



知识点:
1.网格搜索
2.随机搜索
3.贝叶斯优化
4.time库的记时模块
5.代理模型的思想
6.给ai提问
1. 概述
核心知识点回顾
-
模型组成 = 算法 + 实例化设置的外参(超参数)+ 训练得到的内参
-
调参原则:只要调参就需要考2次
- 传统方式:划分训练集、验证集、测试集
- 现代方式:很多调参函数自带交叉验证(可省去验证集)
学习目标
本节课将学习三种主流调参方法:
- ✅ 网格搜索(GridSearchCV):穷举式搜索
- ✅ 随机搜索(RandomizedSearchCV):随机采样---只是一种思想
- ✅ 贝叶斯优化(BayesSearchCV):智能优化
2. 数据预处理
运行之前学习过的数据预处理代码,包括:
- 导入必要的库
- 读取数据
- 特征工程(标签编码、独热编码)
- 缺失值处理
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings('ignore') #忽略警告信息,保持输出清洁。
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv(r'D:\P\yjs\PY\data.csv') #读取数据
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {
'Own Home': 1,
'Rent': 2,
'Have Mortgage': 3,
'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)
# Years in current job 标签编码
years_in_job_mapping = {
'< 1 year': 1,
'1 year': 2,
'2 years': 3,
'3 years': 4,
'4 years': 5,
'5 years': 6,
'6 years': 7,
'7 years': 8,
'8 years': 9,
'9 years': 10,
'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)
# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv(r'D:\P\yjs\PY\data.csv') # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:
if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
# Term 0 - 1 映射
term_mapping = {
'Short Term': 0,
'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
# 连续特征用中位数补全
for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。3. 数据集划分
3.1 方案一:三分法(训练集 + 验证集 + 测试集)
当不使用交叉验证时,需要划分出验证集用于调参。
# 划分训练集、验证集和测试集,因为需要考2次
# 这里演示一下如何2次划分数据集,因为这个函数只能划分一次,所以需要调用两次才能划分出训练集、验证集和测试集。
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:1:1划分训练集、验证集和测试集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%临时集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42) # 50%验证集,50%测试集# X_train, y_train (80%)
