




 论文提出VGCL模型,利用变分推理和GNN探索用户-物品图的高阶结构,通过个性化数据增强和多视角对比学习改进协同过滤。实验结果显示VGCL在推荐性能上有优势,但参数调优复杂。
论文提出VGCL模型,利用变分推理和GNN探索用户-物品图的高阶结构,通过个性化数据增强和多视角对比学习改进协同过滤。实验结果显示VGCL在推荐性能上有优势,但参数调优复杂。
论文名称:Generative-Contrastive Graph Learning for Recommendation
论文链接:https://le-wu.com/files/Publications/CONFERENCES/SIGIR-23-yang.pdf
Tips:本文需要一定的变分自编码器(VAE)和变分图自编码器(VGAE)的知识,可以先参阅以下论文:
https://arxiv.org/abs/1312.6114
https://arxiv.org/abs/1611.07308
背景
图对比学习(graph contrastive learning,GCL)技术已经在协同过滤任务中被广泛应用。GCL通过数据增强来构建不同的对比视图(view),随后通过最大化对比视图之间的互信息来提供自监督信号。
尽管有效,但目前基于GCL的推荐系统仍然局限于数据增强技术(结构增强或特征增强)。具体来说,结构增强随机丢弃节点或者边,这很容易破坏用户-物品交互图的内在性质;特征增强为每个节点施加噪声,忽略了图中节点的特性。在真实世界的推荐系统中,不同的用户/物品具有不同的特征,数据增强应该针对这些情况进行个性化定制。
VGCL
针对上述问题,作者提出了变分图生成-对比学习模型(Variational Graph Generative-Contrastive Learning,VGCL),其核心思想是利用变分推理思想近似输入数据点的高斯分布,并根据该分布重构所有输入数据。VGCL的模型图如下:
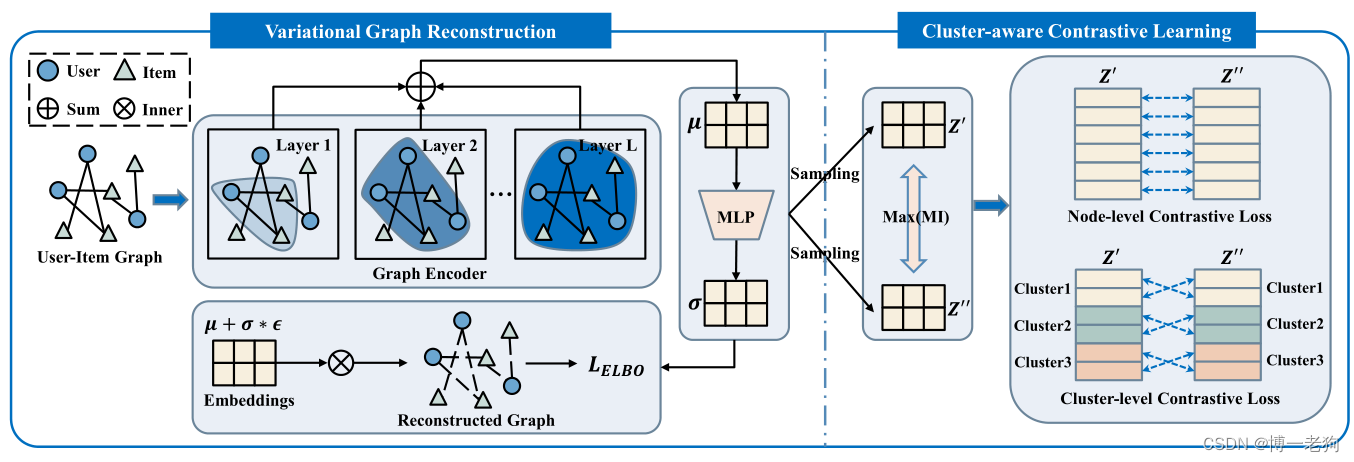
编码
在VGCL中,给定输入的用户
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









