




RecDCL: Dual Contrastive Learning for Recommendation
论文链接:RecDCL: Dual Contrastive Learning for Recommendation | Proceedings of the ACM on Web Conference 2024
代码链接:GitHub - THUDM/RecDCL: RecDCL: Dual Contrastive Learning for Recommendation (WWW'24, Oral)
简介
自监督推荐(Self-supervised recommendation,SSR)在协同过滤任务中展示了巨大的成功。其中一个重要分支——对比学习(contrastive learning,CL)通过对比原始数据和增强数据的嵌入来缓解推荐的数据稀疏问题。然后,现有的基于CL的SSR方法大多数直观一个batch的对比,而没有探索特征维度的潜在规律。此外,在推荐场景,还没有工作考虑过基于batch的对比(BCL)和基于特征的对比(FCL)。因此,本文提出了用于推荐的双对比方法,简称为RecDCL。
预备知识
协同过滤
设用户、物品和用户-物品二部图的符号分别是U、I和G。协同过滤模型致力于排序所有物品,并预测用户可能会交互的新物品。目前,用于协同过滤的流程框架是GCN。给出用户u和物品i,GCN致力于迭代地执行邻居信息传播和聚合,以此更新交互图G上的所有节点。最后用户和物品的排序分数使用内积进行计算。目前的流行优化策略是使用成对化优化损失(例如Bayesian Personalized Ranking):
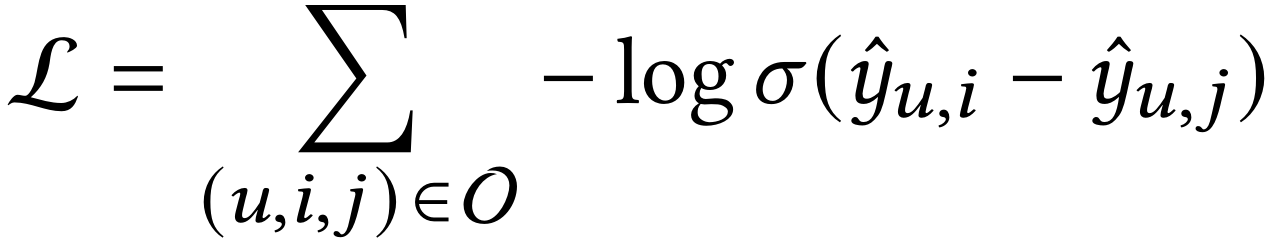
其中O是训练数据,u、i和j分别是用户u、正样本i(用户u交互过的物品)和负样本j(物品u没有交互过的物品),σ是非线性激活函数。
Batch-wise Contrastive Learning(BCL)
最近的趋势是采用自监督学习中的对比学习进一步提升协同过滤模型的性能。其核心思想是通过数据增强构造原始数据的新视角,并且通过InfoNCE损失来增强同一节点的不同视角的一致性:
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2992
2992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









