



目 录
摘 要
在当前就业市场竞争日益激烈的背景下,企业和求职者都面临着信息繁杂、匹配效率低下的问题。传统的人工筛选简历方式不仅耗时费力,而且容易遗漏合适人选;而求职者也常常在海量招聘信息中难以快速找到适合自己的岗位。因此提出了一个基于聚类算法的简历筛选系统,通过技术手段提高人岗匹配的效率和准确性。
本系统采用Flask框架进行开发,整体界面简洁、功能清晰。系统主要分为两个角色:求职用户和管理员。求职用户可以注册登录,浏览新闻资讯和通知公告,并且系统会根据用户的点击、点赞等行为,并通过聚类矩阵算法实现个性化招聘信息推荐,系统根据用户的点击、点赞等行为动态调整推荐内容,提高岗位匹配效率。用户还可以管理个人资料、上传修改简历、查看申请记录和面试通知等。管理员则拥有更全面的后台管理功能,包括对用户、职位、简历、通知、权限等方面的管理和统计分析。整个系统设计注重实用性与智能化,为求职者和企业提供了更加高效、便捷的服务。
关键词:Flask框架,简历筛选系统,聚类算法。
In the context of increasingly fierce competition in the current job market, both enterprises and job seekers are facing the problems of complex information and low matching efficiency. The traditional manual resume screening method is not only time-consuming and laborious, but also prone to missing suitable candidates; And job seekers often find it difficult to quickly find suitable positions among the massive recruitment information. Therefore, a resume screening system based on clustering algorithm was proposed to improve the efficiency and accuracy of job matching through technical means.
This system is developed using the Flask framework, with a simple overall interface and clear functionality. The system is mainly divided into two roles: job seeking users and administrators. Job seeking users can register and log in, browse news and notifications, and the system will implement personalized recruitment information recommendations based on user clicks, likes, and other behaviors through clustering matrix algorithms. The system dynamically adjusts the recommended content based on user clicks, likes, and other behaviors to improve job matching efficiency. Users can also manage personal information, upload and modify resumes, view application records, and interview notifications. Administrators have more comprehensive backend management functions, including management and statistical analysis of users, positions, resumes, notifications, permissions, and other aspects. The entire system design emphasizes practicality and intelligence, providing more efficient and convenient services for job seekers and enterprises.
Keywords: Flask Framework, Resume Filtering System, Clustering Algorithm.
- 绪 论
- 研究背景及意义
随着互联网的普及,传统的招聘模式面临着前所未有的挑战。企业与求职者之间的信息交流日益频繁,招聘信息和求职简历的数量呈爆炸式增长。面对如此庞大的数据量,传统的人工筛选方式显得力不从心,不仅效率低下,而且容易出现误筛漏筛的情况。在招聘高峰期,HR需要处理大量的简历,而求职者则在海量的职位信息中迷失方向。为了应对这些问题,利用创新的技术手段提升简历筛选的效率和准确性显得尤为重要。基于聚类算法的简历筛选系统应运而生,通过智能化的方式优化招聘流程,提高人岗匹配的精准度。
本研究所开发的基于聚类算法的简历筛选与推荐系统,对于改善现有的招聘生态具有重要意义。系统为企业提供了一种高效筛选简历的方法,大大减轻了HR的工作负担,使他们能够更专注于候选人的综合评估。系统为求职者提供了更加个性化的职位推荐服务,根据用户的点击、点赞等行为进行动态调整,帮助用户更快找到心仪的工作岗位。系统设计考虑到了易用性和可扩展性,采用Flask框架构建,使得系统的维护和升级变得简单快捷。这不仅提升了用户体验,也为后续的功能扩展奠定了坚实的基础。综上所述,本研究为优化招聘流程、提升人力资源管理效率开辟了新的路径,并对相关领域的实践提供了宝贵的借鉴经验。
在国内,随着互联网招聘平台的快速发展,越来越多的研究开始关注如何利用技术手段提升简历筛选和岗位推荐的效率。近年来,不少学者和企业基于传统算法(如协同过滤、关键词匹配、决策树等)设计了多种简历筛选与职位推荐模型。部分招聘网站已初步引入聚类分析方法,用于对求职者进行分类管理或对企业岗位需求进行标签化处理,以提高匹配效率。一些高校也在探索结合用户行为数据优化推荐策略的方法,尝试从用户体验角度提升系统的智能化水平。总体来看,国内相关系统在算法优化、个性化推荐以及多维度数据分析方面仍有较大提升空间,特别是在精准匹配和实时推荐方面的应用还处于不断完善的阶段。
在国外,智能招聘系统的研究起步较早,许多大型科技公司和人力资源服务机构已经广泛应用机器学习、自然语言处理等技术来改进招聘流程。例如,LinkedIn 和 Glassdoor 等平台通过构建用户画像和岗位特征模型,实现较为成熟的职位推荐功能。在学术研究方面,国外学者在聚类分析、文本挖掘、推荐系统等领域已有较为深入的探索,并提出了如K-means、DBSCAN等多种聚类算法在简历筛选中的应用方案。同时,一些研究还结合用户交互行为数据,构建动态推荐机制,以提升系统的智能化水平。尽管如此,由于文化背景、就业市场及数据隐私保护政策的不同,国外的研究成果并不能直接应用于我国的招聘场景,仍需结合本土实际进行适应性改进与创新。
本论文共分为七个主要章节,具体结构如下:
1. 绪论:介绍研究背景与意义,回顾国内外研究现状,并概述论文的组织结构。
2. 相关技术介绍:本章节将对简历筛选系统的实现关键技术进行简要介绍。
3. 需求分析:对系统的功能需求和非功能需求进行分析,明确用户和管理员的需求,并进行可行性分析,包括技术、操作和经济可行性。
4. 系统设计:涵盖系统架构设计、系统模块设计,并进行数据库的概念设计与表设计。
5. 系统实现:具体描述各个功能模块的实现过程,展示系统如何根据需求进行开发。
6. 系统测试:阐述测试的目的,分析测试结果并得出结论,以验证系统的稳定性和功能完整性。
7. 总结:总结研究的主要成果和贡献,指出存在的不足及未来的研究方向。
B/S体系[1],即Browser/Server体系,是一种常见的网络应用程序架构。其工作原理基于客户端与服务器之间的请求-响应模型。用户通过浏览器向服务器发送请求,服务器接收到请求后进行处理,并生成相应的响应结果,最终将响应返回给客户端。浏览器接收到服务器返回的响应后,解析其中的标记语言(如HTML[2]),并根据CSS样式表和PythonScript脚本来渲染页面,呈现给用户。用户可以与页面进行交互,例如点击链接、填写表单等操作,这些操作会触发新的请求,循环执行上述过程。
