




文章目录
全球产品库存数据可视化及聚类分析
包含:
产品生命周期聚类分析
区域库存分布合理性
对数据进行处理,分析,可视化展示
对产品进行聚类并展示分析
1. 数据处理
1.1 导包导数据并展示
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 全局配置
pd.set_option('display.float_format', '{:.2f}'.format) # 限制浮点数显示精度
# 读取CSV文件
file_path = "/home/mw/input/kucun8458/products.csv"
df = pd.read_csv(file_path)
# 列名列表
column_names = [
'Product ID',
'Product Name',
'Product Category',
'Product Description',
'Price',
'Stock Quantity',
'Warranty Period',
'Product Dimensions',
'Manufacturing Date',
'Expiration Date',
'SKU',
'Product Tags',
'Color/Size Variations',
'Product Ratings'
]
# 更新列名
df.columns = column_names
# 优化内存使用
df = df.astype({
'Product ID': 'category',
'Product Category': 'category',
'SKU': 'category'
})
# 显示基本信息
print("数据前3行:")
df.head(3)
```
```python
print("\n数据类型:")
df.dtypes

# 查看缺失值
df.isnull().sum()

1.2 数据清洗
# 处理日期字段
df['Manufacturing Date'] = pd.to_datetime(df['Manufacturing Date'], format='%Y-%m-%d')
df['Expiration Date'] = pd.to_datetime(df['Expiration Date'], format='%Y-%m-%d')
df.head(3)

# 拆分产品尺寸
dim_split = df['Product Dimensions'].str.extract(r'(\d+)x(\d+)x(\d+)').astype(float)
df[['Length(cm)', 'Width(cm)', 'Height(cm)']] = dim_split
df = df.drop('Product Dimensions', axis=1)
df.head(3)

# 拆分颜色和尺寸
df[['Color', 'Size']] = df['Color/Size Variations'].str.split('/', expand=True)
df = df.drop('Color/Size Variations', axis=1)
df.head(3)

# 展示数据信息
df.describe()

1.3 数据分析
数据完整性:
没有缺失值。这从count行的数值均为10000可以得知。
价格分布:
平均价格为254.67。
价格的标准差较大(142.76),说明产品价格差异显著。
最低价格为10.22,最高价格达到499.97,表明产品线涵盖了从经济型到高端的不同价位。
库存情况:
平均库存量为50.65件。
库存量的标准差为28.90,显示库存水平有较大的波动。
最少库存为1件,最多库存为100件,意味着某些产品可能较为稀缺或销售较快,而有些则相对充足。
保修期概况:
平均保修期为2.01年。
标准差较小(0.82),表示大部分产品的保修期限比较接近平均值。
最短保修期为1年,最长保修期为3年,反映了不同产品在质量保证方面的差异。
用户评价:
平均评分为3分(假设满分为5分)。
评分标准差为1.42,显示出消费者对产品质量和满意度的看法存在分歧。
最低评分为1分,最高评分为5分,说明产品在用户体验上表现不一。
尺寸规格:
长度、宽度和高度的平均值分别为12.46cm、12.48cm和12.48cm。
这些维度的标准差在4.60-4.63之间,表明产品大小有一定的变化范围。
尺寸最小值为5cm,最大值为20cm,说明产品系列包括了从小型到大型的各种商品。
2. 数据可视化
2.1 各品类价格分布
# 各品类价格分布
plt.figure(figsize=(10,6))
sns.boxplot(
x='Product Category',
y='Price',
data=df,
palette='Set3'
)
plt.title('各品类价格分布', fontsize=14)
plt.xticks(rotation=45)
plt.show()

