 神经网络驱动的文本生成:原理与挑战
神经网络驱动的文本生成:原理与挑战





 本文介绍了文本生成的任务类型,包括数据到文本和文本到文本生成。神经网络在语言建模中的应用,如条件和非条件语言建模,以及自回归和非自回归生成被详细阐述。解码策略如贪婪解码、beamsearch和抽样方法对生成效果的影响也被讨论。此外,文章探讨了如何通过prompt方法、更改概率分布和重构模型结构实现可控文本生成,并列举了BLEU、PPL和ROUGE等评估指标。最后,文章提到了文本生成面临的挑战,如重复词、暴露偏差、逻辑一致性及评价标准的问题。
本文介绍了文本生成的任务类型,包括数据到文本和文本到文本生成。神经网络在语言建模中的应用,如条件和非条件语言建模,以及自回归和非自回归生成被详细阐述。解码策略如贪婪解码、beamsearch和抽样方法对生成效果的影响也被讨论。此外,文章探讨了如何通过prompt方法、更改概率分布和重构模型结构实现可控文本生成,并列举了BLEU、PPL和ROUGE等评估指标。最后,文章提到了文本生成面临的挑战,如重复词、暴露偏差、逻辑一致性及评价标准的问题。
文本生成
1. 文本生成任务
正式定义:Produce understandable texts in human languages from some underlying non-linguistic representation of information.[Building applied natural language generation systems.]
将非语言表示的信息通过人类可以理解的人类语言表示出来。
上面定义中非语言的表示主要指的是图片、表格、图等数据格式,因此所定义的是数据到文本生成(data-to-text generation)。除了data-to-text还有text-to-text都属于文本生成。
一些文本生成的任务(应用):
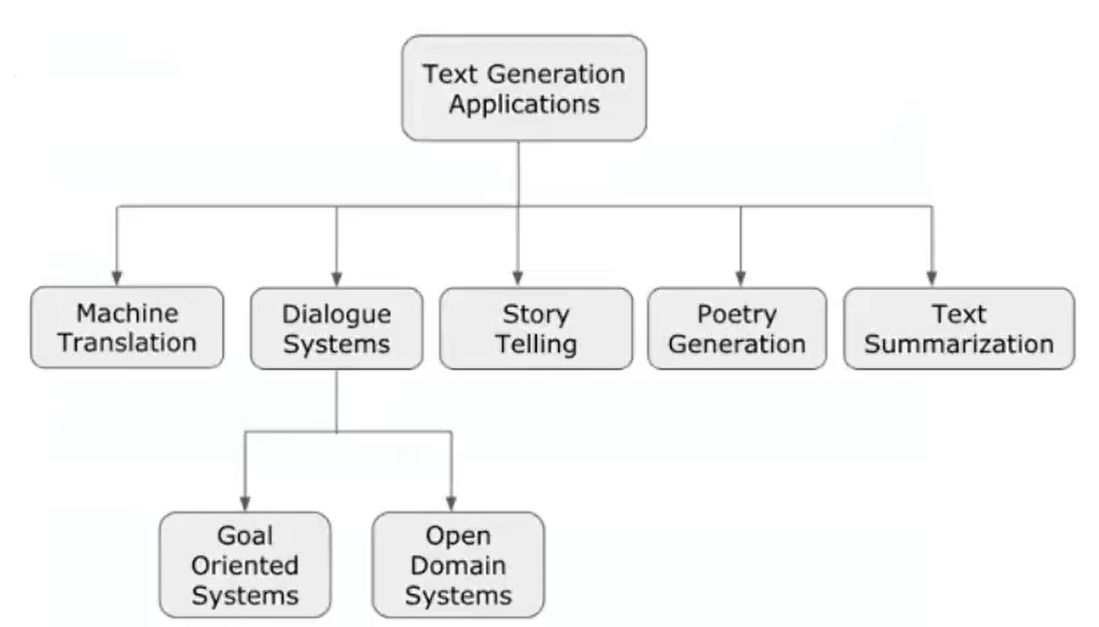
2. 神经网络文本生成
2.1 语言建模
语言模型就是计算target概率分布的一个模型。例如:语言模型可以建模为P(yt∣y1,y2,…,yt−1)P\left(y_t \mid y_1, y_2, \ldots, y_{t-1}\right)P(yt∣y1,y2,…,yt−1),当预测第t个词时,需要考虑第1-(t-1)个词的概率。