# X_val, y_val (10%)
# X_test, y_test (10%)
print("Data shapes:")
print("X_train:", X_train.shape)
print("y_train:", y_train.shape)
print("X_val:", X_val.shape)
print("y_val:", y_val.shape)
print("X_test:", X_test.shape)
print("y_test:", y_test.shape)3.2 方案二:二分法(训练集 + 测试集)⭐ 推荐
由于调参函数大多自带交叉验证,实际使用中只需要划分训练集和测试集。

# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集3.3 导入评估工具
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息4. 调参方法介绍
4.1 三种主流调参方法对比
| 方法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 网格搜索 | 穷举所有参数组合 | 能找到最优解 | 计算量大,维度灾难 | 参数空间小,计算资源充足 |
| 随机搜索 | 随机采样参数组合 | 效率高于网格搜索 | 可能错过最优解 | 参数空间大,中等计算资源 |
| 贝叶斯优化 | 基于概率模型智能搜索 | 高效,收敛快 | 实现复杂 | 参数空间大,计算资源有限 |
4.2 基线模型(Baseline)
在调参前,先建立基线模型:
- 使用默认参数训练模型
- 记录性能指标作为对比基准
- 后续调参效果以此为参照
4.3 详细说明
1️⃣ 网格搜索 (GridSearchCV)
- 需要定义参数的固定列表(param_grid)
- 尝试所有可能的参数组合
- ⚠️ 计算成本高,参数多时组合呈指数级增长
2️⃣ 随机搜索 (RandomizedSearchCV)
- 定义参数的分布范围
- 随机采样指定次数(如 50-100 次)
- ✅ 对于给定计算预算,通常比网格搜索更有效
3️⃣ 贝叶斯优化 (BayesSearchCV)
- 定义参数的搜索空间
- 根据先验结果建立概率模型(高斯过程)
- 智能选择下一个最有潜力的参数组合
- ✅ 通常用更少迭代达到更好效果
4.4 选择建议
计算资源充足 → 网格搜索
计算资源有限 → 贝叶斯优化
介于中间 → 随机搜索5. 实战:随机森林调参
使用三种方法对随机森林进行超参数优化,并对比效果。
5.1 基线模型(默认参数)
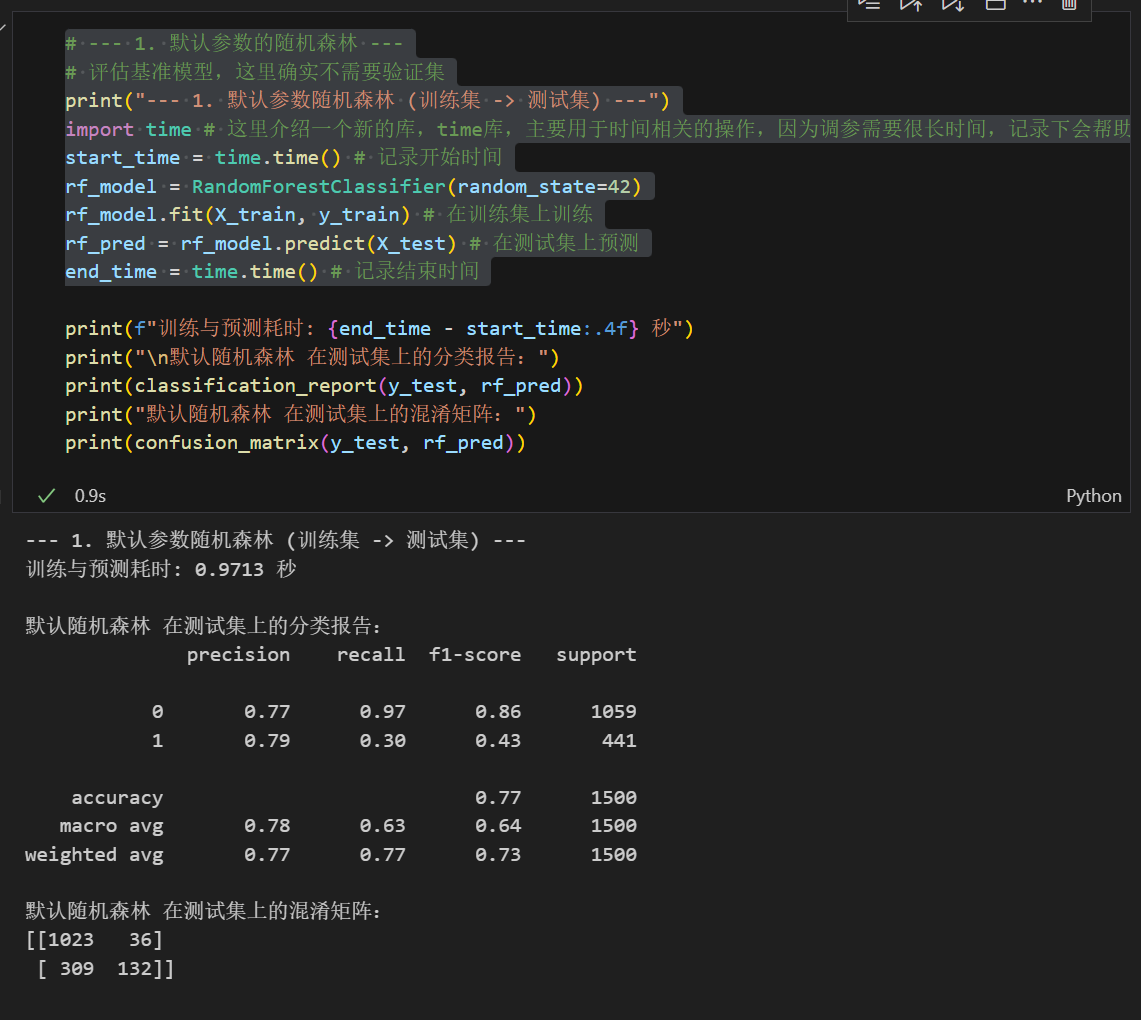
5.2 网格搜索优化
网格搜索是 scikit-learn 内置功能,无需额外安装。
网格搜索会尝试所有参数组合,计算量较大但能找到局部最优解
# --- 2. 网格搜索优化随机森林 ---
print("\n--- 2. 网格搜索优化随机森林 (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV
# 定义要搜索的参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# 创建网格搜索对象
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42), # 随机森林分类器
param_grid=param_grid, # 参数网格
cv=5, # 5折交叉验证
n_jobs=-1, # 使用所有可用的CPU核心进行并行计算
scoring='accuracy') # 使用准确率作为评分标准
start_time = time.time()
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train) # 在训练集上训练,模型实例化和训练的方法都被封装在这个网格搜索对象里了