Flask是一个使用Python编写的轻量级Web应用框架[3]。它设计简单,易于扩展,非常适合开发小型到中型的Web应用。Flask的核心非常简洁,只包含基本的路由和WSGI(Web Server Gateway Interface)功能,但可以通过扩展来增加其他功能,如数据库支持、表单处理、会话管理等。
Flask的灵活性是其一大特点。开发者可以自由地选择和使用各种第三方库和扩展,以满足项目的特定需求。这种灵活性使得Flask能够很好地适应不同的开发场景和项目规模[4]。
Flask还拥有一个活跃的社区和丰富的文档资源。社区中的开发者们积极分享经验、解决问题,为新手提供了良好的学习环境和支持。文档则详细记录了Flask的使用方法和最佳实践,帮助开发者更快地掌握和应用这个框架。
MySQL是一种广泛使用的开源关系型数据库管理系统[5](RDBMS),其稳定性、可靠性和卓越性能使其成为众多应用程序的首选数据库。MySQL支持标准SQL语法,并提供丰富的功能和特性,如事务处理、触发器和存储过程等,以满足开发者对数据管理和操作的需求。MySQL具有良好的可扩展性,支持主从复制、分布式架构和集群部署,适用于各种规模和负载的应用场景。作为一个开源项目,MySQL拥有庞大的用户社区和活跃的开发者社区,为用户提供了丰富的文档、教程和支持资源。总之,MySQL是一款可靠、强大且灵活的关系型数据库管理系统[6],通过其卓越性能和可扩展性,帮助开发者高效地管理和操作数据,并得到了广大用户的认可和应用。
Python是一种简洁易读、跨平台且功能强大的编程语言[7]。它拥有庞大而活跃的社区,提供了丰富的第三方库和框架,如NumPy、Pandas和flask,使开发人员能够快速构建各种应用程序。Python在数据处理和科学计算方面表现出色,通过相关库和工具,可以进行数据分析、机器学习和科学计算等任务。此外,Python广泛应用于Web开发[8]、自动化脚本、网络爬虫等领域,其多样性使其成为一个全能的编程语言。无论你是初学者还是有经验的开发者,Python的简单语法、跨平台性以及强大的社区支持都能为你提供高效、优雅和可靠的编程体验。总之,Python是一个强大而灵活的编程语言,深受开发人员喜爱,并在各个领域得到广泛应用。
在技术可行性方面,选定Python作为开发语言,并结合相应的框架Flask,以实现系统的功能需求。Python作为一种简洁而强大的编程语言,拥有丰富的库支持和成熟的开发社区,能够满足简历筛选系统的开发需求。Flask作为Python的Web框架,提供了高度可扩展的开发环境,使得系统的设计和实现更为便捷和高效。
本系统开发过程中采用了开源技术栈,有效降低了软件授权费用及工具采购成本。通过应用Flask框架,简化了开发流程,缩短了项目周期,并减少了人力资源的投入。此外,利用云计算资源部署系统,能够根据实际需求灵活调整服务器配置,从而进一步降低硬件成本。
随着互联网的发展和招聘行业的数字化转型,在线招聘平台的需求不断增加。Flask框架具有高效性和灵活性,能够处理大量用户数据和招聘信息发布,保证系统在高并发情况下的稳定运行。结合Vue.js和MySQL等技术,可为用户提供友好的操作界面和高效的数据支持,提升招聘服务的质量与管理效率,具备良好的社会应用前景。
在操作可行性方面,本系统的设计注重用户体验,采用了直观且易于使用的界面设计,并提供了详尽的帮助文档支持,确保用户能够轻松掌握各项功能的使用。无论是普通用户还是后台管理员,均能通过清晰明了的操作流程完成信息查询与管理等任务。因此,从用户操作的角度来看,本系统展现了卓越的操作可行性。
简历筛选系统划分为了前端模块和后端模块两大部分。
前端求职用户模块:
注册登录:用户可通过手机号或邮箱完成注册,并通过账号密码进行安全登录,确保个人信息的安全性。
首页:展示平台核心信息,如热门岗位、推荐职位、快速入口等功能模块,提升用户使用便捷度。
通知公告:浏览平台发布的最新动态、政策信息及重要通知,增强用户对平台活动的了解。
新闻资讯:提供与就业市场、行业发展相关的资讯内容,帮助用户了解行业趋势,辅助职业规划。
招聘信息:系统采用聚类矩阵算法,根据用户的点击、点赞、收藏等行为数据,智能推荐与其兴趣和能力匹配的岗位信息,实现个性化推荐服务。
我的账户:支持用户查看和编辑个人资料、修改密码、切换账号或退出登录,保障账户安全与个性化设置。
个人中心:整合用户核心操作功能,包括个人首页展示、职位申请记录查询、面试安排通知、系统消息提醒、简历管理、收藏岗位以及评论内容管理等,方便用户一站式管理求职相关事务。
后端管理员模块:
登录:管理员通过专属账号和密码安全登录后台管理系统,确保系统的安全性。
系统首页:包含个人信息查看与修改、密码更新等功能,提供网站首页快捷入口、退出登录选项,以及对申请记录和活动报告的统计概览,便于快速掌握系统运行状态。
系统用户:管理员可以查看、添加、编辑或删除系统内的用户信息,进行用户权限分配等操作,确保平台用户数据的安全性和准确性。
招聘信息管理:包括发布新职位、编辑现有职位信息、删除过期或不合适的信息,确保招聘信息的准确性和时效性。
职位类型管理:定义和维护不同职位类型的分类标准,支持新增、修改或删除职位类别,有助于提高岗位信息的组织性和可查找性。
申请记录管理:对求职者的职位申请记录进行管理和查询,提供数据分析支持,帮助了解招聘效果。
面试信息管理:录入、更新和管理面试安排及相关信息,确保面试流程的顺利进行。
通知消息管理:发布系统公告、重要通知给所有用户或特定用户群体,保持信息流通的有效性。
活动报告管理:生成并管理关于系统使用情况、用户活跃度等的活动报告,为决策提供依据。
个人简历管理:管理员有权访问和管理平台上所有用户的简历,以支持审核、推荐等操作。
系统管理:管理员可以上传、编辑或删除首页轮播图内容,增强网站视觉吸引力和信息传达效果。
通知公告管理:管理员发布和管理网站的通知公告,确保用户能够及时获取最新资讯。
资源管理:管理员维护新闻资讯及其分类,保证平台提供的行业动态和资讯信息的准确性和多样性。
权限管理:管理员设置不同角色的权限,控制用户对系统各功能模块的访问权限,保障系统安全。
简历筛选系统的非功能性需求比如简历筛选系统的安全性怎么样,可靠性怎么样,性能怎么样,可拓展性怎么样等,具体可以表示在如下3-1表格中:
表3-1简历筛选系统非功能需求表
| 安全性 | 主要指简历筛选系统数据库的安装,数据库的使用和密码的设定必须合乎规范。 |
| 可靠性 | 可靠性是指简历筛选系统能够安装用户的指示进行操作,经过测试,可靠性90%以上。 |
| 性能 | 性能是影响简历筛选系统占据市场的必要条件,所以性能最好要佳才好。 |
| 可扩展性 | 比如数据库预留多个属性,比如接口的使用等确保了系统的非功能性需求。 |
| 易用性 | 用户只要跟着简历筛选系统的页面展示内容进行操作,就可以了。 |
| 可维护性 | 简历筛选系统开发的可维护性是非常重要的,经过测试,可维护性没有问题 |
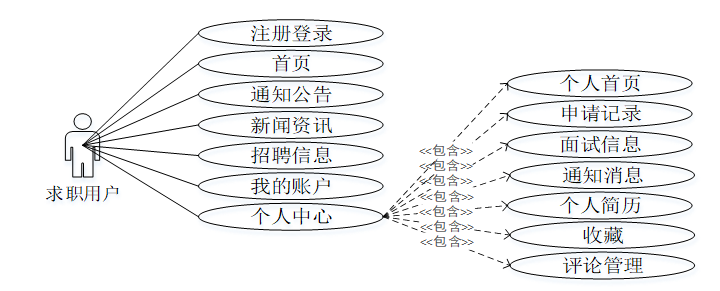
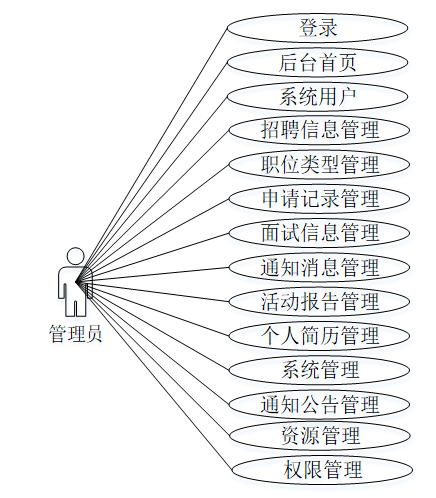
简历筛选系统的完整UML用例图分别是图3-1、3-2。
求职用户角色用例如下图所示。
-
-
-
-
- 简历筛选系统求职用户角色用例图
-
-
-
管理员角色用例如下图所示。
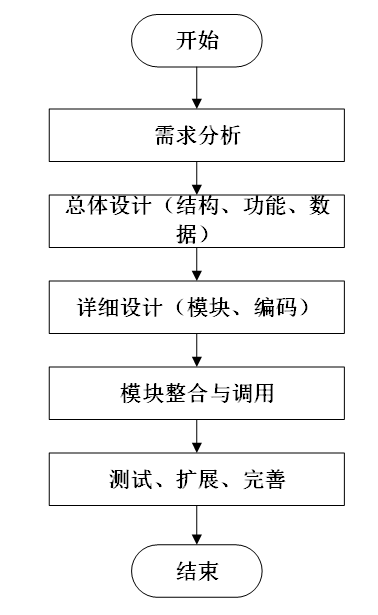
系统开发流程的主要步骤,从需求分析到系统完成的全过程。流程包括需求分析、总体设计(结构、功能、数据)、详细设计(模块、编码)、模块整合与调用,以及测试、扩展和完善,最终完成系统的开发。本系统的开发流程如下图所示
-
-
-
-
- 系统开发流程图
-
- 用户登录流程
-
-
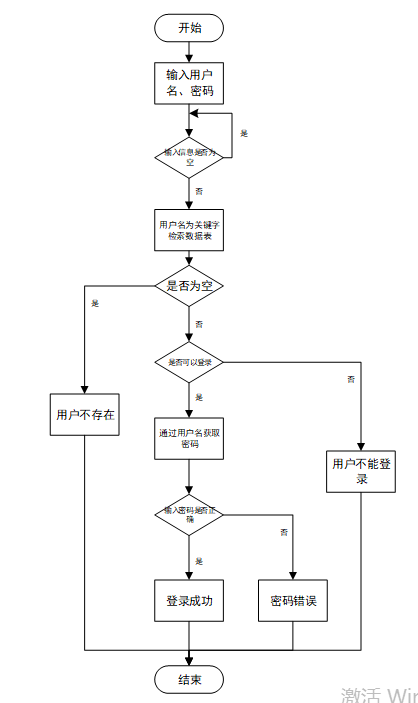
用户输入用户名和密码后,系统先检查输入是否为空,再验证用户名是否存在,若存在则通过用户名获取密码并校验。若密码正确则登录成功,否则提示密码错误。若用户名不存在或无法登录,提示用户操作无效。如下图所示。
-
-
-
-
- 登录流程图
-
- 系统操作流程
-
-
用户首先进入系统登录界面,输入用户名和密码后,系统验证信息是否正确。若验证失败,返回登录界面重新输入,若验证成功,则进入功能界面,执行相应功能处理后结束操作流程。操作流程如下图所示。
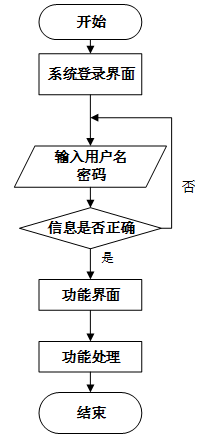
-
-
-
-
- 系统操作流程图
-
- 添加信息流程
-
-
管理员可以添加信息,用户添加可以自己权限内的信息,输入信息后,要想利用这个软件来进行系统的安全管理,首先需要登录到该软件中。添加信息流程如下图所示。
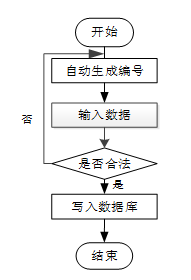
-
-
-
-
- 添加信息流程图
-
-
-