语言建模可以分为两种:
- 条件语言建模:P(yt∣y1,y2,…,yt−1,x)P\left(y_t \mid y_1, y_2, \ldots, y_{t-1}, x\right)P(yt∣y1,y2,…,yt−1,x),生成当前词时,除了要考虑当前已生成的词还要考虑其他额外的输出,例如机器翻译任务中,还要考虑输入序列。
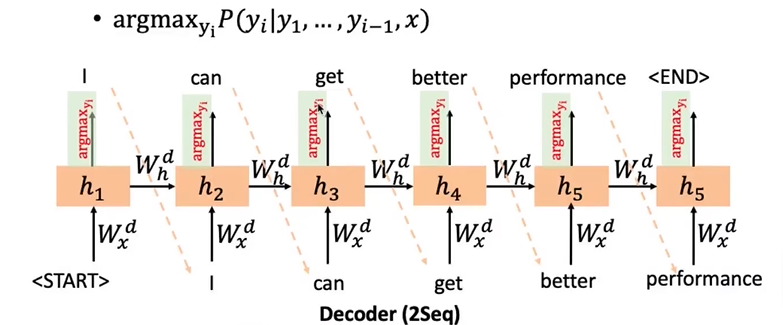
- Seq2Sqe:前一个sequence指encoder,后一个sequence指decoder。encoder生成原句子的表示,decoder根据encoder的结果生成target。P(y∣x)=P(y1∣x)P(y2∣y1,x)…P(yT∣y1,…,yT−1,x)P(y \mid x)=P\left(y_1 \mid x\right) P\left(y_2 \mid y_1, x\right) \ldots P\left(y_T \mid y_1, \ldots, y_{T-1}, x\right)P(y∣x)=P(y1∣x)P(y2∣y1,x)…P(yT∣y1,…,yT−1,x)seq2seq是一种end-to-end的方式训练的,seq-to-seq还用了teacher forcing的训练方式,就是说在训练时,预测下一个词不是基于已经预测的词,而是基于给定事实的词,而测试时是基于上一步预测的词来预测。由于在训练和测试时使用的方法不同,会产生暴露偏差问题(exposure bias)。
- 非条件语言建模
2.2 语言模型
给定输入x=(x1,x2,…,xn)x=(x_1,x_2,\dots,x_n)x=(x1,x2,…,xn),输出y=(y1,y2,…,ym)y=(y_1,y_2,\dots,y_m)y=(y1,y2,…,ym)。
- 自回归生成:根据过去的值生成现在的值。顺序生成P(y∣x)=∏t=1mP(yt∣y<t,x,θenc,θdec)P(y \mid x)=\prod_{t=1}^m P\left(y_t \mid y_{<t}, x, \theta_{e n c}, \theta_{d e c}\right)P(y∣x)=∏t=1mP(yt∣y<t,x,θenc,θdec)。如GPT系列。
