




这里写目录标题
一、DBB(Diverse Branch Block)
DBB论文地址:Diverse Branch Block: Building a Convolution as an Inception-like Unit
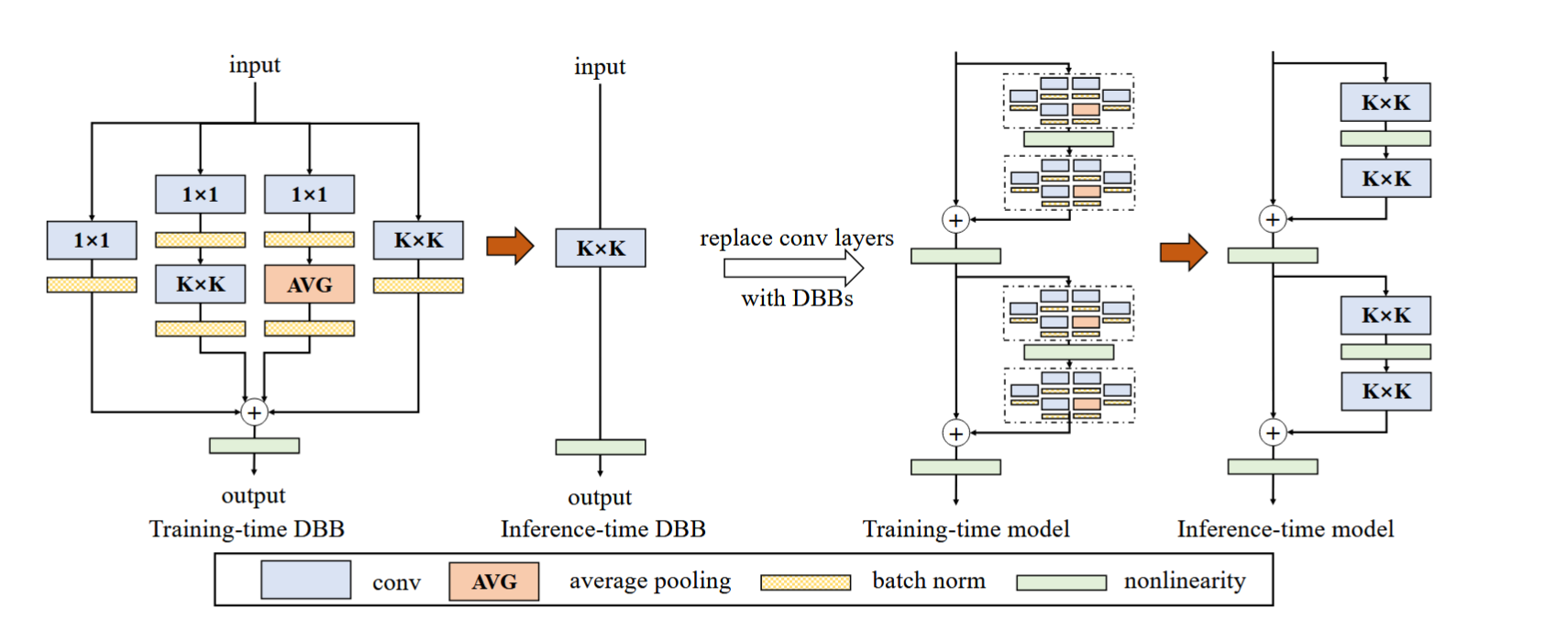
DBB思想源自RepVGG,DBB的价值
- 训练时增强表示能力:通过多分支结构融合不同尺度和类型的特征,提升模型精度
- 推理时保持高效:重参数化后等价于单一卷积层,无额外计算开销
- 通用性强:可作为即插即用模块集成到各类网络,无需修改整体架构
- 硬件友好:部署后结构简单,兼容现有卷积优化库(如cuDNN),适合实际应用
二、C3k2结构与改进
C3k2块的结构和代码

基础的残差块Bottleneck代码:
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
C2f块中的self.m属性调用了Bottleneck块
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
C3类的self.m属性也调用的Bottleneck
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
C3k类继承自C3
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
C3k2类在self.m属性中,调用了C3k类。并且C3k2块继承自C2f类,重写了self.m属性。
通过C3k2d类的构造函数的c3k参数,控制块的结构,如果为True,将C2f块中的Bottleneck改为了C3k,如果为False,就是C2f。
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
对于C3k2块的三种改进方法
- 换Bottleneck中的conv:
如C3k2_DBB - 换整个Bottleneck:
如C3k2_Faster - 加注意力机制
如C3k2_FocusedLinearAttention,在Bottleneck的CBS和Add之间加Attention。

三、改进具体实现步骤(含源码)
简单来说,就是把C3k2块的所有普通卷积的CBS层(Conv类)换成Diverse Branch Block(多样化分支块)即DBB,
涉及yolo项目的模块注册的方法,可参考文章超级小白,一篇教你如何在Yolo11中添加自定义module!!!
