




动手点关注 干货不迷路 👆
日前,CVPR 2022 官方公布了接收论文列表,来自字节跳动智能创作团队的 12 篇论文被 CVPR 收录,包含 1 篇 Oral(口头演讲论文)。
CVPR 全称 IEEE 国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition),该会议始于 1983 年,是计算机视觉和模式识别领域的顶级会议,每年都吸引了各大高校、科研机构与科技公司的论文投稿,许多重要的计算机视觉技术成果都在 CVPR 上中选发布。
接下来为大家分享智能创作团队 CVPR2022 收录论文的核心突破,一起来学习计算机视觉领域的最前沿研究成果吧!
基于跳舞视频的通用虚拟换装 / Dressing in the Wild by Watching Dance Videos
这篇论文由字节跳动和中山大学共同完成。
文章聚焦于真实场景中复杂人体姿势的虚拟换装任务,提出了 2D、3D 相结合的视频自监督训练模型 wFlow,在有挑战性的宽松衣服与复杂姿态上效果提升明显,可以实现全身&局部换装。同时本文构建了一个新的大规模视频数据集 Dance50k,涵盖了多种类型的服装及复杂人体姿势,以期促进虚拟换装及其他以人体为中心的图像生成研究。
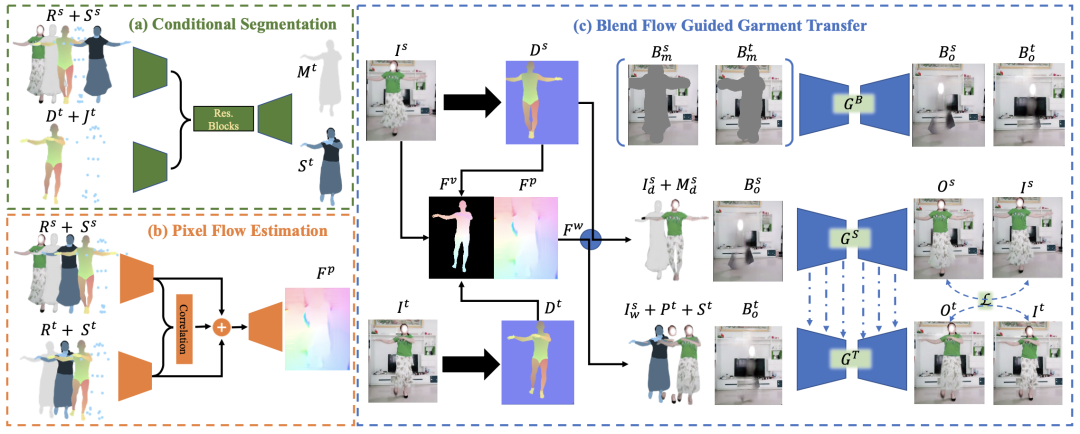
由于缺乏对人体潜在的 3D 信息感知能力及相应的多样化姿态&衣服数据集,现有的虚拟换装工作局限于简单人体姿态及贴身衣物,极大地限制了其在真实场景下的应用能力。本文通过提出一个全新的真实世界视频数据集 Dance50k,并结合引入 2D 像素流与 3D 顶点流,形成更通用的外观流预测模块 (命名为 wFlow),在解决宽松衣服变形的同时提升对复杂人体姿势的适应力。通过在 Dance50k 上进行跨帧自监督训练并对复杂例子进行在线环式优化,实验证明 wFlow 相较现有的单一像素或者顶点外观流方法在真实世界图片上泛化性更高,优于其他 SOTA 方法,为虚拟试穿提供了更为通用的解决方案。
arxiv: https://arxiv.org/abs/2203.15320
code: https://awesome-wflow.github.io/
GCFSR: 不借助人脸先验,一种生成细节可控的人脸超分方法 / GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
这篇论文由字节跳动和中国科学院先进院技术研究院共同完成。
人脸超分辨通常依靠面部先验来恢复真实细节并保留身份信息。在 GAN piror 的帮助下,最近的进展可以取得令人印象深刻的结果。他们要么设计复杂的模块来修改固定的 GAN prior,要么采用复杂的训练策略来对生成器进行微调。我们提出了一种生成细节可控的人脸超分框架,称为 GCFSR,它可以重建具有真实身份信息的图像,而无需任何额外的先验。
GCFSR 是一个编码器-生成器架构。为了完成多个放大倍率的人脸超分,我们设计了两个模块:样式调制和特征调制模块。风格调制旨在生成逼真的面部细节;特征调制会根据条件放大倍率对多尺度编码特征和生成特征进行动态融合。该架构简单而优雅,可以用端到端的方式从头开始训练。
对于较小倍率超分(<=8),GCFSR 可以在仅有的 GAN loss 的约束下产生令人惊讶的好结果。在添加 L1 loss 和 perceptual loss 后,GCFSR 可以在大倍率超分任务上(16, 32, 64)达到 sota 的结果。而在测试阶段,我们可以通过特征调制来调节生成细节的强度,通过不断改变条件放大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















 2万+
2万+



 到【灌水乐园】发言
到【灌水乐园】发言