- 非自回归生成:平行的生成(非时序的)P(y∣x)=P(m∣x)∏t=1mP(yt∣z,x)P(y \mid x)=P(m \mid x) \prod_{t=1}^m P\left(y_t \mid z, x\right)P(y∣x)=P(m∣x)∏t=1mP(yt∣z,x),其中P(m∣x)P(m \mid x)P(m∣x)决定了目标序列的长度,z=f(x;θenc)z=f(x;\theta_{enc})z=f(x;θenc)捕获了输出tokens的dependencies(不同x和不同y之间的权重关系)。
2.3 文本生成中的解码策略
- 贪婪解码:将每一步预测的概率最大的最为生成对象。由于只考虑当前概率最大,不考虑上下文,有可能生成重复的或可读性不好的句子。
- beam search:每一步都去追踪k个概率最大的局部序列,最后在这k个中选择一个概率最大的作为输出。这里达到的是局部最优解,并非全局最优。
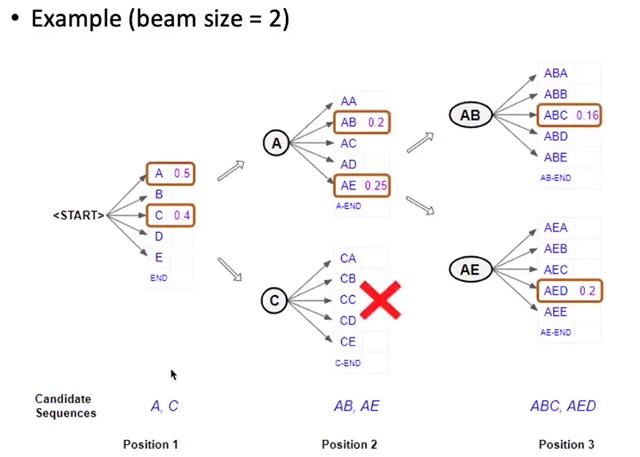
对于k的选择,如果选择较小,接近于1,那么解码策略就趋近于贪婪解码,会遇到生成文本不自然、可读性不好、不正确等问题;若k取较大的值,每一步要保留的结果会增多,计算资源也会增加。同时增大k会造成一些别的问题,比如在机器翻译中,k太大会降低模型的BLEU分数。k越大与输入相关度越低。 - 基于抽样的方法
- Pure sampling(简单采样):每一步采样,直接随机选取一个概率的token作为结果。
- Top-n sampling:每一步采样,在概率最大的n个token中随机采样一个作为结果。
- Top-p sampling:每一步采样,在概率最大的若干个token上采样,并且这些token的概率加起来要大于某个阈值p,然后在这若干个token中随机采样作为结果。p=1就是简单采样。
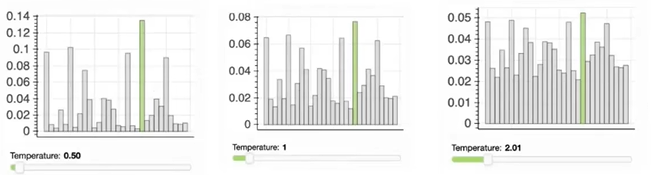
- samplle with temperature:在进入softmax之前,将这些概率分布除以一个temperature τ\tauτ。下图中temperature分别取0.5、1、2,取0.5是概率分布会变稀疏,采样的重复词可能性会更高但和输入相关性高;取2时。分布会变得平均,采样的结果会更有多样性但可能和输入不相关的文本。
 总结:n/p/temperature增大,会获得更加多样性的文本,减少的话会更加安全(因为更符合输入)。
总结:n/p/temperature增大,会获得更加多样性的文本,减少的话会更加安全(因为更符合输入)。