改进的项目修改步骤如下:
在ultralytics/nn/extra_modules/下建立rep_block.py文件

再rep_block.py中复制入以下DiverseBranchBlock相关代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from ..modules.conv import Conv, autopad
__all__ = ['DiverseBranchBlock', 'WideDiverseBranchBlock', 'DeepDiverseBranchBlock']
def transI_fusebn(kernel, bn):
gamma = bn.weight
std = (bn.running_var + bn.eps).sqrt()
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def transII_addbranch(kernels, biases):
return sum(kernels), sum(biases)
def transIII_1x1_kxk(k1, b1, k2, b2, groups):
if groups == 1:
k = F.conv2d(k2, k1.permute(1, 0, 2, 3)) #
b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))
else:
k_slices = []
b_slices = []
k1_T = k1.permute(1, 0, 2, 3)
k1_group_width = k1.size(0) // groups
k2_group_width = k2.size(0) // groups
for g in range(groups):
k1_T_slice = k1_T[:, g*k1_group_width:(g+1)*k1_group_width, :, :]
k2_slice = k2[g*k2_group_width:(g+1)*k2_group_width, :, :, :]
k_slices.append(F.conv2d(k2_slice, k1_T_slice))
b_slices.append((k2_slice * b1[g*k1_group_width:(g+1)*k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))
k, b_hat = transIV_depthconcat(k_slices, b_slices)
return k, b_hat + b2
def transIV_depthconcat(kernels, biases):
return torch.cat(kernels, dim=0), torch.cat(biases)
def transV_avg(channels, kernel_size, groups):
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
# This has not been tested with non-square kernels (kernel.size(2) != kernel.size(3)) nor even-size kernels
def transVI_multiscale(kernel, target_kernel_size):
H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2
W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2
return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
padding_mode='zeros'):
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups,
bias=False, padding_mode=padding_mode)
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True)
se = nn.Sequential()
se.add_module('conv', conv_layer)
se.add_module('bn', bn_layer)
return se
class IdentityBasedConv1x1(nn.Module):
def __init__(self, channels, groups=1):
super().__init__()
assert channels % groups == 0
input_dim = channels // groups
self.conv = nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=1, groups=groups, bias=False)
id_value = np.zeros((channels, input_dim, 1, 1))
for i in range(channels):
id_value[i, i % input_dim, 0, 0] = 1
self.id_tensor = torch.from_numpy(id_value)
nn.init.zeros_(self.conv.weight)
self.groups = groups
def forward(self, input):
kernel = self.conv.weight + self.id_tensor.to(self.conv.weight.device).type_as(self.conv.weight)
result = F.conv2d(input, kernel, None, stride=1, groups=self.groups)
return result
def get_actual_kernel(self):
return self.conv.weight + self.id_tensor.to(self.conv.weight.device).type_as(self.conv.weight)
class BNAndPadLayer(nn.Module):
def __init__(self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(self.bn.running_var + self.bn.eps)
else:
pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0:self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels:, :] = pad_values
output[:, :, :, 0:self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels:] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class DiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=None, dilation=1, groups=1,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy
self.nonlinear = Conv.default_act
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
if padding is None:
padding = autopad(kernel_size, padding, dilation)
assert padding == kernel_size // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=groups, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=0, groups=groups)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1', nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,
kernel_size=1, stride=1, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3, affine=True))
self.dbb_1x1_kxk.add_module('conv2', nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.
if single_init:
# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.
self.single_init()
def get_equivalent_kernel_bias(self):
k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second, b_1x1_kxk_second, groups=self.groups)
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device), self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second, b_1x1_avg_second, groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
return transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged), (b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))
def switch_to_deploy(self):
if hasattr(self, 'dbb_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.conv.in_channels, out_channels=self.dbb_origin.conv.out_channels,
kernel_size=self.dbb_origin.conv.kernel_size, stride=self.dbb_origin.conv.stride,
padding=self.dbb_origin.conv.padding, dilation=self.dbb_origin.conv.dilation, groups=self.dbb_origin.conv.groups, bias=True)
self.dbb_reparam.weight.data = kernel
self.dbb_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('dbb_origin')
self.__delattr__('dbb_avg')
if hasattr(self, 'dbb_1x1'):
self.__delattr__('dbb_1x1')
self.__delattr__('dbb_1x1_kxk')
def forward(self, inputs):
if hasattr(self, 'dbb_reparam'):
return self.nonlinear(self.dbb_reparam(inputs))
out = self.dbb_origin(inputs)
if hasattr(self, 'dbb_1x1'):
out += self.dbb_1x1(inputs)
out += self.dbb_avg(inputs)
out += self.dbb_1x1_kxk(inputs)
return self.nonlinear(out)
def init_gamma(self, gamma_value):
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, gamma_value)
if hasattr(self, "dbb_1x1"):
torch.nn.init.constant_(self.dbb_1x1.bn.weight, gamma_value)
if hasattr(self, "dbb_avg"):
torch.nn.init.constant_(self.dbb_avg.avgbn.weight, gamma_value)
if hasattr(self, "dbb_1x1_kxk"):
torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight, gamma_value)
def single_init(self):
self.init_gamma(0.0)
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)
class DiverseBranchBlockNOAct(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=None, dilation=1, groups=1,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False):
super(DiverseBranchBlockNOAct, self).__init__()
self.deploy = deploy
# self.nonlinear = Conv.default_act
self.kernel_size = kernel_size
self.out_channels = out_channels
self.groups = groups
if padding is None:
# padding=None
padding = autopad(kernel_size, padding, dilation)
assert padding == kernel_size // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=groups, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=0, groups=groups)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1',
nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,
kernel_size=1, stride=1, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3,
affine=True))
self.dbb_1x1_kxk.add_module('conv2',
nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0, groups=groups,
bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.
