2)用输入
x
x
x替换插槽
[
x
]
[x]
[x]。
提示有close-style和prefix-style两种风格。其中,close-prompt的
[
Z
]
[Z]
[Z]在提示模板的中间,常用于NLU任务。例如在情感分析中
x
x
x=“I love this movie”,模板可能为“
[
X
]
[X]
[X] It was a really &[Z]& movie”;prefix-style在句子末尾,常用于文本生成任务,例如机器翻译中“English:
[
X
]
[X]
[X] German:
[
Z
]
[Z]
[Z]”。提示有两种类型,离散提示和连续提示。而上述例子都属于离散提示。
5.2.2 离散提示(tokens)
早期离散提示大多由人为设计,因此会产生不准确的模板而影响模型性能。为了避免手动设计的需求,以及追求高性能,于是有了自动生成的模板。例如重构已有的模板、使用PLMs生成模板、从语料库挖掘模板等方法。
5.2.3 连续提示(embedding)
连续提示由嵌入向量组成,其优点如下:(1)放宽了提示模板为自然语言单词的条件;(2)移除了模板必须被PLMs的参数参数化的限制。连续提示有自己的参数,可以根据文本生成任务的训练数据集进行优化。使用该方法最多的就是前缀微调。前缀微调不改变PLMs,只更新特定于任务的向量序列,这个序列称为前缀。
5.3 文本生成的属性微调
在此列举三种较为通用的三种属性:相关性、忠实性、顺序保留。
- 相关性:输出文本的主要语义要高度关联输入文本。
- 忠实性:生成内容要遵循输入文本的语义。
- 顺序保留:顺序保留是指输入和输出文本的语义单元(单词、短语)的顺序一致。
六、挑战和解决
从数据、模型、优化三个方面进行介绍。

6.1 数据方面
6.1.1 缺乏足量的训练数据
挑战:缺乏数据
解决:(1)迁移学习:先在数据足够丰富的有标签语料对PLM进行微调,然后迁移到缺乏的目标文本生成任务;(2)数据增强:稍微改动已有数据或根据已有数据构建新的数据;(3)多任务学习:添加辅助任务。
6.1.2 预训练语料的数据偏差
挑战:预训练语料库的数据偏差,可能带有种族歧视、性别歧视、年龄歧视等问题。
解决:用词嵌入解决性别歧视;识别并mask偏差敏感的tokens。
6.2 模型方面
6.2.1 模型压缩
挑战:模型过于笨重
解决:
(1)量子化:删除部分PLM的权重。用更少的bits来表示。量子化通常用于全连接层的权重,例如嵌入层、线性层、前向反馈层。而压缩模型之后,性能也会受影响,因此需要在量子化之前识别重要的权重,在量子化过程中不删除重要的权重。
(2)剪枝:剪枝就是识别那些不重要或冗余的权重。剪枝方法主要分为两类,非结构化剪枝通过定位PLMs中最不重要的权重集合来删除单个权重。权重的重要性可以通过绝对值和梯度等特定指标来衡量;结构化剪枝通过减少和简化某些模块(如注意力头和transformer层)来删除PLM的权重甚至整个模块的结构化块。
(3)知识蒸馏:是指使用PLMs(taecher)的输出来训练一个更小的模型(student)。学生模型可以直接从PLMs中最终softmax层的输出单词分布中学习,它允许学生通过复制整个词汇表中的单词分布来模拟老师生成的文本。其次,学生还可以从PLMs编码器的输出张量中学习。即PLMs编码器的表示可能包含有意义的语义和输入tokens之间的上下文关系,这有助于生成准确的文本。
6.2.2 模型增强
挑战:性能需要提高
解决:
(1)大型PLM:增加PLMs的参数。(GPT-3)
(2)知识浓缩PLM:从额外的知识源提取知识。
(3)高效PLM:精心设计PLM的结构。
6.3 优化方面
6.3.1 满足文本属性
介绍另外三个属性
- 连贯性:使得多个句子在逻辑和句法上都有意义。
- 真实性:忠于输入,忠于事实。在数据到文本生成中,指针生成器(pointer generator)常被用来复制输入事实用以保留真实性。
- 可控性:要生成的文本之可控的,例如给小孩看的要保证文本是安全的。。。
6.3.2 减少微调的不稳定性
由于PLMs的灾难性遗忘以及数据集较少,导致微调用于文本生成的PLM不稳定。
- 中介微调
- Mixout
- 对比学习:用交叉熵损失来微调PLMs是不稳定的。
七、评价和资源
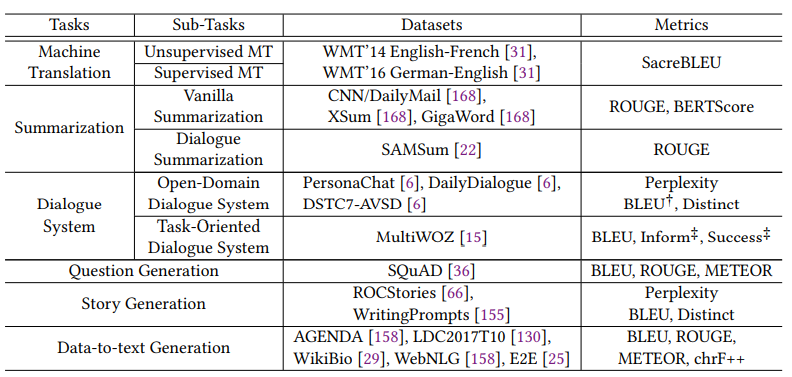
八、应用
机器翻译、摘要、对话系统、代码注释、数据到文本生成。。。。。。
九、总结与挑战
- 可控性的生成:例如对话系统中给病人的回应是积极的。
- 优化研究
- 语言单一:现有的基本是英文的PLMs
- 道德问题
参考文献


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









