






 本文介绍了如何使用PyTorch加载模型时,通过`model.named_modules()`方法获取模型的所有模块名称,以及如何使用`model.named_parameters()`和`model.parameters()`来分别获取有权值的模块及其参数。展示了如何查看模型的权值并打印特定部分的参数。
本文介绍了如何使用PyTorch加载模型时,通过`model.named_modules()`方法获取模型的所有模块名称,以及如何使用`model.named_parameters()`和`model.parameters()`来分别获取有权值的模块及其参数。展示了如何查看模型的权值并打印特定部分的参数。
调用模型的named_modules()方法
import torch
model_path = ''
model = torch.load(model_path )
named_modules = model.named_modules()## 获取所有模块的名称
name_params = model.named_parameters()## 获取有权值的模块的名称及其权值
params = model.parameters()## 只有权值
print(dir(model))
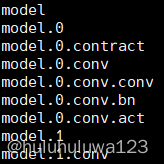
for k, v in model.named_modules():
print(k)
输出:
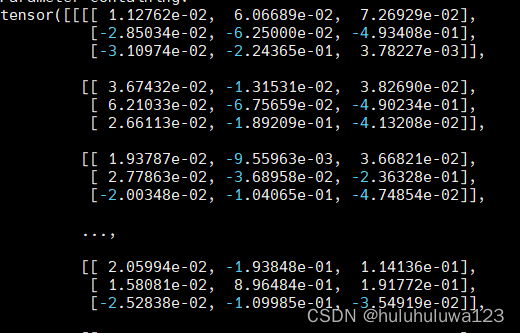
查看模型权值model.parameters()
for k in model.parameters():
print(k)
输出:

















 1325
1325




 到【灌水乐园】发言
到【灌水乐园】发言