3. 可控文本生成
3.1 Prompt methods
- 在文本前面加入控制信号
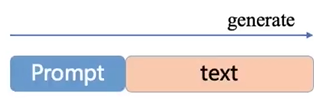

- 在模型前面加入前缀
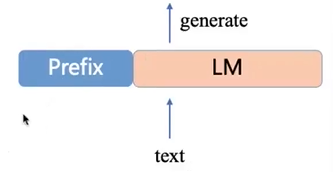
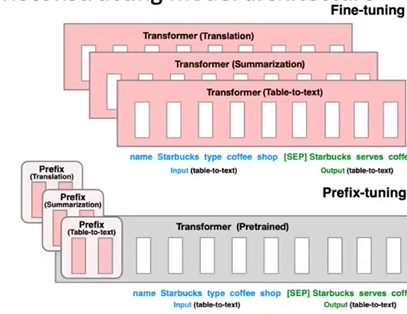
3.2 更改概率分布
类似于对比学习,有一个基本模型,一个天使模型和一个恶魔模型,希望生成的概率贴近天使模型,远离恶魔模型。P~(Xt∣x<t)=softmax(zt+α(zt+−zt−))\tilde{P}\left(X_t \mid \boldsymbol{x}_{<t}\right)=\operatorname{softmax}\left(\mathbf{z}_t+\alpha\left(\mathbf{z}_t^{+}-\mathbf{z}_t^{-}\right)\right)P~(Xt∣x<t)=softmax(zt+α(zt+−zt−)),其中zt+z_t^+zt+是天使模型的概率,α\alphaα为一个调控系数。
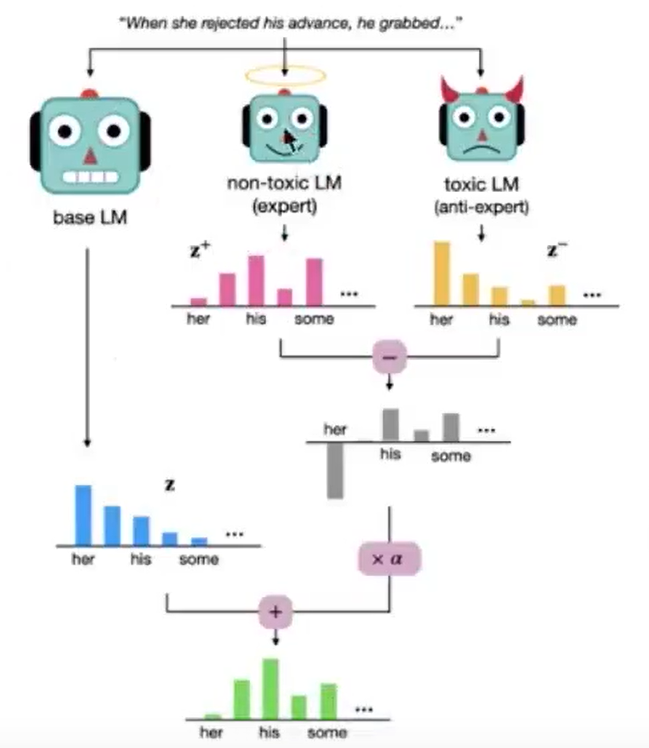
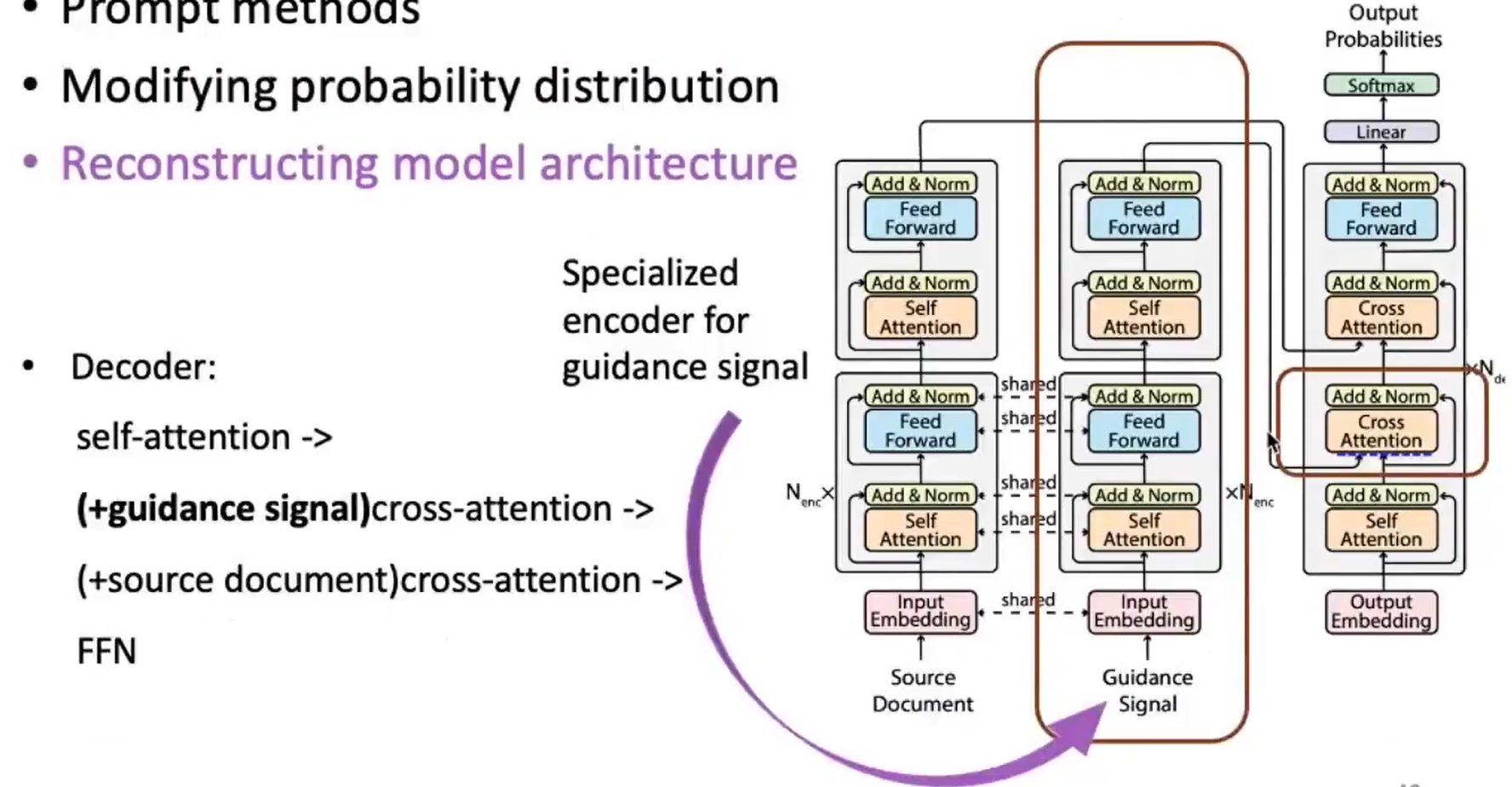
3.3 重构模型结构
给控制信号直接增加transformer结构。
4. 文本生成评估
- BLEU: N代表n-gram,即有n个token一致。不考虑语义和句子结构,易于计算。
BLEU=BP×exp(∑n=1NWn×logPn),BP={1lc>lrexp(1−lrlc).lc≤lrB L E U=B P \times \exp \left(\sum_{n=1}^N W_n \times \log P_n\right), \quad B P=\left\{\begin{array}{cc}1 & l c>l r \\ \exp \left(1-\frac{l r}{l c}\right) . & l c \leq l r\end{array}\right.BLEU=BP×exp(n=1∑NWn×logPn),BP={1exp(1−lclr).lc>lrlc≤lr - PPL:在测试的时候计算,验证模型有多大概率生成样本。值越低说明拟合得越好。