end_time = time.time()
print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_) #best_params_属性返回最佳参数组合
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_ # 获取最佳模型
best_pred = best_model.predict(X_test) # 在测试集上进行预测
print("\n网格搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))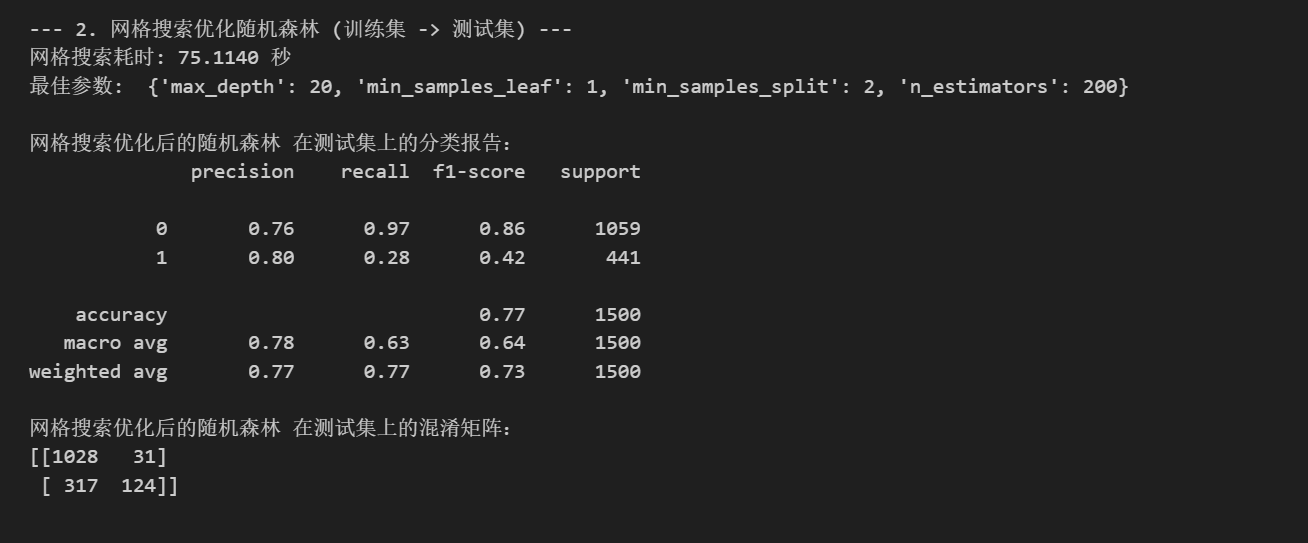
5.3 随机搜索优化
随机搜索在参数空间中随机采样,通常比网格搜索更高效。
一般用随机搜索的很少,原因是如果你一般能跑30min,那5h你就认了;如果本来需要跑10000h,那么优化到3000h你也扛不住
在复杂项目上随机优化比贝叶斯差很多,再简单场景比贝叶斯效率高,但是没必要
# --- 2. 随机搜索优化随机森林 ---
print("\n--- 2. 随机搜索优化随机森林 (训练集 -> 测试集) ---")
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
# 定义参数分布(使用分布而非固定列表)
param_distributions = {
'n_estimators': randint(50, 200), # 从50-200之间随机整数
'max_depth': [None, 10, 20, 30], # 也可以用固定列表
'min_samples_split': randint(2, 11), # 从2-10之间随机整数
'min_samples_leaf': randint(1, 5) # 从1-4之间随机整数
}
# 创建随机搜索对象
random_search = RandomizedSearchCV(
estimator=RandomForestClassifier(random_state=42),
param_distributions=param_distributions,
n_iter=50, # 随机采样50次(可调整)
cv=5, # 5折交叉验证
n_jobs=-1, # 使用所有CPU核心
scoring='accuracy',
random_state=42 # 保证结果可复现
)
start_time = time.time()
# 在训练集上进行随机搜索
random_search.fit(X_train, y_train)
end_time = time.time()
print(f"随机搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", random_search.best_params_)
# 使用最佳参数的模型进行预测
best_model_random = random_search.best_estimator_
best_pred_random = best_model_random.predict(X_test)
print("\n随机搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_random))
print("随机搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_random))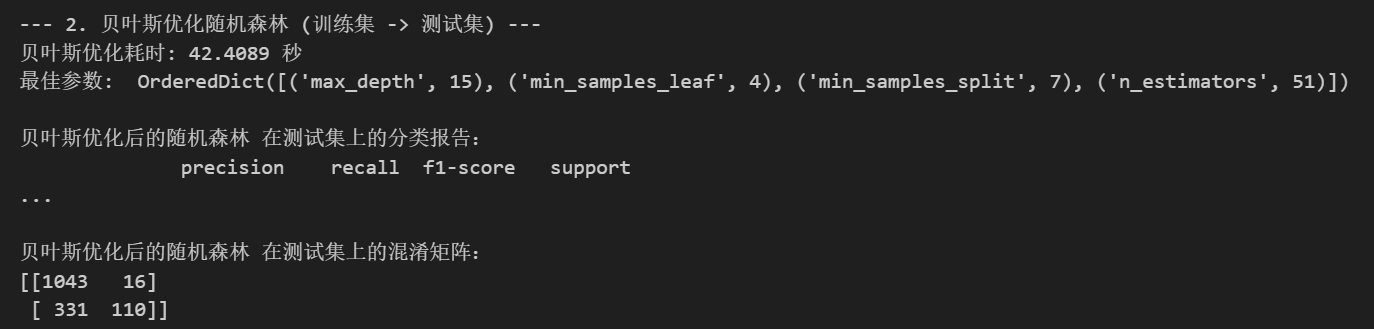
5.4 贝叶斯优化(skopt)
# pip install scikit-optimize -i https://pypi.tuna.tsinghua.edu.cn/simple
# --- 2. 贝叶斯优化随机森林 ---
print("\n--- 2. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