if single_init:
# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.
self.single_init()
def get_equivalent_kernel_bias(self):
k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second,
b_1x1_kxk_second, groups=self.groups)
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device),
self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second,
b_1x1_avg_second, groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
return transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged),
(b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))
def switch_to_deploy(self):
if hasattr(self, 'dbb_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.conv.in_channels,
out_channels=self.dbb_origin.conv.out_channels,
kernel_size=self.dbb_origin.conv.kernel_size, stride=self.dbb_origin.conv.stride,
padding=self.dbb_origin.conv.padding, dilation=self.dbb_origin.conv.dilation,
groups=self.dbb_origin.conv.groups, bias=True)
self.dbb_reparam.weight.data = kernel
self.dbb_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('dbb_origin')
self.__delattr__('dbb_avg')
if hasattr(self, 'dbb_1x1'):
self.__delattr__('dbb_1x1')
self.__delattr__('dbb_1x1_kxk')
def forward(self, inputs):
if hasattr(self, 'dbb_reparam'):
# return self.nonlinear(self.dbb_reparam(inputs))
return self.dbb_reparam(inputs)
out = self.dbb_origin(inputs)
# print(inputs.shape)
# print(self.dbb_1x1(inputs).shape)
if hasattr(self, 'dbb_1x1'):
out += self.dbb_1x1(inputs)
out += self.dbb_avg(inputs)
out += self.dbb_1x1_kxk(inputs)
# return self.nonlinear(out)
return out
def init_gamma(self, gamma_value):
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, gamma_value)
if hasattr(self, "dbb_1x1"):
torch.nn.init.constant_(self.dbb_1x1.bn.weight, gamma_value)
if hasattr(self, "dbb_avg"):
torch.nn.init.constant_(self.dbb_avg.avgbn.weight, gamma_value)
if hasattr(self, "dbb_1x1_kxk"):
torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight, gamma_value)
def single_init(self):
self.init_gamma(0.0)
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)
@property
def weight(self): ##含有@property
if hasattr(self, 'dbb_reparam'):
# return self.nonlinear(self.dbb_reparam(inputs))
return self.dbb_reparam.weight
class DeepDiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=None, dilation=1, groups=1,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False,conv_orgin=DiverseBranchBlockNOAct):
super(DeepDiverseBranchBlock, self).__init__()
self.deploy = deploy
self.nonlinear = Conv.default_act
self.kernel_size = kernel_size
self.out_channels = out_channels
self.groups = groups
# padding=0
if padding is None:
padding = autopad(kernel_size, padding, dilation)
assert padding == kernel_size // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.dbb_origin = DiverseBranchBlockNOAct(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=groups, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=0, groups=groups)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1',
nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,
kernel_size=1, stride=1, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3,
affine=True))
self.dbb_1x1_kxk.add_module('conv2',
nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0, groups=groups,
bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.
if single_init:
# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.