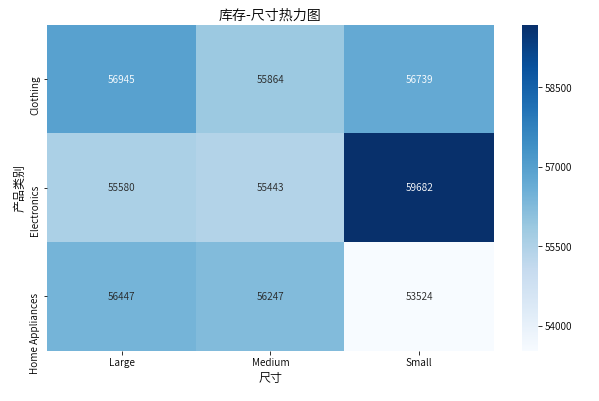
2.2 库存-尺寸热力图
# 创建热力图
plt.figure(figsize=(10,6))
stock_pivot = df.pivot_table(
index='Product Category',
columns='Size',
values='Stock Quantity',
aggfunc='sum'
)
heatmap = sns.heatmap(stock_pivot, annot=True, fmt=".0f", cmap='Blues')
# 修改横纵轴标签为中文
heatmap.set_xlabel('尺寸', fontsize=12) # 横轴标签
heatmap.set_ylabel('产品类别', fontsize=12) # 纵轴标签
# 添加标题
plt.title('库存-尺寸热力图', fontsize=14)
# 显示图形
plt.show()
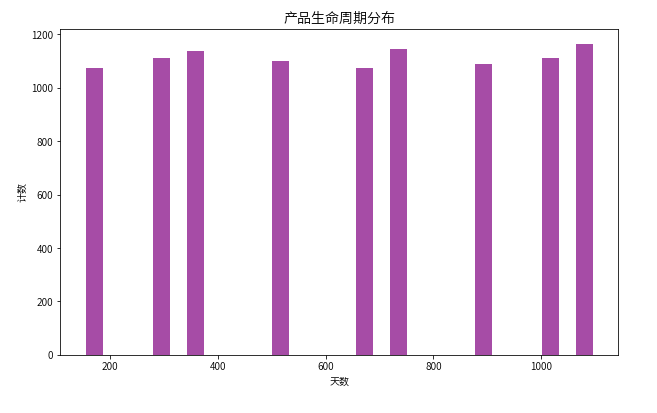
2.3 产品生命周期分布
import matplotlib.pyplot as plt
# 产品生命周期计算
df['Lifespan(days)'] = (df['Expiration Date'] - df['Manufacturing Date']).dt.days
# 创建直方图
plt.figure(figsize=(10, 6))
plt.hist(df['Lifespan(days)'], bins=30, color='purple', alpha=0.7)
plt.title('产品生命周期分布', fontsize=14)
plt.xlabel('天数')
plt.ylabel('计数')
plt.show()
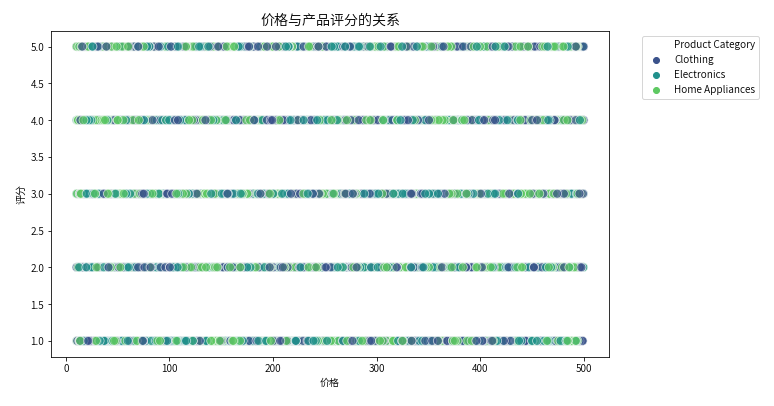
2.4 价格与产品评分的关系
plt.figure(figsize=(10,6))
sns.scatterplot(
data=df,
x='Price',
y='Product Ratings',
hue='Product Category',
palette='viridis',
alpha=0.7,
s=80
)
plt.title('价格与产品评分的关系', fontsize=14)
plt.xlabel('价格')
plt.ylabel('评分')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
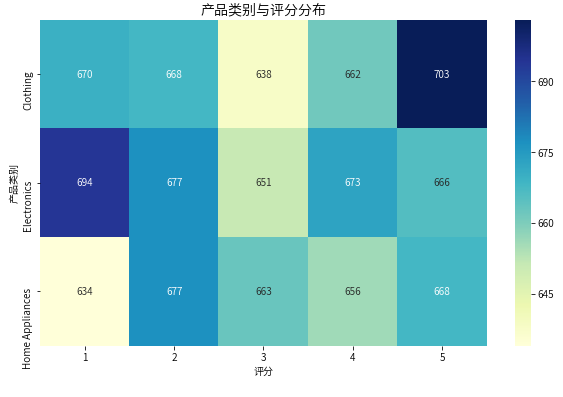
2.5 产品类别与评分分布
# 创建交叉表统计类别与评分的数量
rating_counts = pd.crosstab(df['Product Category'], df['Product Ratings'])
# 绘制热力图
plt.figure(figsize=(10,6))
sns.heatmap(rating_counts, annot=True, fmt='d', cmap='YlGnBu')
plt.title('产品类别与评分分布', fontsize=14)
plt.xlabel('评分')
plt.ylabel('产品类别')
plt.show()
3. 聚类分析
3.1 聚类前处理
包括数据处理及聚类数确认
聚类数据处理
# 计算生命周期天数(从生产到过期)
df['Lifespan(days)'] = (df['Expiration Date'] - df['Manufacturing Date']).dt.days
# 创建时间衰减因子(距离过期剩余天数占比)
df['days_remaining'] = (df['Expiration Date'] - pd.Timestamp.today()).dt.days
df['time_decay'] = df['days_remaining'] / df['Lifespan(days)']
