






LiRaFusion是密歇根大学在2024年发表在ICRA上的一篇论文
论文地址 :LiRaFusion
前言
在3D检测种由于 Lidar 达和摄像头对不断变化的天气和照明条件很敏感,因此引入了成本低、探测距离长和多普勒效应信息的雷达系统。
本文提出一种使用门控网络对提取到的特征进行融合,利用 Lidar 和 Radar 的互补信息进行3D物体检测的网络架构。

一、Method
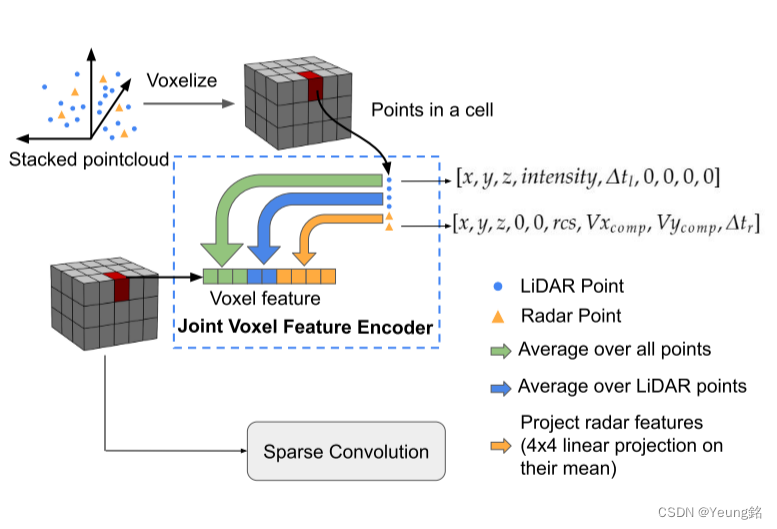
该方法的提出是为了对 Lidar 和 Radar 数据进行更有效的特征提取和融合,以便进行特征提取。网络架构如图所示: 从堆叠点云中提取到每个体素的特征,利用 PointPillar 处理 Radar 特征,通过 Middle Fusion 中门控网络自适应的学习两个特征图的自适应权重,进行进一步的融合,生成新的特征图进行下流任务。
从堆叠点云中提取到每个体素的特征,利用 PointPillar 处理 Radar 特征,通过 Middle Fusion 中门控网络自适应的学习两个特征图的自适应权重,进行进一步的融合,生成新的特征图进行下流任务。
Early Fusion
在 Early Fusion 中为了将 Lidar 和 Radar 相融合,提取每个体素单元的特征。本文保留了LiDAR 强度、雷达截面(RCS)和速度等特征,作者认为LiDAR强度和RCS有助于对物体进行分类,而速度信息对于区分静态或动态物体以及预测速度和旋转很重要。
we keep these features since LiDAR intensity and RCS are helpful to classify objects, and velocity information is important to distinguish static or dynamic objects and predict the velocity and rotation and velocity information is important to distinguish static or dynamic objects and predict the velocity and rotation.
对于 Lidar 点保留了点的强度和 captured time offset (
∆
t
l
∆t_l
∆tl),对于 Radar 点则保留了RCS和补偿速度 (
V
x
c
o
m
p
V_{x_{comp}}
Vxcomp 、
V
y
c
o
m
p
V_{y_{comp}}
Vycomp ) 和时间偏移 (
Δ
t
r
Δt_r
Δtr)。由于两种模态对应的维度不同,则采取零填充的方法来对齐二者之间的维度,用于后续的特征融合。
将堆叠之后的 Lidar 和 Radar 点云进行体素化。通过 VoxelNet Encoder 提取每个体素单元的特征。本文保持了输出的维度和输入的维度相同。前三个维度表示了该单元内的质心坐标(体素单元内所有点的平均位置),接下来两个维度表示 Lidar 的特征(对所有的 Lidar 点求平均),最后四个维度对应着 Radar 的特征,(将 Radar 特征的平均值送入到一个 4 × 4 的线性层,使得网络学习处理 Radar 的方法,由于 Radar 具有稀疏性,只针对非空体素进行处理,对于空体素将最后四个维度保留为0)。在获得体素特征之后,通过稀疏卷积、VoxelNet 进行进一步处理。网络具体架构如图所示:
Middle Fusion
虽然在 Early Fusion 的时候已经将 Lidar 和 Radar 数据进行了融合,但是由于 Radar 数据的稀疏性,通过体素编码的特征中大部分的信息仍然还是来自 Lidar,因此本文通过 Middle Fusion 进一步与 Radar 融合。
通过引入门控网络自适应的学习通道维度上的权重。之前权重形状为 B×1×H×W 代表着每个位置的特征权重是相同的,不考虑不同通道之间的差异,本文将其修改为 B×C×H×W,考虑不同通道之间的差异性 。
输入LiDAR 特征图(B×C1×H×W)和输入 Radar 特征图(B×C2×H×W)首先在通道维度上串联。 然后,得到的新特征图被传递到一个卷积块,后面跟一个 sigmoid 函数。 值得注意的是,LiDAR 和 Radar 模态的卷积块的输出特征维度设置为与输入特征图的维度匹配(LiDAR 为 C1,Radar 为 C2)。 通过逐元素乘积运算将学习到的自适应权重应用于原始输入特征图。 获得的门控 LiDAR 和 Radar 特征进一步沿特征维度连接在一起作为融合特征图。 得到的融合特征图的形状为 B × (C1 + C2) ×H ×W 并作为中间融合块的输出。网络具体架构如图所示:

总结
这篇论文提出了一种对 Lidar 和 Radar 网络进行特征提取,通过门控网络自适应的融合不同模态的特征的 backbone。
本文是自己对论文的理解,如有不同见解,欢迎讨论、指正。

















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