self.single_init()
def get_equivalent_kernel_bias(self):
self.dbb_origin.switch_to_deploy()
# k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.dbb_reparam.weight, self.dbb_origin.bn)
k_origin, b_origin = self.dbb_origin.dbb_reparam.weight, self.dbb_origin.dbb_reparam.bias
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second,
b_1x1_kxk_second, groups=self.groups)
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device),
self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second,
b_1x1_avg_second, groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
return transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged),
(b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))
def switch_to_deploy(self):
if hasattr(self, 'dbb_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.dbb_reparam.in_channels,
out_channels=self.dbb_origin.dbb_reparam.out_channels,
kernel_size=self.dbb_origin.dbb_reparam.kernel_size, stride=self.dbb_origin.dbb_reparam.stride,
padding=self.dbb_origin.dbb_reparam.padding, dilation=self.dbb_origin.dbb_reparam.dilation,
groups=self.dbb_origin.dbb_reparam.groups, bias=True)
self.dbb_reparam.weight.data = kernel
self.dbb_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('dbb_origin')
self.__delattr__('dbb_avg')
if hasattr(self, 'dbb_1x1'):
self.__delattr__('dbb_1x1')
self.__delattr__('dbb_1x1_kxk')
def forward(self, inputs):
if hasattr(self, 'dbb_reparam'):
return self.nonlinear(self.dbb_reparam(inputs))
# return self.dbb_reparam(inputs)
out = self.dbb_origin(inputs)
if hasattr(self, 'dbb_1x1'):
out += self.dbb_1x1(inputs)
out += self.dbb_avg(inputs)
out += self.dbb_1x1_kxk(inputs)
return self.nonlinear(out)
# return out
def init_gamma(self, gamma_value):
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, gamma_value)
if hasattr(self, "dbb_1x1"):
torch.nn.init.constant_(self.dbb_1x1.bn.weight, gamma_value)
if hasattr(self, "dbb_avg"):
torch.nn.init.constant_(self.dbb_avg.avgbn.weight, gamma_value)
if hasattr(self, "dbb_1x1_kxk"):
torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight, gamma_value)
def single_init(self):
self.init_gamma(0.0)
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)
class WideDiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=None, dilation=1, groups=1,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False):
super(WideDiverseBranchBlock, self).__init__()
self.deploy = deploy
self.nonlinear = Conv.default_act
self.kernel_size = kernel_size
self.out_channels = out_channels
self.groups = groups
if padding is None:
padding = autopad(kernel_size, padding, dilation)
assert padding == kernel_size // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=groups, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=0, groups=groups)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1',
nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,
kernel_size=1, stride=1, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3,
affine=True))
self.dbb_1x1_kxk.add_module('conv2',
nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0, groups=groups,
bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.
if single_init:
# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.
self.single_init()
if padding - kernel_size // 2 >= 0:
self.crop = 0
hor_padding = [padding - kernel_size // 2, padding]
ver_padding = [padding, padding - kernel_size // 2]
else:
self.crop = kernel_size // 2 - padding
hor_padding = [0, padding]
ver_padding = [padding, 0]
# Vertical convolution(3x1) during training
self.ver_conv = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=(kernel_size, 1),
stride=stride,
padding=ver_padding,
dilation=dilation,
groups=groups,
bias=False,
)
# Horizontal convolution(1x3) during training
self.hor_conv = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=(1, kernel_size),
stride=stride,
padding=hor_padding,
dilation=dilation,
groups=groups,
bias=False,
)
# Batch normalization for vertical convolution
self.ver_bn = nn.BatchNorm2d(num_features=out_channels,
affine=True)
# Batch normalization for horizontal convolution
self.hor_bn = nn.BatchNorm2d(num_features=out_channels,
affine=True)
def _add_to_square_kernel(self, square_kernel, asym_kernel):
'''
Used to add an asymmetric kernel to the center of a square kernel
square_kernel : the square kernel to which the asymmetric kernel will be added
asym_kernel : the asymmetric kernel that will be added to the square kernel
'''
# Get the height and width of the asymmetric kernel
asym_h = asym_kernel.size(2)
asym_w = asym_kernel.size(3)
# Get the height and width of the square kernel
square_h = square_kernel.size(2)
square_w = square_kernel.size(3)
# Add the asymmetric kernel to the center of the square kernel
square_kernel[:,
:,
square_h // 2 - asym_h // 2: square_h // 2 - asym_h // 2 + asym_h,
square_w // 2 - asym_w // 2: square_w // 2 - asym_w // 2 + asym_w] += asym_kernel
def get_equivalent_kernel_bias_1xk_kx1_kxk(self):
'''
Used to calculate the equivalent kernel and bias of
the fused convolution layer in deploy mode
'''
# Fuse batch normalization with convolutional weights and biases
hor_k, hor_b = transI_fusebn(self.hor_conv.weight, self.hor_bn)
ver_k, ver_b = transI_fusebn(self.ver_conv.weight, self.ver_bn)
square_k, square_b = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
# Add the fused horizontal and vertical kernels to the center of the square kernel
self._add_to_square_kernel(square_k, hor_k)
self._add_to_square_kernel(square_k, ver_k)
# Return the square kernel and the sum of the biases for the three convolutional layers
return square_k, hor_b + ver_b + square_b
def get_equivalent_kernel_bias(self):
# k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
k_origin, b_origin = self.get_equivalent_kernel_bias_1xk_kx1_kxk()
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1407
1407




 到【灌水乐园】发言
到【灌水乐园】发言