用户首先选择需要修改的记录,输入修改后的数据,系统判断输入数据是否合法。若数据不合法,提示重新输入,若数据合法,则将修改后的数据写入数据库,完成操作后流程结束。修改信息流程图如下图所示。
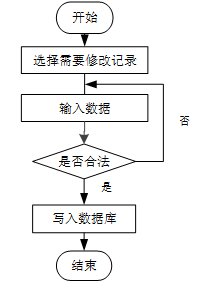
-
-
-
-
- 修改信息流程图
-
- 删除信息流程
-
-
用户选择需要删除的记录后,系统判断是否确认删除。若未确认,返回选择环节,若确认删除,则更新数据库,删除对应记录,完成操作后流程结束。删除信息流程图如下图所示。
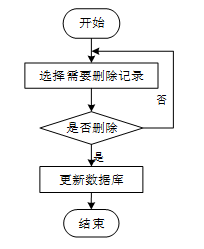
-
-
-
-
- 删除信息流程图
-
- 用户预订操作流程
-
-
当用户登录系统的时候,浏览旅游资源,查看详情并进行预订,管理员在后端处理预订。用户预订资源操作流程如图下所示。
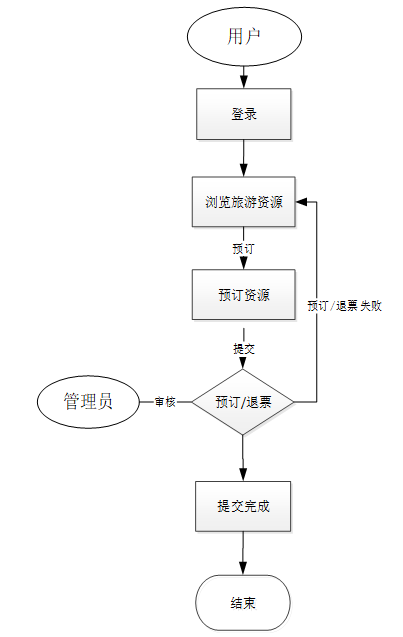
-
-
-
-
- 操作流程图
-
-
-
- 总体设计
本章主要讨论的内容包括简历筛选系统的功能模块设计、数据库系统设计。
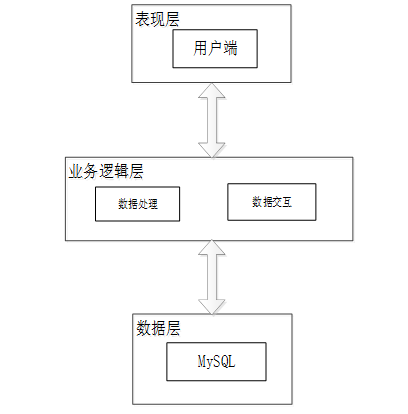
本简历筛选系统从架构上分为三层:表现层(UI)、业务逻辑层(BLL)以及数据层(DL)。
-
-
-
-
- 简历筛选系统架构设计图
-
-
-
表现层(UI):也称为用户界面层,它负责与用户进行直接的交互。一个优秀的UI设计能够显著提升用户的体验,确保用户在使用简历筛选系统时感到舒适和便捷。为了确保良好的兼容性,UI界面设计需要适应不同版本的平台和各种屏幕尺寸的分辨率。此外,UI交互功能必须合理设计,确保用户的操作能够得到相应的反馈和结果,这要求表现层与业务逻辑层之间保持良好的通信和协同工作。
业务逻辑层(BLL):这一层主要处理简历筛选系统的数据和业务逻辑。当用户通过表现层提交数据时,业务逻辑层会接收这些数据,进行处理,并将结果传递给数据层进行存储或查询。同时,当系统需要从数据层读取数据时,业务逻辑层会处理这些数据,并将其传递给表现层进行展示。
数据层(DL):虽然本简历筛选系统的数据存储在服务端的MySQL数据库中,但数据层仍然作为一个独立的部分存在。它的主要功能是存储和管理简历筛选系统的数据。数据层与MySQL数据库进行交互,执行数据的增、删、改、查等操作,确保数据的完整性和安全性。
这三个层次相互独立但又紧密协作,共同构成了简历筛选系统的完整架构。通过合理的分层设计,可以提高系统的可维护性、可扩展性和可重用性,为用户提供更好的服务和体验。
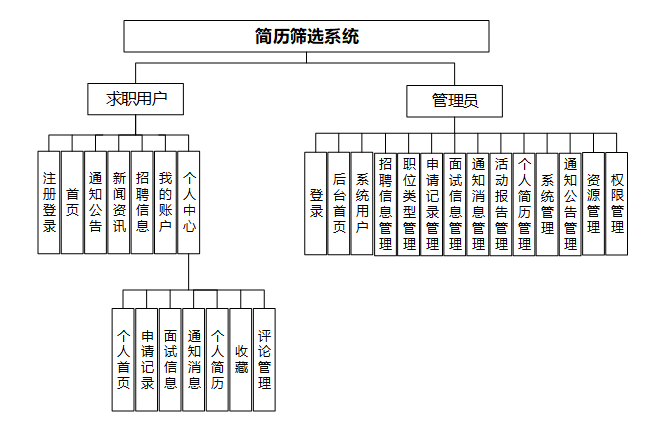
在上一章节中主要对系统的功能性需求和非功能性需求进行分析,并且根据需求分析了本简历筛选系统中的用例。那么接下来就要开始对本简历筛选系统的架构、主要功能和数据库开始进行设计。简历筛选系统根据前面章节的需求分析得出,简历筛选系统的功能模块图如下图所示。
-
-
-
-
- 简历筛选系统功能模块图
-
-
- 数据库设计
-
数据库设计一般包括需求分析、概念模型设计、数据库表建立三大过程,其中需求分析前面章节已经阐述,概念模型设计有概念模型和逻辑结构设计两部分。
-
-
- 数据库概念结构设计
-
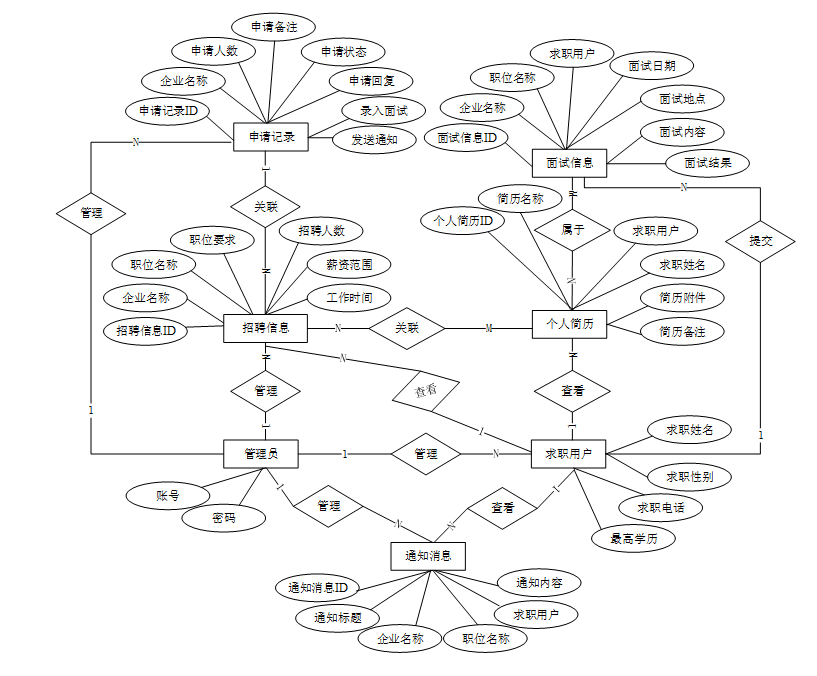
下面是整个简历筛选系统中主要的数据库表总E-R实体关系图。
-
-
-
-
- 简历筛选系统总E-R关系图
-
- 数据库逻辑结构设计
-
-
通过上一小节中简历筛选系统中总E-R关系图上得出一共需要创建多个数据表。在此主要罗列几个主要的数据库表结构设计。
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | token_id | int | 是 | 是 | 临时访问牌ID | |
| 2 | token | varchar | 64 | 否 | 否 | 临时访问牌 |
| 3 | info | text | 65535 | 否 | 否 | 信息 |
| 4 | maxage | int | 是 | 否 | 最大寿命:默认2小时 | |
| 5 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 6 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 7 | user_id | int | 是 | 否 | 用户编号 |
表 4-2-activity_report(活动报告)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | activity_report_id | int | 是 | 是 | 活动报告ID | |
| 2 | activity_name | varchar | 64 | 否 | 否 | 活动名称 |
| 3 | analysis_date | date | 否 | 否 | 分析日期 | |
| 4 | number_of_participants | double | 否 | 否 | 参与人数 | |
| 5 | analysis_content | text | 65535 | 否 | 否 | 分析内容 |
| 6 | analysis_remarks | text | 65535 | 否 | 否 | 分析备注 |
| 7 | create_time | datetime | 是 | 否 | 创建时间 | |
| 8 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-3-application_record(申请记录)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | application_record_id | int | 是 | 是 | 申请记录ID | |
| 2 | name_of_enterprise | varchar | 64 | 否 | 否 | 企业名称 |
| 3 | job_title | varchar | 64 | 否 | 否 | 职位名称 |
| 4 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 5 | job_users | int | 否 | 否 | 求职用户 | |
| 6 | job_name | varchar | 64 | 否 | 否 | 求职姓名 |
| 7 | job_search_gender | varchar | 64 | 否 | 否 | 求职性别 |
| 8 | job_search_phone | varchar | 64 | 否 | 否 | 求职电话 |
| 9 | highest_degree | varchar | 64 | 否 | 否 | 最高学历 |
| 10 | resume_attachments | varchar | 255 | 否 | 否 | 简历附件 |
| 11 | number_of_applicants | varchar | 64 | 否 | 否 | 申请人数 |
| 12 | application_remarks | text | 65535 | 否 | 否 | 申请备注 |
| 13 | application_status | varchar | 64 | 否 | 否 | 申请状态 |
| 14 | application_reply | text | 65535 | 否 | 否 | 申请回复 |
| 15 | interview_information_limit_times | int | 是 | 否 | 录入面试限制次数 | |
| 16 | notification_message_limit_times | int | 是 | 否 | 发送通知限制次数 | |
| 17 | create_time | datetime | 是 | 否 | 创建时间 | |
| 18 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 19 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 20 | source_id | int | 否 | 否 | 来源ID | |
| 21 | source_user_id | int | 否 | 否 | 来源用户 |
表 4-4-article(文章)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | article_id | mediumint | 是 | 是 | 文章id | |
| 2 | title | varchar | 125 | 是 | 是 | 标题 |
| 3 | type | varchar | 64 | 是 | 否 | 文章分类 |