# 定义要搜索的参数空间
search_space = {
'n_estimators': Integer(50, 200),
'max_depth': Integer(10, 30),
'min_samples_split': Integer(2, 10),
'min_samples_leaf': Integer(1, 4)
}
# 创建贝叶斯优化搜索对象
bayes_search = BayesSearchCV(
estimator=RandomForestClassifier(random_state=42),
search_spaces=search_space,
n_iter=32, # 迭代次数,可根据需要调整
cv=5, # 5折交叉验证,这个参数是必须的,不能设置为1,否则就是在训练集上做预测了
n_jobs=-1,
scoring='accuracy'
)
start_time = time.time()
# 在训练集上进行贝叶斯优化搜索
bayes_search.fit(X_train, y_train)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)
print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))5.5 贝叶斯优化(bayesian-optimization)⭐ 进阶
方法特点
使用 bayesian-optimization 库实现,相比 skopt 有以下优势:
✅ 更灵活的自定义
- 可以自定义目标函数
- 可以选择是否使用交叉验证
- 评估指标可自由修改
✅ 更好的可视化
verbose参数可输出详细的迭代过程- 实时查看优化进度
✅ 更精细的控制
init_points:初始随机采样点数n_iter:优化迭代次数
# pip install bayesian-optimization -i https://mirrors.aliyun.com/pypi/simple/
# --- 2. 贝叶斯优化随机森林 ---
print("\n--- 2. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from bayes_opt import BayesianOptimization
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
# 假设 X_train, y_train, X_test, y_test 已经定义好
# 定义目标函数,这里使用交叉验证来评估模型性能
def rf_eval(n_estimators, max_depth, min_samples_split, min_samples_leaf):
n_estimators = int(n_estimators)
max_depth = int(max_depth)
min_samples_split = int(min_samples_split)
min_samples_leaf = int(min_samples_leaf)
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
random_state=42
)
scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
return np.mean(scores)
# 定义要搜索的参数空间
pbounds_rf = {
'n_estimators': (50, 200),
'max_depth': (10, 30),
'min_samples_split': (2, 10),
'min_samples_leaf': (1, 4)
}