perplexity (S)=p(w1,w2,w3,…,wm)−1/m=∏i=1m1p(wi∣w1,w2,…,wi−1)m \begin{gathered} \text { perplexity }(S)=p\left(w_1, w_2, w_3, \ldots, w_m\right)^{-1 / m} \\ =\sqrt[m]{\prod_{i=1}^m \frac{1}{p\left(w_i \mid w_1, w_2, \ldots, w_{i-1}\right)}} \end{gathered} perplexity (S)=p(w1,w2,w3,…,wm)−1/m=mi=1∏mp(wi∣w1,w2,…,wi−1)1 - ROUGE:基于召回率计算的方法,
- ROUGE - N =∑S∈{ ReferenceSimmaries }∑gram N∈S Count match ( gram N)∑∑RefenceSimmaries }∑gram N∈SCount( gram N) \text { ROUGE - N }=\frac{\sum_{S \in\{\text { ReferenceSimmaries }\}} \sum_{\text {gram }_N \in S} \text { Count }_{\text {match }}\left(\text { gram }_N\right)}{\sum_{\left.\sum_{\text {RefenceSimmaries }}\right\}} \sum_{\text {gram }_N \in S} \operatorname{Count}\left(\text { gram }_N\right)} ROUGE - N =∑∑RefenceSimmaries }∑gram N∈SCount( gram N)∑S∈{ ReferenceSimmaries }∑gram N∈S Count match ( gram N)
5. 挑战
- 训练和模型策略
- 会生成重复的词
- 暴露偏差
- 常识性
- 缺少逻辑的一致性
- 控制性
- 难以同时保证语言质量和控制质量
- 评价
- 合理的指标和数据集


















 5629
5629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