| 4 | hits | int | 是 | 否 | 点击数 | |
| 5 | praise_len | int | 是 | 否 | 点赞数 | |
| 6 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 7 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 8 | source | varchar | 255 | 否 | 否 | 来源 |
| 9 | url | varchar | 255 | 否 | 否 | 来源地址 |
| 10 | tag | varchar | 255 | 否 | 否 | 标签 |
| 11 | content | longtext | 4294967295 | 否 | 否 | 正文 |
| 12 | img | varchar | 255 | 否 | 否 | 封面图 |
| 13 | description | text | 65535 | 否 | 否 | 文章描述 |
表 4-5-article_type(文章分类)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | type_id | smallint | 是 | 是 | 分类ID | |
| 2 | display | smallint | 是 | 否 | 显示顺序 | |
| 3 | name | varchar | 16 | 是 | 否 | 分类名称 |
| 4 | father_id | smallint | 是 | 否 | 上级分类ID | |
| 5 | description | varchar | 255 | 否 | 否 | 描述 |
| 6 | icon | text | 65535 | 否 | 否 | 分类图标 |
| 7 | url | varchar | 255 | 否 | 否 | 外链地址 |
| 8 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 9 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-6-auth(用户权限管理)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | auth_id | int | 是 | 是 | 授权ID | |
| 2 | user_group | varchar | 64 | 否 | 否 | 用户组 |
| 3 | mod_name | varchar | 64 | 否 | 否 | 模块名 |
| 4 | table_name | varchar | 64 | 否 | 否 | 表名 |
| 5 | page_title | varchar | 255 | 否 | 否 | 页面标题 |
| 6 | path | varchar | 255 | 否 | 否 | 路由路径 |
| 7 | parent | varchar | 64 | 否 | 否 | 父级菜单 |
| 8 | parent_sort | int | 是 | 否 | 父级菜单排序 | |
| 9 | position | varchar | 32 | 否 | 否 | 位置 |
| 10 | mode | varchar | 32 | 是 | 否 | 跳转方式 |
| 11 | add | tinyint | 是 | 否 | 是否可增加 | |
| 12 | del | tinyint | 是 | 否 | 是否可删除 | |
| 13 | set | tinyint | 是 | 否 | 是否可修改 | |
| 14 | get | tinyint | 是 | 否 | 是否可查看 | |
| 15 | field_add | text | 65535 | 否 | 否 | 添加字段 |
| 16 | field_set | text | 65535 | 否 | 否 | 修改字段 |
| 17 | field_get | text | 65535 | 否 | 否 | 查询字段 |
| 18 | table_nav_name | varchar | 500 | 否 | 否 | 跨表导航名称 |
| 19 | table_nav | varchar | 500 | 否 | 否 | 跨表导航 |
| 20 | option | text | 65535 | 否 | 否 | 配置 |
| 21 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 22 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-7-code_token(验证码)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | code_token_id | int | 是 | 是 | 验证码ID | |
| 2 | token | varchar | 255 | 否 | 否 | 令牌 |
| 3 | code | varchar | 255 | 否 | 否 | 验证码 |
| 4 | expire_time | timestamp | 是 | 否 | 失效时间 | |
| 5 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 6 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-8-collect(收藏)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | collect_id | int | 是 | 是 | 收藏ID | |
| 2 | user_id | int | 是 | 是 | 收藏人ID | |
| 3 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 4 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 5 | source_id | int | 是 | 否 | 来源ID | |
| 6 | title | varchar | 255 | 否 | 否 | 标题 |
| 7 | img | varchar | 255 | 否 | 否 | 封面 |
| 8 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 9 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-9-comment(评论)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | comment_id | int | 是 | 是 | 评论ID | |
| 2 | user_id | int | 是 | 是 | 评论人ID | |
| 3 | reply_to_id | int | 是 | 否 | 回复评论ID | |
| 4 | content | longtext | 4294967295 | 否 | 否 | 内容 |
| 5 | nickname | varchar | 255 | 否 | 否 | 昵称 |
| 6 | avatar | varchar | 255 | 否 | 否 | 头像地址 |
| 7 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 8 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 9 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 10 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 11 | source_id | int | 是 | 否 | 来源ID |
表 4-10-hits(用户点击)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | hits_id | int | 是 | 是 | 点赞ID | |
| 2 | user_id | int | 是 | 否 | 点赞人 | |
| 3 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 5 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 6 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 7 | source_id | int | 是 | 否 | 来源ID |