# 创建贝叶斯优化对象,设置 verbose=2 显示详细迭代信息
optimizer_rf = BayesianOptimization(
f=rf_eval, # 目标函数
pbounds=pbounds_rf, # 参数空间
random_state=42, # 随机种子
verbose=2 # 显示详细迭代信息
)
start_time = time.time()
# 开始贝叶斯优化
optimizer_rf.maximize(
init_points=5, # 初始随机采样点数
n_iter=32 # 迭代次数
)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", optimizer_rf.max['params'])
# 使用最佳参数的模型进行预测
best_params = optimizer_rf.max['params']
best_model = RandomForestClassifier(
n_estimators=int(best_params['n_estimators']),
max_depth=int(best_params['max_depth']),
min_samples_split=int(best_params['min_samples_split']),
min_samples_leaf=int(best_params['min_samples_leaf']),
random_state=42
)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)
print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))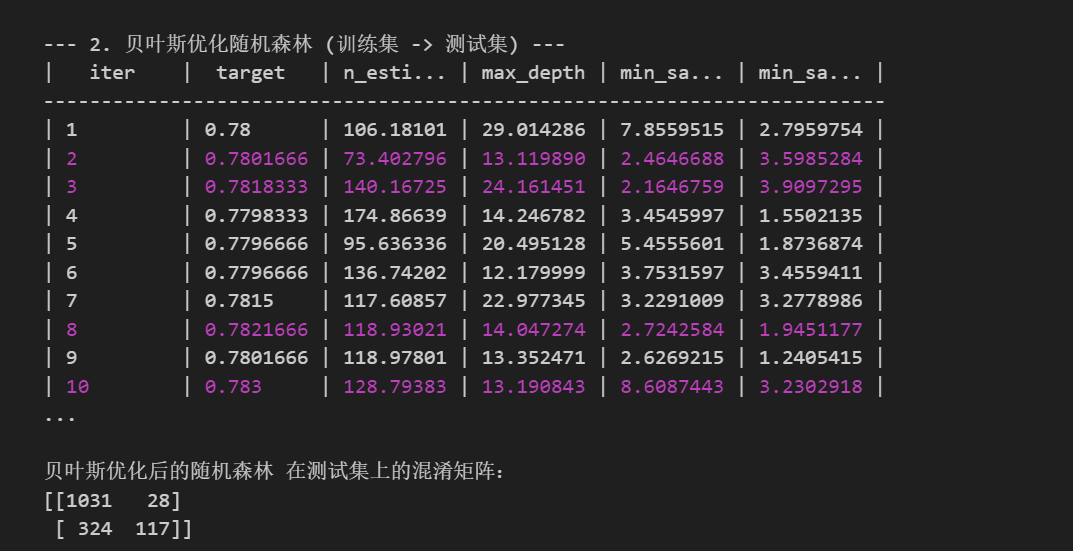
6. 总结与对比
6.1 性能对比表
基于实际运行结果的完整对比:
| 方法 | 准确率 | 精确率(类1) | 召回率(类1) | F1-Score(类1) | 耗时(秒) |
|---|---|---|---|---|---|
| 默认参数 | 0.77 | 0.79 | 0.30 | 0.43 | |
| 随机搜索 | 0.77 | 0.83 ⭐ | 0.27 | 0.40 | |
| 网格搜索 | 0.77 | 0.80 | 0.28 | 0.42 | |
| 贝叶斯优化(skopt) | 0.77 | 0.81 | 0.26 | 0.40 | |
| 贝叶斯优化(bayes-opt) | 0.76 | 0.81 | 0.26 | 0.40 |
注释:
- 精确率、召回率、F1-Score 均为正类(类1)的指标
- 类1 代表违约客户,这是我们重点关注的目标
- ⭐ 随机搜索精确率最高:0.83,说明它找到的参数在识别违约客户时最准确
6.2 最佳参数对比
| 方法 | n_estimators | max_depth | min_samples_split | min_samples_leaf |
|---|---|---|---|---|
| 默认参数 | 100 | None | 2 | 1 |
| 随机搜索 | 99 | 20 | 2 | 3 |
| 网格搜索 | 200 | 20 | 2 | 1 |
| 贝叶斯优化(skopt) | 118 | 17 | 8 | 2 |
| 贝叶斯优化(bayes-opt) | 115 | 20 | 4 | 3 |
场景1:快速原型,先用默认参数
场景2:小参数空间 → 网格搜索(穷举最优) ↓ 场景3:大参数空间 + 中等算力 → 随机搜索(效率高) ↓
场景4:大参数空间 + 有限算力 → 贝叶斯优化(skopt)(智能搜索) ↓ 场景5:需要可视化优化过程 → 贝叶斯优化(bayes-opt)(详细输出)

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