# 构建特征矩阵
features = df[['Lifespan(days)', 'Stock Quantity', 'time_decay', 'Product Ratings']].copy()
# 处理缺失值(用中位数填充)
features = features.fillna(features.median())
# 数据标准化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
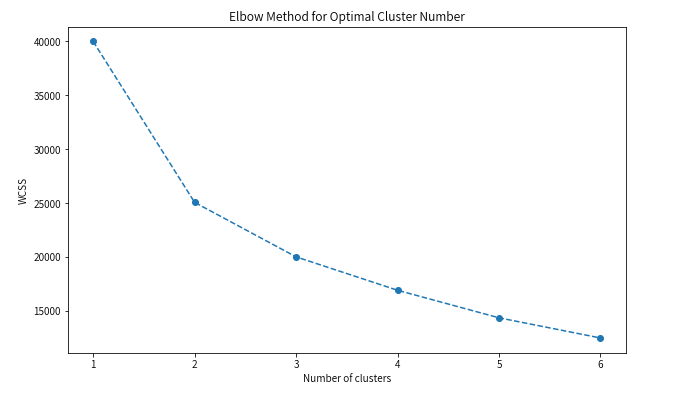
聚类数确认
确定最佳聚类数量(肘部法则)
WCSS曲线的解读原理
WCSS(Within-Cluster Sum of Squares):衡量每个数据点到其所属聚类中心的距离平方和。
变化规律:
当聚类数 k 增大时,WCSS必然逐渐减小(每个簇更小、更紧凑)。
但当 k 接近真实数据分组数量时,WCSS的下降速度会突然变缓,形成类似“手肘”的拐点。
wcss = []
for i in range(1, 7):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=42)
kmeans.fit(scaled_features)
wcss.append(kmeans.inertia_)
plt.figure(figsize=(10,6))
plt.plot(range(1,7), wcss, marker='o', linestyle='--')
plt.title('Elbow Method for Optimal Cluster Number')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
3.2 聚类
# 选择3个集群
kmeans = KMeans(n_clusters=3, init='k-means++', random_state=42)
clusters = kmeans.fit_predict(scaled_features)
# 将聚类结果添加到数据中
df['lifecycle_cluster'] = clusters
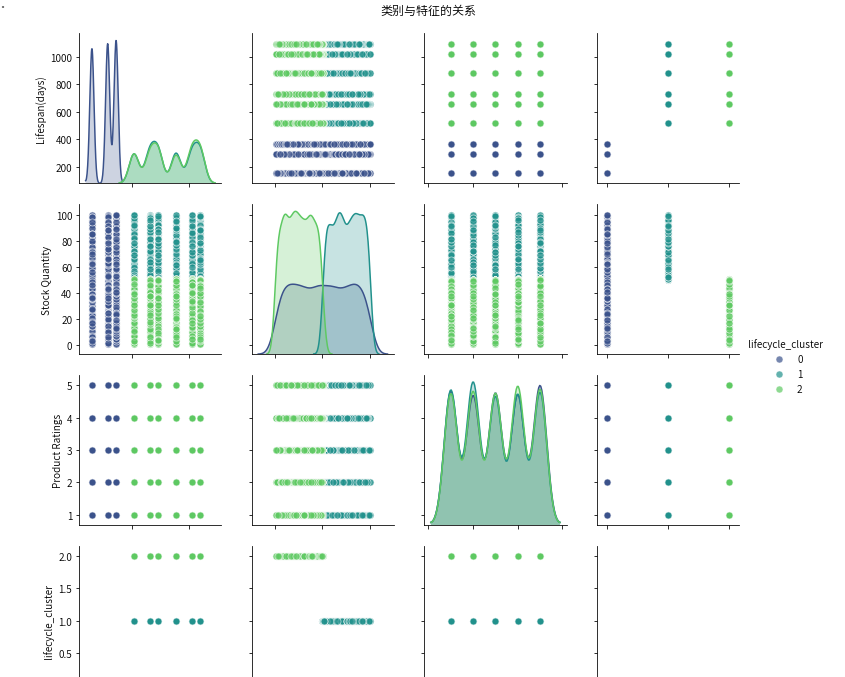
3.3 结果展示
import seaborn as sns
# 选择关键特征
plot_features = df[['Lifespan(days)', 'Stock Quantity', 'Product Ratings', 'lifecycle_cluster']]
# 绘制散点图矩阵
sns.pairplot(
plot_features,
hue='lifecycle_cluster',
palette='viridis',
plot_kws={'alpha': 0.7, 's': 50},
diag_kind='kde'
)
plt.suptitle('类别与特征的关系', y=1.02)
plt.show()
3.4 聚类特征描述
cluster_profile = df.groupby('lifecycle_cluster').agg({
'Lifespan(days)': 'median',
'Stock Quantity': 'median',
'time_decay': 'mean',
'Product Ratings': 'median',
'Price': 'median'
}).reset_index()
print("\n聚类特征描述:")
display(cluster_profile.style.background_gradient(cmap='Blues'))

4. 聚类后得出结论
生命周期分层明显:
聚类0(短周期):292天
聚类1(中周期):731天
聚类2(长周期):886天
库存策略差异显著:
0 50 中等库存,匹配较短生命周期
1 76 高库存风险,需关注是否滞销
2 25 低库存,适合长周期产品策略
评分与价格无明显区分


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