表 4-11-interview_information(面试信息)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | interview_information_id | int | 是 | 是 | 面试信息ID | |
| 2 | name_of_enterprise | varchar | 64 | 否 | 否 | 企业名称 |
| 3 | job_title | varchar | 64 | 否 | 否 | 职位名称 |
| 4 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 5 | job_users | int | 否 | 否 | 求职用户 | |
| 6 | job_name | varchar | 64 | 否 | 否 | 求职姓名 |
| 7 | job_search_phone | varchar | 64 | 否 | 否 | 求职电话 |
| 8 | interview_date | date | 否 | 否 | 面试日期 | |
| 9 | interview_location | varchar | 64 | 否 | 否 | 面试地点 |
| 10 | interview_content | text | 65535 | 否 | 否 | 面试内容 |
| 11 | interview_results | varchar | 64 | 否 | 否 | 面试结果 |
| 12 | create_time | datetime | 是 | 否 | 创建时间 | |
| 13 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 14 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 15 | source_id | int | 否 | 否 | 来源ID | |
| 16 | source_user_id | int | 否 | 否 | 来源用户 |
表 4-12-job_users(求职用户)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | job_users_id | int | 是 | 是 | 求职用户ID | |
| 2 | job_name | varchar | 64 | 否 | 否 | 求职姓名 |
| 3 | job_search_gender | varchar | 64 | 否 | 否 | 求职性别 |
| 4 | job_search_phone | varchar | 16 | 否 | 否 | 求职电话 |
| 5 | highest_degree | varchar | 64 | 否 | 否 | 最高学历 |
| 6 | job_hunting_intention | varchar | 64 | 否 | 否 | 求职意向 |
| 7 | examine_state | varchar | 16 | 是 | 否 | 审核状态 |
| 8 | user_id | int | 是 | 否 | 用户ID | |
| 9 | create_time | datetime | 是 | 否 | 创建时间 | |
| 10 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-13-notice(公告)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | notice_id | mediumint | 是 | 是 | 公告ID | |
| 2 | title | varchar | 125 | 是 | 否 | 标题 |
| 3 | content | longtext | 4294967295 | 否 | 否 | 正文 |
| 4 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 5 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-14-notification_message(通知消息)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | notification_message_id | int | 是 | 是 | 通知消息ID | |
| 2 | notification_title | varchar | 64 | 否 | 否 | 通知标题 |
| 3 | name_of_enterprise | varchar | 64 | 否 | 否 | 企业名称 |
| 4 | job_title | varchar | 64 | 否 | 否 | 职位名称 |
| 5 | job_users | int | 否 | 否 | 求职用户 | |
| 6 | notification_content | text | 65535 | 否 | 否 | 通知内容 |
| 7 | create_time | datetime | 是 | 否 | 创建时间 | |
| 8 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 9 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 10 | source_id | int | 否 | 否 | 来源ID | |
| 11 | source_user_id | int | 否 | 否 | 来源用户 |
表 4-15-personal_resume(个人简历)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | personal_resume_id | int | 是 | 是 | 个人简历ID | |
| 2 | resume_name | varchar | 64 | 否 | 否 | 简历名称 |
| 3 | job_users | int | 否 | 否 | 求职用户 | |
| 4 | job_name | varchar | 64 | 否 | 否 | 求职姓名 |
| 5 | job_search_phone | varchar | 64 | 否 | 否 | 求职电话 |
| 6 | resume_attachments | varchar | 255 | 否 | 否 | 简历附件 |
| 7 | resume_remarks | text | 65535 | 否 | 否 | 简历备注 |
| 8 | create_time | datetime | 是 | 否 | 创建时间 | |
| 9 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-16-position_type(职位类型)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | position_type_id | int | 是 | 是 | 职位类型ID | |
| 2 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 3 | create_time | datetime | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-17-praise(点赞)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | praise_id | int | 是 | 是 | 点赞ID | |
| 2 | user_id | int | 是 | 是 | 点赞人 | |
| 3 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 4 | update_time | timestamp | 是 | 否 | 更新时间 | |
| 5 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 6 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 7 | source_id | int | 是 | 否 | 来源ID | |
| 8 | status | tinyint | 是 | 否 | 点赞状态:1为点赞,0已取消 |
表 4-18-recruitment_information(招聘信息)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | recruitment_information_id | int | 是 | 是 | 招聘信息ID | |
| 2 | name_of_enterprise | varchar | 64 | 否 | 否 | 企业名称 |
| 3 | job_title | varchar | 64 | 否 | 否 | 职位名称 |
| 4 | position_type | varchar | 64 | 否 | 否 | 职位类型 |
| 5 | job_requirements | varchar | 64 | 否 | 否 | 职位要求 |
| 6 | number_of_recruits | varchar | 64 | 否 | 否 | 招聘人数 |
| 7 | recruitment_status | varchar | 64 | 否 | 否 | 招聘状态 |
| 8 | salary_range | varchar | 64 | 否 | 否 | 薪资范围 |
| 9 | working_time | varchar | 64 | 否 | 否 | 工作时间 |
| 10 | place_of_work | varchar | 64 | 否 | 否 | 工作地点 |
| 11 | cover_image | varchar | 255 | 否 | 否 | 封面图片 |
| 12 | content_details | longtext | 4294967295 | 否 | 否 | 内容详情 |
| 13 | hits | int | 是 | 否 | 点击数 | |
| 14 | praise_len | int | 是 | 否 | 点赞数 | |
| 15 | collect_len | int | 是 | 否 | 收藏数 | |
| 16 | comment_len | int | 是 | 否 | 评论数 | |
| 17 | recommend | int | 是 | 否 | 智能推荐 | |
| 18 | application_record_limit_times | int | 是 | 否 | 申请限制次数 | |
| 19 | create_time | datetime | 是 | 否 | 创建时间 | |
| 20 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-19-slides(轮播图)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | slides_id | int | 是 | 是 | 轮播图ID | |
| 2 | title | varchar | 64 | 否 | 否 | 标题 |
| 3 | content | varchar | 255 | 否 | 否 | 内容 |
| 4 | url | varchar | 255 | 否 | 否 | 链接 |
| 5 | img | varchar | 255 | 否 | 否 | 轮播图 |
| 6 | hits | int | 是 | 否 | 点击量 | |
| 7 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 8 | update_time | timestamp | 是 | 否 | 更新时间 |
表 4-20-upload(文件上传)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | upload_id | int | 是 | 是 | 上传ID | |
| 2 | name | varchar | 64 | 否 | 否 | 文件名 |
| 3 | path | varchar | 255 | 否 | 否 | 访问路径 |
| 4 | file | varchar | 255 | 否 | 否 | 文件路径 |
| 5 | display | varchar | 255 | 否 | 否 | 显示顺序 |
| 6 | father_id | int | 否 | 否 | 父级ID | |
| 7 | dir | varchar | 255 | 否 | 否 | 文件夹 |
| 8 | type | varchar | 32 | 否 | 否 | 文件类型 |
表 4-21-user(用户账户)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | user_id | int | 是 | 是 | 用户ID | |
| 2 | state | smallint | 是 | 否 | 账户状态:(1可用|2异常|3已冻结|4已注销) | |
| 3 | user_group | varchar | 32 | 否 | 否 | 所在用户组 |
| 4 | login_time | timestamp | 是 | 否 | 上次登录时间 | |
| 5 | phone | varchar | 11 | 否 | 否 | 手机号码 |
| 6 | phone_state | smallint | 是 | 否 | 手机认证:(0未认证|1审核中|2已认证) | |
| 7 | username | varchar | 16 | 是 | 否 | 用户名 |
| 8 | nickname | varchar | 16 | 否 | 否 | 昵称 |
| 9 | password | varchar | 64 | 是 | 否 | 密码 |
| 10 | | varchar | 64 | 否 | 否 | 邮箱 |
| 11 | email_state | smallint | 是 | 否 | 邮箱认证:(0未认证|1审核中|2已认证) | |
| 12 | avatar | varchar | 255 | 否 | 否 | 头像地址 |
| 13 | open_id | varchar | 255 | 否 | 否 | 针对获取用户信息字段 |
| 14 | create_time | timestamp | 是 | 否 | 创建时间 |
表 4-22-user_group(用户组)
| 编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
| 1 | group_id | mediumint | 是 | 是 | 用户组ID | |
| 2 | display | smallint | 是 | 否 | 显示顺序 | |
| 3 | name | varchar | 16 | 是 | 否 | 名称 |
| 4 | description | varchar | 255 | 否 | 否 | 描述 |
| 5 | source_table | varchar | 255 | 否 | 否 | 来源表 |
| 6 | source_field | varchar | 255 | 否 | 否 | 来源字段 |
| 7 | source_id | int | 是 | 否 | 来源ID | |
| 8 | register | smallint | 否 | 否 | 注册位置 | |
| 9 | create_time | timestamp | 是 | 否 | 创建时间 | |
| 10 | update_time | timestamp | 是 | 否 | 更新时间 |
简历筛选系统的详细设计与实现主要是根据前面的简历筛选系统的需求分析和简历筛选系统的总体设计来设计页面并实现业务逻辑。主要从简历筛选系统界面实现、业务逻辑实现这两部分进行介绍。
-
- 前端首页模块
首页展示展示平台核心信息,如热门岗位、推荐职位、快速入口等功能模块,提升用户使用便捷度。前台首页模块展示如下图所示。
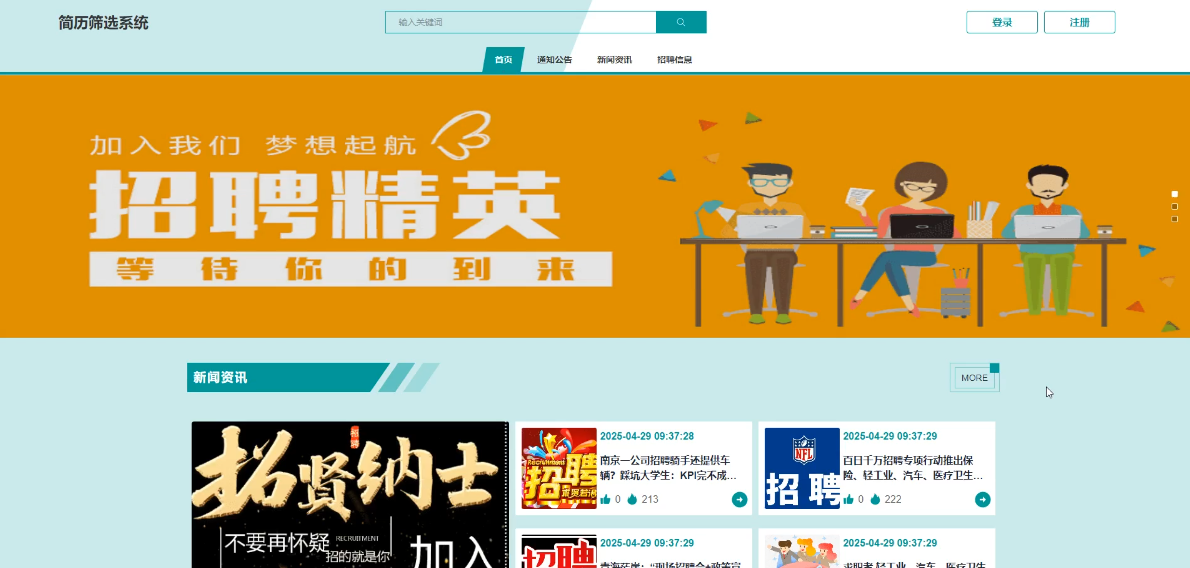
-
-
-
-
- 前台首页模块图
-
-
- 用户注册模块
-
简历筛选系统中正式用户的是可以在线进行注册的,当填写上自己的账号+设置密码+确认密码+用户姓名+性别+年龄+邮箱+手机号+头像等信息后再点击“注册”按钮后将会先验证输入的有没有空数据,再次验证密码和确认密码是否是一样的,最后验证输入的账户名和数据库表中已经注册的账户名是否重复,只有都验证没问题后即可用户注册成功。其用户注册模块展示如下图所示。
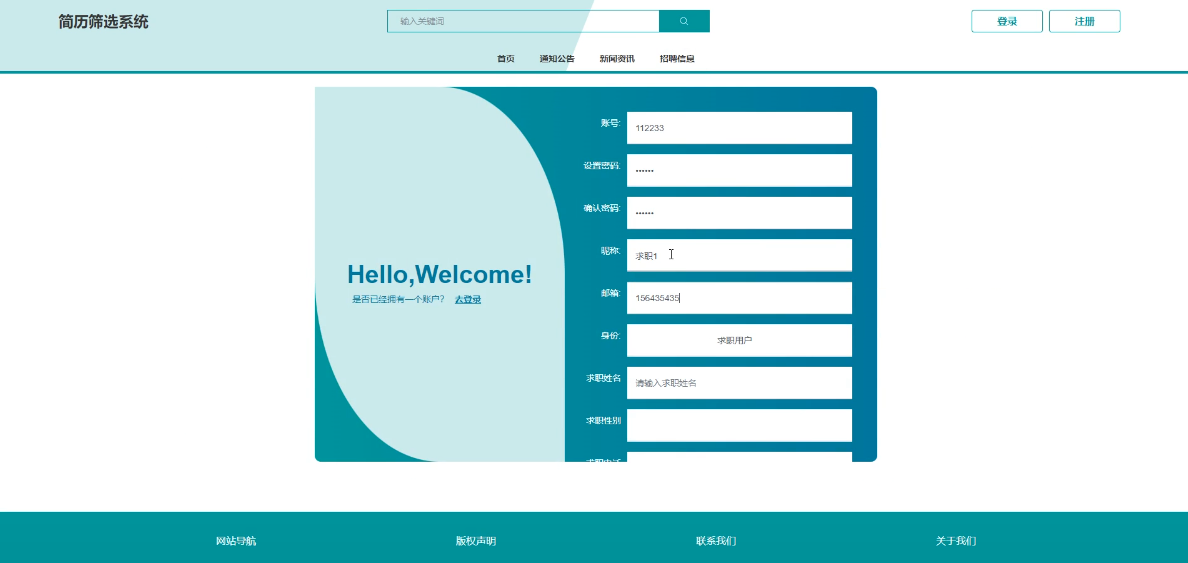
-
-
-
-
- 注册模块图
-
-
- 登录模块
-
简历筛选系统中的前台上注册后的用户是可以通过自己的用户名+密码进行登录的,当用户输入完整的自己的用户名+密码信息并点击“登录”按钮后,将会首先验证输入的有没有空数据,再次验证输入的用户名+密码和数据库中当前保存的用户信息是否一致,只有在一致后将会登录成功并自动跳转到简历筛选系统的首页中,否则将会提示相应错误信息,登录模块如下图所示。
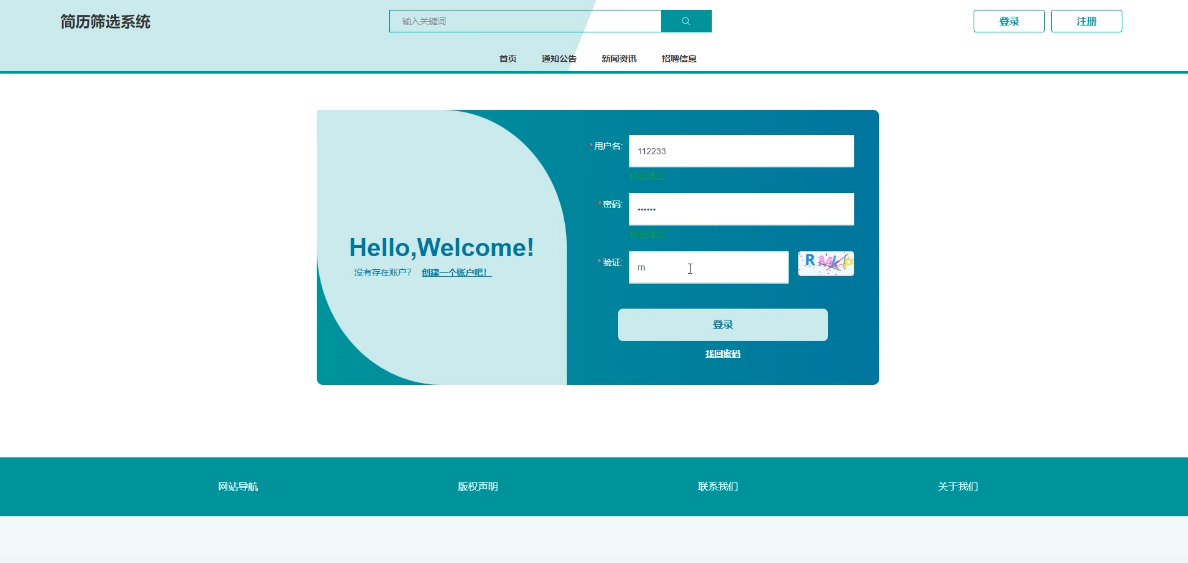
-
-
-
-
- 登录模块图
-
-
- 前端求职用户功能模块
-
用户可以浏览平台发布的最新动态、政策信息及重要通知,增强用户对平台活动的了解。模块如下图所示:
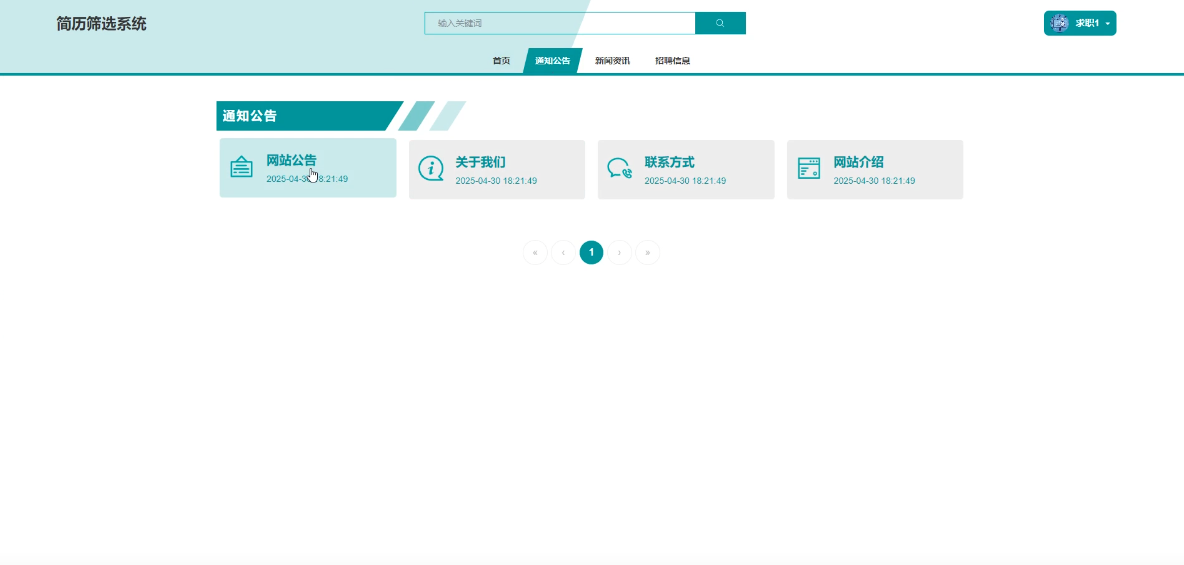
提供与就业市场、行业发展相关的资讯内容,帮助用户了解行业趋势,辅助职业规划。模块如下图所示。
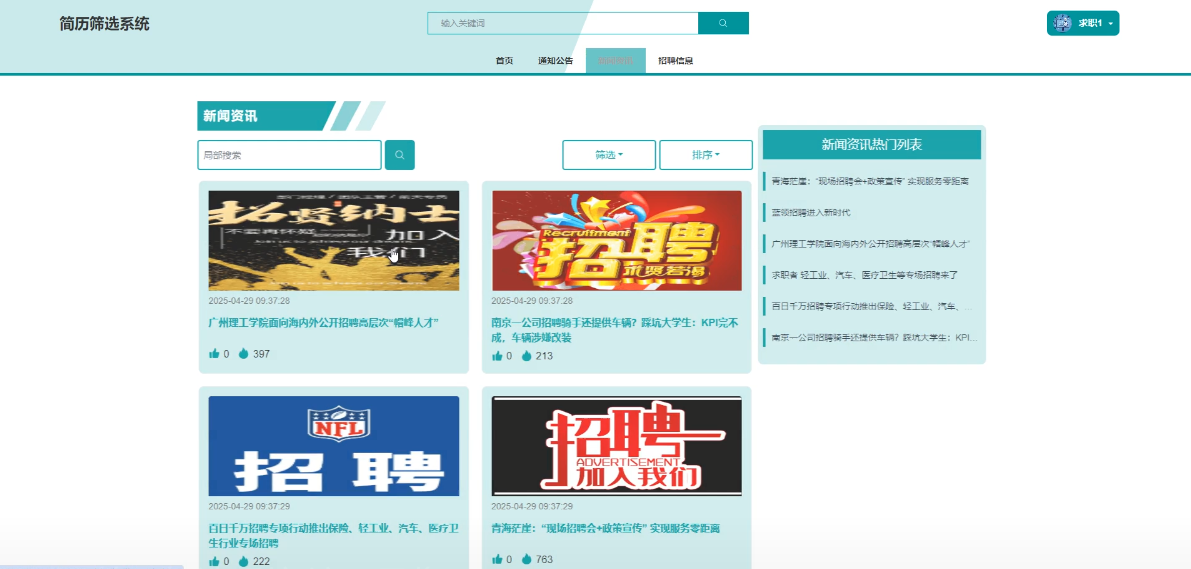
系统采用聚类矩阵算法,根据用户的点击、点赞、收藏等行为数据,智能推荐与其兴趣和能力匹配的岗位信息,实现个性化推荐服务。模块如下图所示。
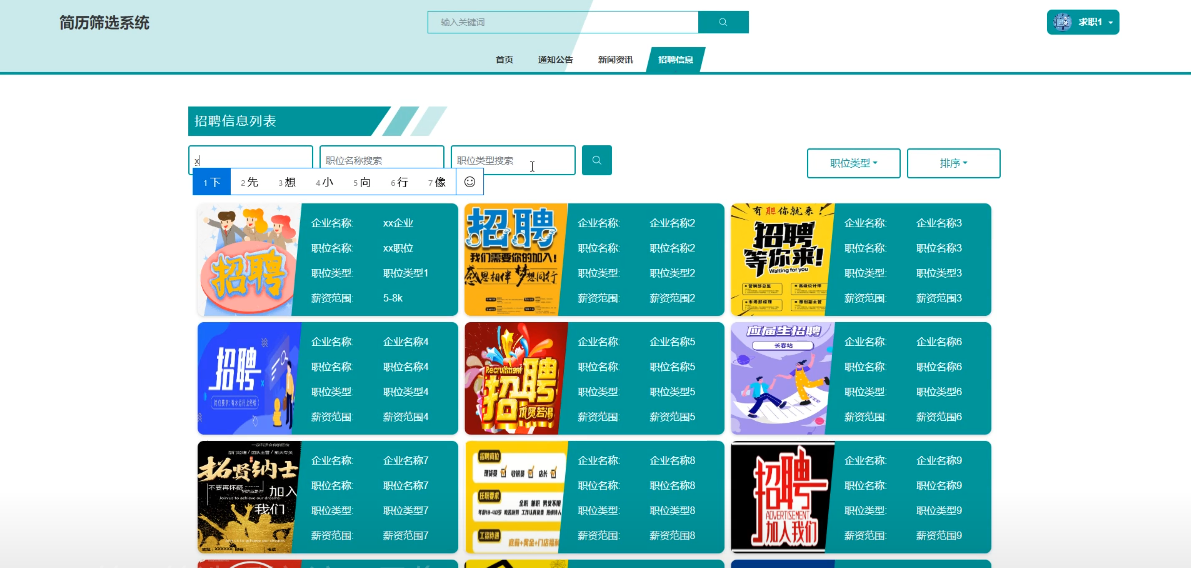
-
-
-
-
- 招聘信息列表模块图
-
-
-
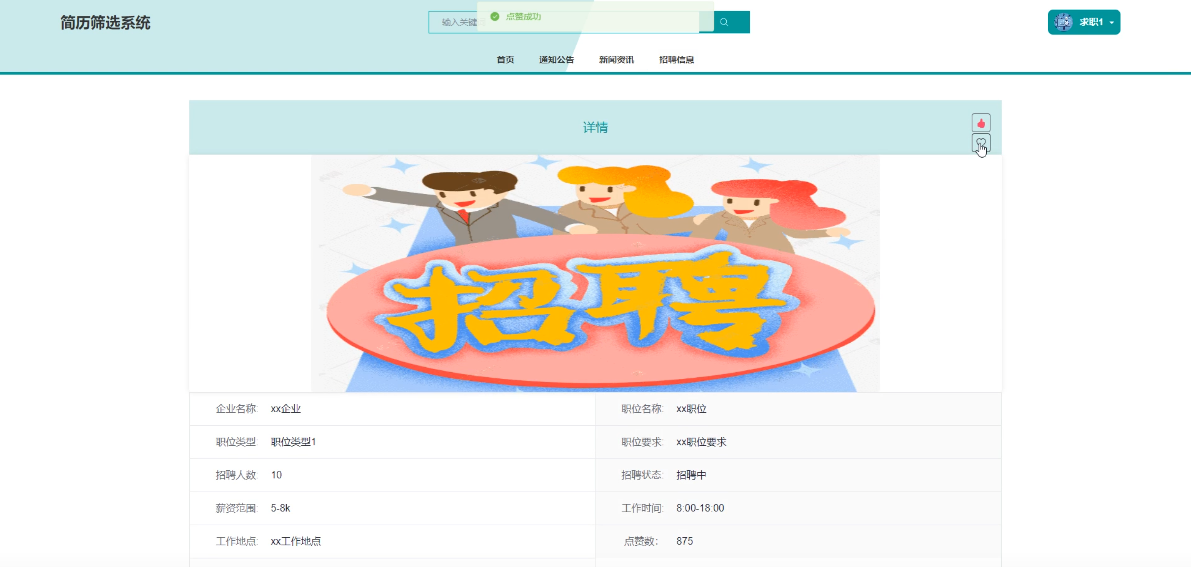
-
-
-
-
- 招聘信息详情模块图
-
-
-
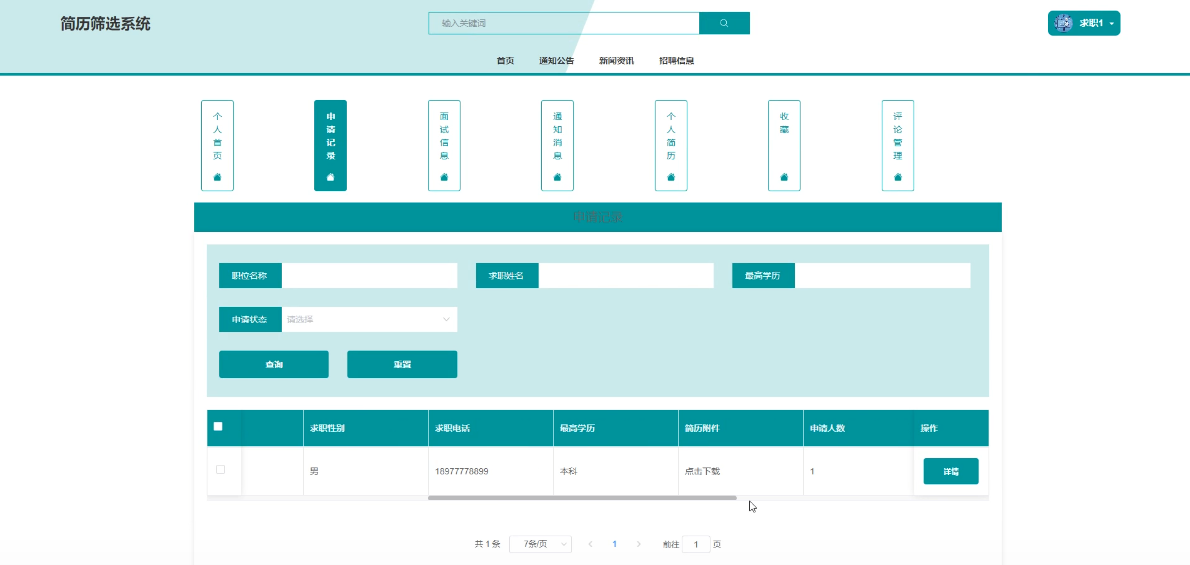
整合用户核心操作功能,包括个人首页展示、职位申请记录查询、面试安排通知、系统消息提醒、简历管理、收藏岗位以及评论内容管理等,方便用户一站式管理求职相关事务。模块如下图所示。
-
-
-
-
- 个人中心:申请记录模块图
-
-
-
-
- 后端管理员功能模块
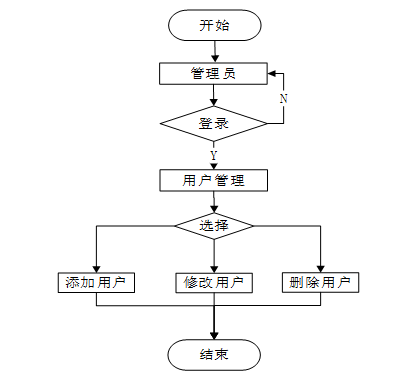
管理员可以查看所有用户的详细信息,进行修改、删除、添加新用户以及批量删除用户,并支持查询功能。这些操作有助于保持用户数据的准确性和完整性,同时也能及时处理违规或不活跃账户,确保平台的安全和清洁。流程图如下所示。
-
-
-
-
- 用户管理流程图
-
-
-
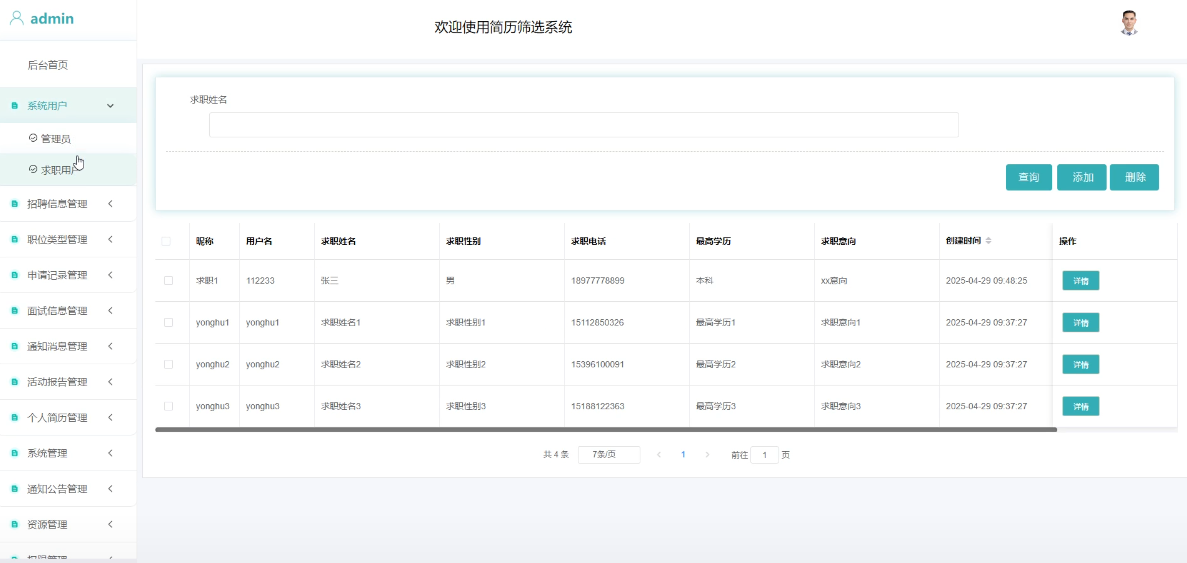
用户管理模块如下图所示。
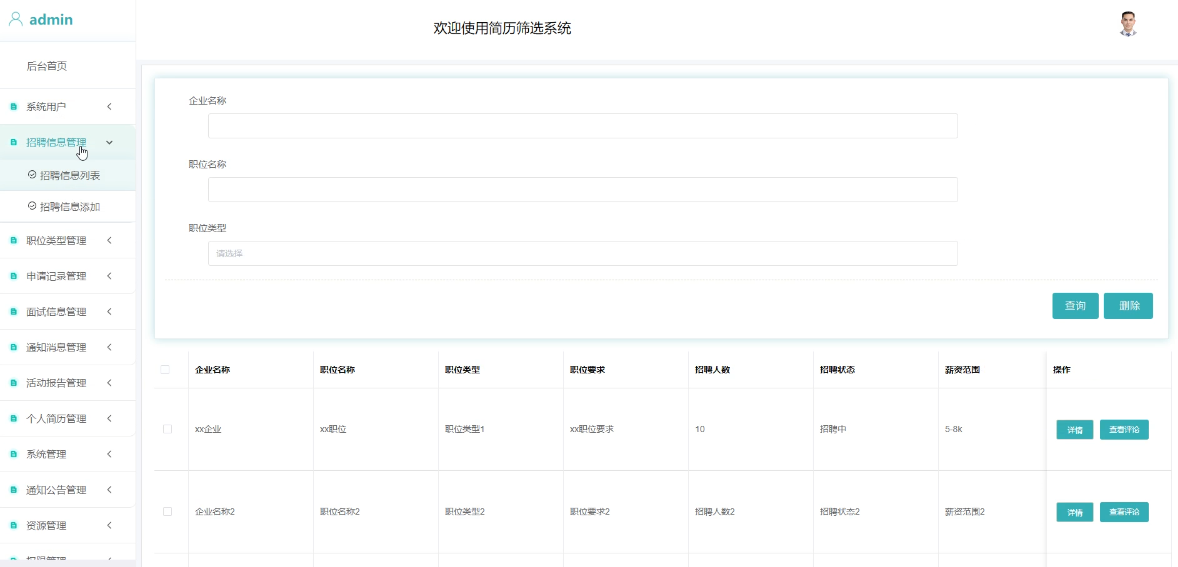
管理员负责包括发布新职位、编辑现有职位信息、删除过期或不合适的信息,确保招聘信息的准确性和时效性。模块如下图所示。
-
-
-
-
- 招聘信息列表管理模块图
-
-
-
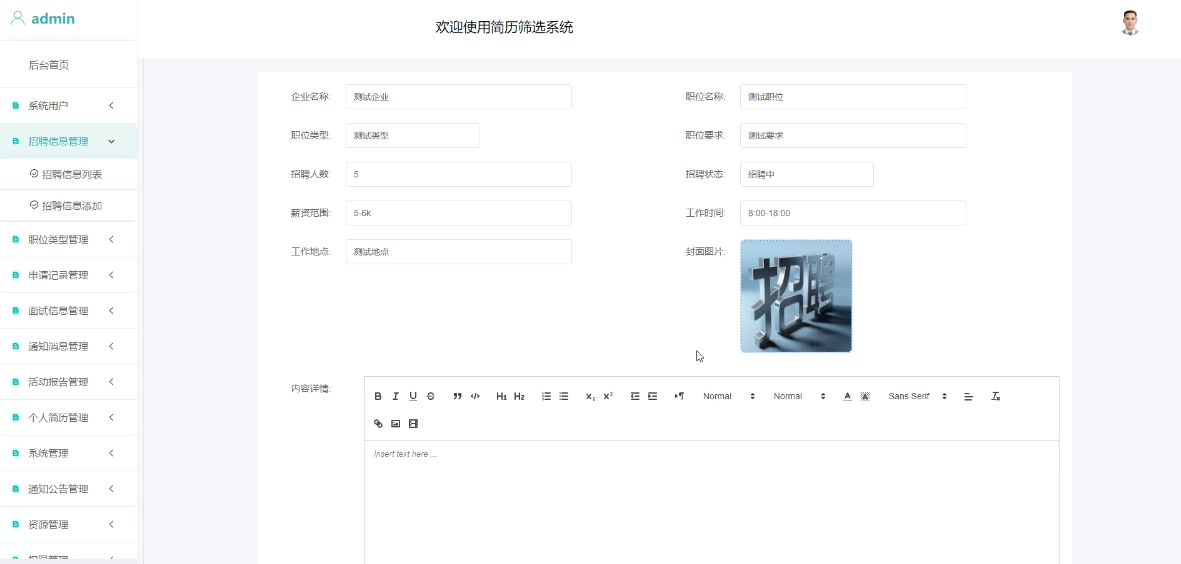
-
-
-
-
- 招聘信息添加管理模块图
-
-
-
管理员可以对求职者的职位申请记录进行管理和查询,提供数据分析支持,帮助了解招聘效果。模块如下图所示。
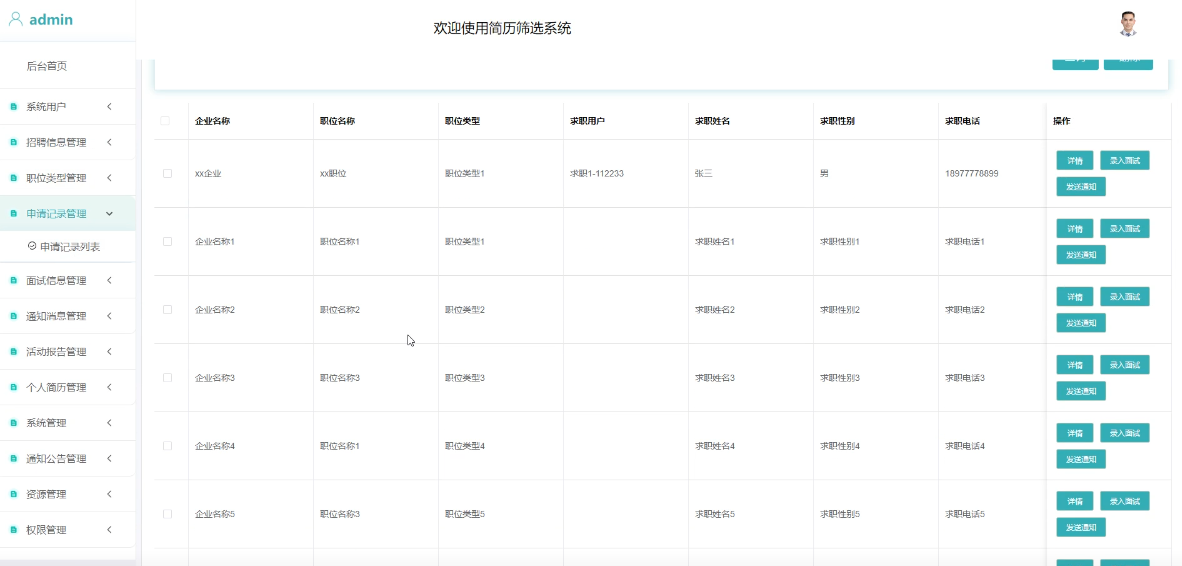
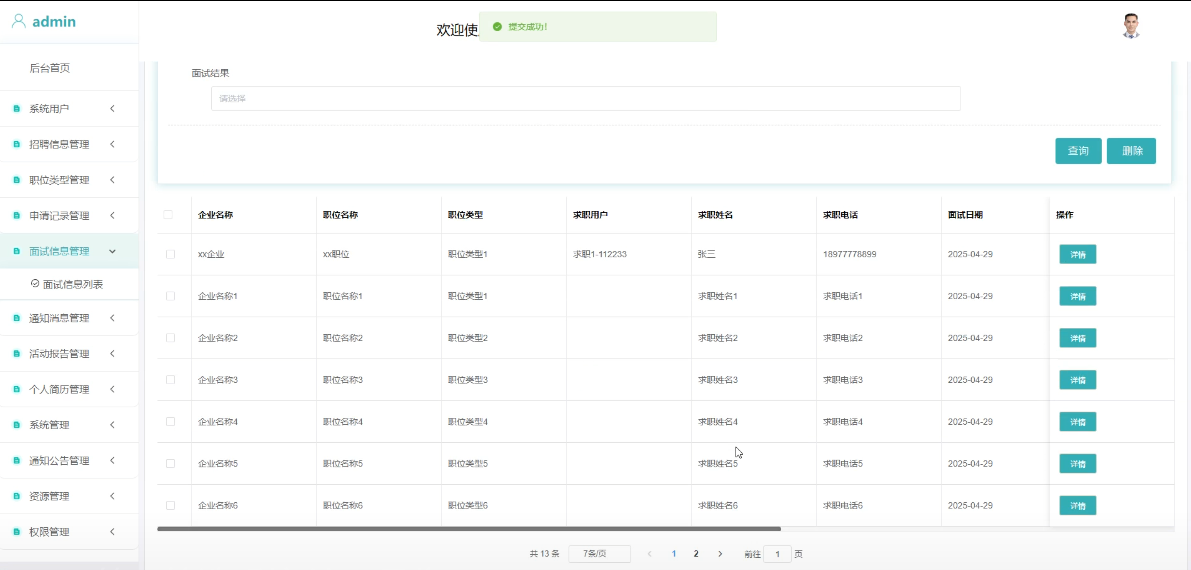
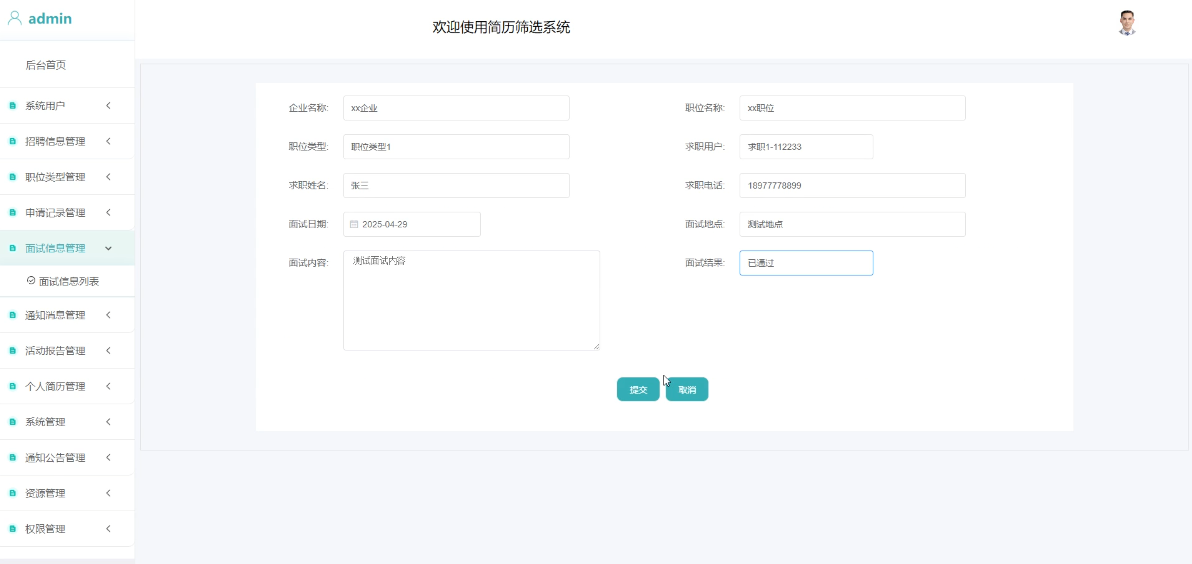
管理员可以录入、更新和管理面试安排及相关信息,确保面试流程的顺利进行。模块如下图所示。
-
-
-
-
- 面试信息列表管理模块图
-
-
-
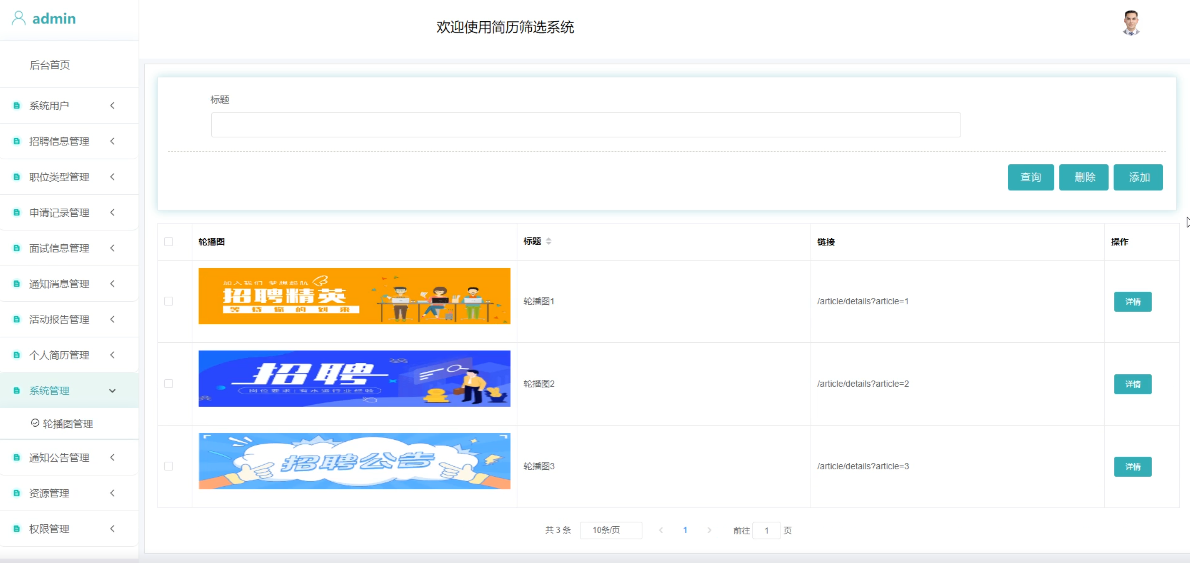
管理员可以上传、编辑或删除首页轮播图内容,增强网站视觉吸引力和信息传达效果。模块如下图所示。
-
-
-
-
- 轮播图管理模块图
-
-
-
测试的主要目的是确保系统的功能和性能满足预期的需求,同时识别和修复潜在的缺陷。通过系统测试,可以验证各个功能模块的正确性和稳定性,确保系统在不同使用场景下的表现符合设计要求。测试目的包括确认系统功能的完整性、验证数据处理的准确性、评估系统的性能和安全性。测试还可以提高用户满意度,保证用户在使用系统时获得流畅和可靠的体验。通过全面的测试,可以降低后期维护成本,减少系统上线后出现故障的风险,从而保障系统的长期稳定运行。
在本系统中,测试方法主要依赖于测试用例的设计与执行。测试用例是根据系统需求文档编写的,覆盖所有功能模块及其边界情况。每个测试用例包含输入数据、预期结果和实际结果的对比,以验证系统的功能是否按预期工作。
常见的测试用例包括功能测试用例、边界测试用例和异常测试用例。功能测试用例针对系统的各项功能进行验证;边界测试用例则侧重于输入数据的边界条件,验证系统在极端情况下是否能够稳定运行;异常测试用例则用于验证系统在处理错误输入或异常情况时的反应。本文选择功能测试用例进行系统测试。
在测试执行过程中,记录每个用例的执行结果,并根据实际结果与预期结果的对比,判断系统是否存在缺陷。通过系统化的测试用例执行,可以有效提高测试的覆盖率和效率,为系统的最终上线提供保障。
表6-1 用户登录功能测试表
| 用例名称 | 用户登录系统 |
| 目的 | 测试用户通过正确的用户名和密码可否登录功能 |
| 前提 | 未登录的情况下 |
| 测试流程 | 1) 进入登录页面 2) 输入正确的用户名和密码 |
| 预期结果 | 用户名和密码正确的时候,跳转到登录成功界面,反之则显示错误信息,提示重新输入 |
| 实际结果 | 实际结果与预期结果一致 |
在系统中,创建功能也是基础功能之一,因此创建功能的测试很有代表性。在此章节主要列举在创建时各种情况下系统结果的测试。由于系统涉及创建功能操作过多,因此将多处统称创建功能。
创建数据用例如表6-2 所示。
表6-2 创建数据测试用例
| 测试用例编号 | YL_05 | |
| 测试用例名称 | 系统使用者进行创建数据 | |
| 测试用例描述 | 使用者输入要创建的数据 | |
| 系统入口 | 浏览器 | |
| 步骤 | 预期结果 | 实际结果 |
| 输入完整并且格式正确的数据 | 提示“创建成功”,并显示所有数据 | 预期结果 |
| 核心位置数据但非必要位置不输入数据 | 提示“创建成功”,并显示所有数据 | 预期结果 |
| 核心数据位置不输入数据 | 提示“创建失败” | 预期结果 |
-
-
- 修改数据测试
-
在系统中,修改功能是系统主要实现功能,因此修改功能的测试很有代表性。在此章节主要列举在修改时各种情况下系统结果的测试。由于系统涉及修改功能操作过多,因此将多处数据表记录修改和状态修改统称修改功能。
修改数据用例如表6-3所示。
表6-3 修改数据测试用例
| 测试用例编号 | YL_06 | |
| 测试用例名称 | 系统使用者进行修改数据 | |
| 测试用例描述 | 使用者对可修改的数据项进行修改 | |
| 系统入口 | 浏览器 | |
| 步骤 | 预期结果 | 实际结果 |
| 将现有数据修改成正确的数据 | 提示“修改成功”,并显示所有数据 | 预期结果 |
| 将现有数据修改成错误的数据 | 提示“修改失败” | 预期结果 |
-
-
- 查询数据测试
-
在系统中,查询功能是使用系统使用最多也是最基础的功能,因此查询功能的测试很有代表性。在此章节主要列举在查询时各种情况下系统结果的测试。
查询数据用例如表6-4所示。
表6-4 查询数据测试用例
| 测试用例编号 | YL_05 | |
| 测试用例名称 | 系统使用者进行查询数据 | |
| 测试用例描述 | 全部查询以及输入关键词查询 | |
| 系统入口 | 浏览器 | |
| 步骤 | 预期结果 | 实际结果 |
| 界面自动查询全部 | 显示对应所有记录 | 预期结果 |
| 输入已存在且能匹配成功的关键字 | 显示所查询到的数据 | 预期结果 |
| 输入不存在的关键字 | 显示数据界面为空 | 预期结果 |
在本次测试的过程主要针对所有功能下的添加操作,修改操作和删除操作,并以真实数据一一进行相关功能项目的输入,最终能够保证每个项目涉及的功能都能够正常运行,因此能够保证本次设计的,已实现的功能能够正常运行并且相关数据库的信息也同样保证正确。
本文围绕基于聚类算法的简历筛选系统展开研究与设计,结合Flask框架与聚类矩阵算法,构建了一个功能完善、操作便捷、智能高效的在线招聘平台。系统从实际应用出发,面向求职用户和管理员两大角色,涵盖注册登录、岗位推荐、信息管理、后台维护等多项功能,实现了从简历投递到岗位匹配的全流程服务。
在技术实现上,系统采用Flask框架作为开发基础,具有良好的稳定性与扩展性,适合未来进一步的功能拓展;同时引入聚类矩阵算法,通过分析用户的点击、点赞、收藏等行为数据,实现个性化的职位推荐机制,显著提升了人岗匹配的精准度和用户体验。对于管理员而言,完善的后台管理系统支持对用户、职位、简历、通知、权限等多个模块的统一管理,提高了平台的可维护性和运营效率。
本系统不仅有助于企业提高招聘效率、降低人工筛选成本,也为求职者提供了更加智能化、精准化的求职服务,推动了人力资源配置的优化升级。尽管目前系统在算法优化、实时响应等方面仍有提升空间,但其整体架构和技术路线已展现出良好的实用价值和发展潜力。未来可在推荐算法优化、多维度数据融合以及智能交互体验等方面进行深入拓展,为构建更加智能化、专业化的招聘平台提供有力支撑。
- 黄维.基于B/S模式的虚拟网络实验室安全管理体系分析[J].信息系统工程,2024,(05):4-7.
- 张宇薇.HTML5在Web前端开发中的应用[J].集成电路应用,2024,41(04):274-276.
- 王朝辉. 基于Flask框架的测试集成系统设计与实现 [J]. 科技创新与应用, 2024, 14 (33): 115-118.
- 陈嘉发,黄宇靖. Flask框架在数据可视化的应用 [J]. 福建电脑, 2022, 38 (12): 44-48.
- 李艳杰.MySQL数据库下存储过程的综合运用研究[J].现代信息科技,2023,7(11):80-82+88.
- 肖睿,李鲲程,范效亮,等.MySQL数据库应用技术及实践[M].人民邮电出版社:202206.228.
- 明日科技.快速上手Python[M].化学工业出版社:202211.337.
- 明日科技.Python Web开发手册[M].化学工业出版社:202201.411.
- 张锦贤,吴晓玲. 基于flask框架技术的网站设计 [J]. 电脑知识与技术, 2024, 20 (10): 71-73.
- 庞敏. MySQL数据库的数据安全应用设计技术研究 [J]. 数字通信世界, 2024, (09): 25-27.
- 高亚文,鹿婷.基于学生信息模型及聚类算法的精准思政教育研究[J].西部学刊,2025,(08):95-99.DOI:10.16721/j.cnki.cn61-1487/c.2025.08.032.
- Sareddy R M ,Farhan M .Automatic Resume Screening Approach Based on AI and Ethereum Blockchain for Human Resource Management Using Gaaru[J].SN Computer Science,2025,6(4):336-336.
- 程镇,陈俊杰,胡璐,等.结合注意力机制的用户特征聚类推荐算法研究[J].信息与电脑,2025,37(05):35-37.
- Bevara K V R ,Mannuru R N ,Karedla P S , et al.Resume2Vec: Transforming Applicant Tracking Systems with Intelligent Resume Embeddings for Precise Candidate Matching[J].Electronics,2025,14(4):794-794.
- Helena L P ,Rita P ,Patricia V .What is in your résumé? The effects of multiple social categories in résumé screening[J].Personnel Review,2024,53(5):1331-1358.
- 张翔洲.基于自然语言处理的在线招聘管理系统[J].长江信息通信,2024,37(04):130-132.DOI:10.20153/j.issn.2096-9759.2024.04.039.
- 李双倾.招聘简历筛选中基于性别的差别化评价干预研究[D].北京外国语大学,2023.DOI:10.26962/d.cnki.gbjwu.2023.000213.
- 杨玫,吕振华,陈微微.基于人工智能的招聘面试管理系统设计[J].微型电脑应用,2021,37(07):100-103.
- 严景.人工智能中的算法歧视与应对——以某公司人工智能简历筛选系统性别歧视为视角[J].法制博览,2019,(14):127-128.
- 李中旗.基于内容推荐的企业招聘系统的设计与实现[D].河南大学,2018.
简历筛选系统的设计与实现工作业已圆满结束,尽管在过程中遭遇了诸多挑战,但内心却充满了成就感和满足感。在此,我要向大学四年间所有指导和教育我的教师们表达最诚挚的感谢,他们的专业知识和人生智慧对我成长为一名能独立完成系统的开发者起到了至关重要的作用。特别要感谢我的指导教师,他以极大的耐心解答我的疑惑,并引导我解决遇到的问题,从而提升了我的自主解决问题的能力。同时,我也要感谢我的室友和同学们,他们提出的宝贵建议和支持对我取得显著进步起到了不可或缺的作用。展望未来,我将继续不懈追求卓越,以期不辜负所学所悟以及教师们的殷切期望。坚信通过坚定的信念和持续的努力,未来必将取得更加辉煌的成就。我满怀期待地迎接更加美好的未来!
简历筛选系统的设计与实现不仅是一次技术上的挑战,而且在面对挫折和困难时,它们成为了我成长的垫脚石,使我能够更深入地理解问题,并精确地找到解决方案。每一次成功解决问题,都让我感到莫大的满足和自豪。
对于未来,我满怀期待和信心。无论前路如何崎岖,只要我保持坚定的信念并持续努力,相信必将取得更大的成就。我期待将所学的知识和技能应用于实践,为社会做出更大的贡献。
最后,我要向所有帮助和支持我的人表达最深的感激之情。你们的教诲、鼓励和支持是我取得今日成就的重要因素。我将继续努力,不辜负大家的期望,为实现更加美好的未来而不懈奋斗。
登录代码如下:
def Login(self, ctx):
print("===================登录=====================")
ret = {
"error": {
"code": 70000,
"message": "账户不存在",
}
}
body = ctx.body
password = md5hash(body["password"]) or ""
obj = service_select("user").Get_obj(
{"username": body["username"]}, {"like": False}
)
if obj:
user_group = service_select("user_group").Get_obj({'name': obj['user_group']}, {"like": False})
if user_group and user_group['source_table'] != '':
user_obj = service_select(user_group['source_table']).Get_obj({"user_id": obj['user_id']}, {"like": False})
if user_obj['examine_state'] == '未通过':
ret = {
"error": {
"code": 70000,
"message": "账户未通过审核",
}
}
return ret
if user_obj['examine_state'] == '未审核':
ret = {
"error": {
"code": 70000,
"message": "账户未审核",
}
}
return ret
if obj["state"] == 1:
if obj["password"] == password:
timeout = timezone.now()
timestamp = int(time.mktime(timeout.timetuple())) * 1000
token = md5hash(str(obj["user_id"]) + "_" + str(timestamp))
ctx.request.session[token] = obj["user_id"]
service_select("access_token").Add(
{"token": token, "user_id": obj["user_id"]}
)
obj["token"] = token
ret = {
"result": {"obj": obj}
}
else:
ret = {
"error": {
"code": 70000,
"message": "密码错误",
}
}
else:
ret = {
"error": {
"code": 70000,
"message": "用户账户不可用,请联系管理员",
}
}
return ctx.response(json.dumps(ret, ensure_ascii=False))
注册代码如下:
def Register(self, ctx):
print("===================注册=====================")
userService = service_select("user")
body = ctx.body
if "username" not in body and body["username"] == '':
return ctx.response(json.dumps({
"error": {
"code": 70000,
"message": "用户名不能为空",
}
}, ensure_ascii=False))
if "user_group" not in body and body["user_group"] == '':
return ctx.response(json.dumps({
"error": {
"code": 70000,
"message": "用户组不能为空",
}
}, ensure_ascii=False))
if "password" not in body and body["password"] == '':
return ctx.response(json.dumps({
"error": {
"code": 70000,
"message": "密码不能为空",
}
}, ensure_ascii=False))
post_param = body
post_param['nickname'] = body["nickname"] or ""
post_param['password'] = md5hash(body["password"])
obj = userService.Get_obj({"username": post_param['username']}, {"like": False})
if obj:
return ctx.response(json.dumps({
"error": {
"code": 70000,
"message": "用户名已存在",
}
}, ensure_ascii=False))
ret = {
"error": {
"code": 70000,
"message": "注册失败",
}
}
bl = userService.Add(post_param)
if bl:
ret = {
"result": {
"bl": True,
"message": "注册成功"
}
}
return ctx.response(json.dumps(ret, ensure_ascii=False))
找回密码代码如下:
def Forget_password(self, ctx):
print("===================修改密码=====================")
ret = {
"error": {
"code": 70000,
"message": "用户信息不能没有"
}
}
body = ctx.body
if not body["code"]:
return {
"error": {
"code": 70000,
"message": "验证码不存在或者错误"
}
}
obj = service_select("user").Get_obj(
{"username": body["username"]}, {"like": False}
)
if not obj:
return {
"error": {
"code": 70000,
"message": "用户名不存在或者错误"
}
}
password = md5hash(body["password"])
if not password:
return {
"error": {
"code": 70000,
"message": "密码不存在或者错误"
}
}
bl = service_select("user").Set({"user_id": obj["user_id"]}, {"password": password})
if bl:
ret = {"result": {"bl": True, "message": "修改成功"}}
else:
ret = {
"error": {
"code": 70000,
"message": "修改失败",
}
}
return ctx.response(json.dumps(ret, ensure_ascii=False))
修改密码代码如下:
def Change_password(self, ctx):
print("===================修改密码=====================")
ret = {
"error": {
"code": 70000,
"message": "账号未登录",
}
}
request = ctx.request
headers = request.headers
if ("x-auth-token" in headers) and headers["x-auth-token"]:
token = headers["x-auth-token"]
user_id = tokenGetUserId(token, request)
userService = service_select("user")
body = ctx.body
password = md5hash(body["o_password"])
obj = userService.Get_obj({"user_id": user_id, "password": password}, {"like": False})
if obj:
password = md5hash(body["password"])
bl = userService.Set({"user_id": user_id}, {"password": password})
if bl:
ret = {"result": {"bl": True, "message": "修改成功"}}
else:
ret = {
"error": {
"code": 70000,
"message": "修改失败",
}
}
else:
ret = {
"error": {
"code": 70000,
"message": "密码错误",
}
}
else:
ret = {
"error": {
"code": 70000,
"message": "账户未登录",
}
}
return ctx.response(json.dumps(ret, ensure_ascii=False))
增删查改代码如下:
增
def Add(self, ctx):
body = ctx.body
unique = self.config.get("unique")
obj = None
if unique:
qy = {}
for i in range(len(unique)):
key = unique[i]
qy[key] = body.get(key)
obj = self.service.Get_obj(qy)
if not obj:
error = self.Add_before(ctx)
if error["code"]:
return {"error": error}
error = self.Events("add_before", ctx, None)
if error["code"]:
return {"error": error}
result = self.service.Add(body, self.config)
if self.service.error:
return {"error": self.service.error}
res = self.Add_after(ctx, result)
if res:
result = res
res = self.Events("add_after", ctx, result)
if res:
result = res
return {"result": result}
else:
return {"error": {"code": 10000, "message": "已存在"}}
删
def Del(self, ctx):
if len(ctx.query) == 0:
errorMsg = {"code": 30000, "message": "删除条件不能为空!"}
return errorMsg
result = self.service.Del(ctx.query, self.config)
if self.service.error:
return {"error": self.service.error}
return {"result": result}
改
def Set(self, ctx):
error = self.Set_before(ctx)
if error["code"]:
return {"error": error}
error = self.Events("set_before", ctx, None)
if error["code"]:
return {"error": error}
query = ctx.query
if 'page' in query.keys():
del ctx.query['page']
if 'size' in query.keys():
del ctx.query['size']
if 'orderby' in query.keys():
del ctx.query['orderby']
result = self.service.Set(ctx.query, ctx.body, self.config)
if self.service.error:
return {"error": self.service.error}
res = self.Set_after(ctx, result)
if res:
result = res
res = self.Events("set_after", ctx, result)
if res:
result = res
return {"result": result}
查多条数据:
def Get_list(self, ctx):
query = dict(ctx.query)
config_plus = {}
if "field" in query:
field = query.pop("field")
config_plus["field"] = field
if "page" in query:
config_plus["page"] = query.pop("page")
if "size" in query:
config_plus["size"] = query.pop("size")
if "orderby" in query:
config_plus["orderby"] = query.pop("orderby")
if "like" in query:
config_plus["like"] = query.pop("like")
if "groupby" in query:
config_plus["groupby"] = query.pop("groupby")
count = self.service.Count(query)
lst = []
if self.service.error:
return {"error": self.service.error}
elif count:
lst = self.service.Get_list(query,
obj_update(self.config, config_plus))
if self.service.error:
return {"error": self.service.error}
self.interact_list(ctx, lst)
return {"result": {"list": lst, "count": count}}
查一条数据:
def Get_obj(self, ctx):
query = dict(ctx.query)
config_plus = {}
if "field" in query:
field = query.pop("field")
config_plus["field"] = field
obj = self.service.Get_obj(query, obj_update(self.config, config_plus))
if self.service.error:
return {"error": self.service.error}
if obj:
self.interact_obj(ctx, obj)
return {"result": {"obj": obj}}
免费领取项目源码,请关注❥点赞收藏并私信博主,谢谢~


















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









